Data Visualization: criando gráficos com bibliotecas Python
Conhecendo a biblioteca Matplotlib - Apresentação
Olá! A instrutora Valquíria Alencar vai nos acompanhar nesse curso de visualização de dados para quem quer criar gráficos com a linguagem de programação Python.
Valquíria Alencar é uma mulher branca de olhos castanhos. Tem cabelos loiros e lisos abaixo dos ombros. Usa piercing no septo e uma blusa preta. Ao fundo, estúdio com iluminação azulada. À direita, uma vaso de planta e, à esquerda, uma estante com decorações.
Neste curso, vamos trabalhar como cientistas de dados de uma empresa que presta um serviço de consultoria para pessoas que querem imigrar do Brasil para o Canadá.
Ao longo das aulas, vamos desenvolver um projeto para que essa empresa possa otimizar esses serviços de aconselhamento e consultoria para essas pessoas que desejam fazer imigração.
Com esse projeto, vamos aprender:
- Plotar gráficos;
- Adicionar títulos e rótulos nos eixos;
- Criar figuras e, inclusive, com mais de um gráfico na mesma imagem (subplots);
- Customizar figuras, alterando posição de títulos, tamanho das fontes, cores e até adicionando anotações;
- Salvar visualizações obtidas em formatos variados para conseguir utilizá-las em relatórios e apresentações;
- Criar gráficos interativos.
Vamos explorar todos esses conteúdos com três bibliotecas Python:
- Matplotlib;
- Seaborn;
- Plotly.
No entanto, esse curso não vai abordar todos os tipos de gráficos que podemos fazer com essas três bibliotecas.
Para que você tenha um maior aproveitamento do curso, recomendamos que você tenha conhecimentos prévios em Python e na biblioteca Pandas.
Vamos começar?
Conhecendo a biblioteca Matplotlib - Conhecendo os dados
Uma empresa que presta serviços de consultoria e aconselhamento para pessoas que querem migrar do Brasil para o Canadá deseja melhorar os seus serviços. Para isso, temos alguns arquivos que foram disponibilizados para fazer uma análise das tendências de imigração do Brasil dos últimos anos.
Entre esses arquivos, há um arquivo CSV chamado "imigrantes-canada" que contém informações de todos os países com os números aproximados de imigrantes para o Canadá para cada um dos anos desde 1980. Vamos trabalhar com esse arquivo que está disponibilizado na atividade "Preparando o Ambiente".
No decorrer das aulas, vamos desenvolver algumas tarefas com base nesse dataset e utilizar bibliotecas de visualização de dados para obter alguns insights e entender as tendências de imigração.
Importação de dados
Para começar, vamos importar a biblioteca Pandas. Na primeira célula de código do Google Colab, vamos importar pandas com o apelido pd:
import pandas as pdApós executar a célula, precisamos dos arquivos. Por isso, vamos ao menu vertical à esquerda e clicar na opção "Arquivos". Depois, vamos clicar no primeiro ícone do menu superior para "Fazer upload para o armazenamento da sessão" e selecionar o arquivo imigrantes-canada.csv.
Após fazer o upload, vamos copiar o caminho desse arquivo ao clicar no ícone de três pontos e escolher a opção "Copiar caminho".
Agora, em uma nova célula, vamos criar uma variável chamada df para armazenar esse dataframe que vamos gerar. Por isso, digitamos df igual à pd.read_csv() para fazer a leitura do arquivo. Entre os parênteses, colamos o caminho do arquivo e executamos a célula.
df = pd.read_csv('/content/imigrantes_canada.csv')Para entender os nossos dados, vamos visualizar esse dataframe:
df| # | País | Continente | Região | 1980 | 1981 | 1982 | 1983 | 1984 | 1985 | 1986 | … | 2005 | 2006 | 2007 | 2008 | 2009 | 2010 | 2011 | 2012 | 2013 | Total |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Afeganistão | Ásia | Sul da Ásia | 16 | 39 | 39 | 47 | 71 | 340 | 496 | … | 3436 | 3009 | 2652 | 2111 | 1746 | 1758 | 2203 | 2635 | 2004 | 58639 |
| 1 | Albânia | Europa | Sul da Europa | 1 | 0 | 0 | 0 | 0 | 0 | 1 | … | 1223 | 856 | 702 | 560 | 716 | 561 | 539 | 620 | 603 | 15699 |
| 2 | Argélia | África | Norte da África | 80 | 67 | 71 | 69 | 63 | 44 | 69 | … | 3626 | 4807 | 3623 | 4005 | 5393 | 4752 | 4325 | 3774 | 4331 | 69439 |
| … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … |
| 192 | Iémen | Ásia | Ásia Ocidental | 1 | 2 | 1 | 6 | 0 | 18 | 7 | … | 161 | 140 | 122 | 133 | 128 | 211 | 160 | 174 | 217 | 2985 |
| 193 | Zâmbia | África | África Oriental | 11 | 17 | 11 | 7 | 16 | 9 | 15 | … | 91 | 77 | 71 | 64 | 60 | 102 | 69 | 46 | 59 | 1677 |
| 194 | Zimbábue | África | África Oriental | 72 | 114 | 102 | 44 | 32 | 29 | 43 | … | 615 | 454 | 663 | 611 | 508 | 494 | 434 | 437 | 407 | 8598 |
Agora temos o dataframe com o país, continente, região e várias colunas com os anos desde 1980 até 2013, com o número de imigrantes para cada um desses países. Também temos uma coluna com o valor total.
Ao final do dataframe, conseguimos descobrir que temos 195 linhas e 38 colunas.
Para obter algumas informações mais detalhadas, podemos usar o método info.
df.info()| # | Column | Non-Null Count | Dtype |
|---|---|---|---|
| 0 | País | 195 non-null | object |
| 1 | Continente | 195 non-null | object |
| 2 | Região | 195 non-null | object |
| 3 | 1980 | 195 non-null | int64 |
| 4 | 1981 | 195 non-null | int64 |
| 5 | 1982 | 195 non-null | int64 |
| 6 | 1983 | 195 non-null | int64 |
| 7 | 1984 | 195 non-null | int64 |
| 8 | 1985 | 195 non-null | int64 |
| 9 | 1986 | 195 non-null | int64 |
| 10 | 1987 | 195 non-null | int64 |
| 11 | 1988 | 195 non-null | int64 |
| 12 | 1989 | 195 non-null | int64 |
| 13 | 1990 | 195 non-null | int64 |
| 14 | 1991 | 195 non-null | int64 |
| 15 | 1992 | 195 non-null | int64 |
| 16 | 1993 | 195 non-null | int64 |
| 17 | 1994 | 195 non-null | int64 |
| 18 | 1995 | 195 non-null | int64 |
| 19 | 1996 | 195 non-null | int64 |
| 20 | 1997 | 195 non-null | int64 |
| 21 | 1998 | 195 non-null | int64 |
| 22 | 1999 | 195 non-null | int64 |
| 23 | 2000 | 195 non-null | int64 |
| 24 | 2001 | 195 non-null | int64 |
| 25 | 2002 | 195 non-null | int64 |
| 26 | 2003 | 195 non-null | int64 |
| 27 | 2004 | 195 non-null | int64 |
| 28 | 2005 | 195 non-null | int64 |
| 29 | 2006 | 195 non-null | int64 |
| 30 | 2007 | 195 non-null | int64 |
| 31 | 2008 | 195 non-null | int64 |
| 32 | 2009 | 195 non-null | int64 |
| 33 | 2010 | 195 non-null | int64 |
| 34 | 2011 | 195 non-null | int64 |
| 35 | 2012 | 195 non-null | int64 |
| 36 | 2013 | 195 non-null | int64 |
| 37 | Total | 195 non-null | int64 |
Com isso, temos várias informações. Por exemplo, se temos dados nulos e quais são os tipos de dados.
Podemos verificar que as três primeiras colunas são do tipo objeto, ou seja, são strings e nas colunas seguintes temos apenas valores inteiros. Não temos dados nulos em nenhuma das colunas, o que é ótimo, pois não precisamos fazer nenhum tratamento de dados nulos ou mudar o tipo de dado.
Realização de tratamentos
Vamos começar com a primeira tarefa desse projeto que é: analisar as tendências de imigração do Brasil ao longo dos anos.
Para fazer isso, vamos alterar o index do nosso dataframe para ser o país. Assim, poderemos acessar só o Brasil e extrair informações desse país.
Na próxima célula de código, digitamos df.set_index() que é a função de mudar o índice. Entre parênteses e aspas, colocamos a coluna que queremos que seja o novo índice, País com a primeira letra em maiúscula.
O segundo parâmetro é o inplace igual à True. Desse modo, a alteração vai ser executada diretamente no dataframe df, sem a necessidade de criar um novo dataframe.
df.set_index('País', inplace=True)Após executar essa célula, vamos criar uma variável para armazenar o intervalo de tempo de 1980 até 2013. Isso irá facilitar muito na visualização dos dados.
Para isso, vamos criar a variável anos igual à lista com os intervalos de ano. Ou seja, usamos a função list() e, nela, colocamos a função map(), porque vamos pedir para que os valores fiquem em string. Desse modo, vamos ter os valores como objetos e não como números.
Dentro de map(), digitamos o primeiro parâmetro como str e o segundo parâmetro é o intervalo que queremos transformar em string, isto é, range(1980, 2014). Assim, começamos em 1980 que é o primeiro ano do dataframe e vamos até 2013, porque não consideramos o último valor.
anos = list(map(str, range(1980, 2014)))Para verificar a lista que acabamos de criar, podemos chamar a variável anos e executar.
anos['1980', '1981', '1982', '1983', '1984', '1985', '1986', '1987', '1988', '1989', '1990', '1991', '1992', '1993', '1994', '1995', '1996', '1997', '1998', '1999', '2000', '2001', '2002', '2003', '2004', '2005', '2006', '2007', '2008', '2009', '2010', '2011', '2012', '2013']
Temos uma lista indo desde 1980 até 2013, como queríamos.
Extração da série de dados para o Brasil
Agora, queremos pegar somente os dados do Brasil. Podemos usar a propriedade loc do Pandas para fazer isso, pois essa propriedade consegue pegar rótulos específicos dentro de um dataframe.
Em uma nova linha, criamos uma variável chamada brasil igual à df.loc[]. Entre colchetes, passamos o rótulo Brasil entre aspas. Além disso, queremos o intervalo dos anos de 1980 até 2013. Logo, também passamos a variável anos nos colchetes.
brasil = df.loc['Brasil', anos]Vamos verificar o que temos ao chamar a variável:
brasilTemos uma series com os anos de 1980 a 2013 na primeira coluna e o número de imigrantes na segunda. Podemos transformar esses dados em um dataframe. Para fazer essa conversão, vamos criar um dicionário onde daremos um nome para cada uma das colunas: ano e número de imigrantes.
Criamos a variável brasil_dict que vai ser igual ao dicionário com o nome das colunas. Para isso, colocamos entre chaves, a chave ano entre aspas e o valor brasil.index.tolist(). Desse modo, atribuímos os dados da primeira coluna armazenada na variável Brasil, transformando a series em uma lista com a função tolist().
O título na próximo coluna é a chave imigrantes entre aspas. Como valor colocamos brasil.values.tolist().
Na linha de baixo, vamos efetivamente criar o dataframe chamado dados_brasil que vai ser igual à pd.DataFrame(). Entre os parênteses, adicionamos o dicionário brasil_dict.
brasil_dict = {'ano': brasil.index.tolist(), 'imigrantes': brasil.values.tolist()}
dados_brasil = pd.DataFrame(brasil_dict)Após executar a célula, podemos verificar como ficou o dataframe:
dados_brasil| # | ano | imigrantes |
|---|---|---|
| 0 | 1980 | 211 |
| 1 | 1981 | 220 |
| 2 | 1982 | 192 |
| 3 | 1983 | 139 |
| 4 | 1984 | 145 |
| 5 | 1985 | 130 |
| 6 | 1986 | 205 |
| 7 | 1987 | 244 |
| 8 | 1988 | 394 |
| 9 | 1989 | 650 |
| 10 | 1990 | 650 |
| 11 | 1991 | 877 |
| 12 | 1992 | 1066 |
| 13 | 1993 | 866 |
| 14 | 1994 | 566 |
| 15 | 1995 | 572 |
| 16 | 1996 | 586 |
| 17 | 1997 | 591 |
| 18 | 1998 | 531 |
| 19 | 1999 | 626 |
| 20 | 2000 | 845 |
| 21 | 2001 | 847 |
| 22 | 2002 | 745 |
| 23 | 2003 | 839 |
| 24 | 2004 | 917 |
| 25 | 2005 | 969 |
| 26 | 2006 | 1181 |
| 27 | 2007 | 1746 |
| 28 | 2008 | 2138 |
| 29 | 2009 | 2509 |
| 30 | 2010 | 2598 |
| 31 | 2011 | 1508 |
| 32 | 2012 | 1642 |
| 33 | 2013 | 1714 |
Agora temos um dataframe que contém uma coluna com o ano e outra coluna com o número de imigrantes para cada um dos anos. Assim, temos os dados prontos agora para entender essas tendências de imigração do Brasil. Em breve, vamos criar o nosso primeiro gráfico.
Conhecendo a biblioteca Matplotlib - Criando o primeiro gráfico com Matplotlib
Já temos o dataframe que contém os dados apenas do Brasil com os anos e número de imigrantes para cada ano. Agora, vamos criar o nosso primeiro gráfico para entender as tendências de imigração do Brasil.
Para isso, vamos conhecer uma biblioteca famosa para visualização de dados em Pyhton: a biblioteca Matplotlib. Para criar gráficos, vamos utilizar o módulo pyplot específico dessa biblioteca.
Criação de gráfico com módulo pyplot
Primeiro, vamos fazer a importação do módulo. Em uma nova linha do Google Colab, escrevemos import matplotlib.pyplot e vamos apelidar esse módulo como plt. Podemos executar a célula.
import matplotlib.pyplot as pltCom esse módulo, podemos criar gráficos de forma simples e prática. Para começar, vamos usar uma função chamada plot(). Desse modo, é gerado automaticamente um gráfico de linhas.
Um gráfico de linha é indicado para o tipo de dados que temos, porque queremos visualizar uma variável de acordo com o tempo.
Na próxima célula de código, vamos digitar plt.plot() e passar dois argumentos.
Como primeiro argumento, precisamos colocar os dados que estarão no eixo horizontal do gráfico. No nosso caso, os anos. Para isso, vamos digitar o dataframe dados_brasil e, entre colchetes e aspas, colocamos a coluna ano.
Como segundo argumento, precisamos colocar os dados para o eixo vertical do gráfico. Ou seja, novamente colocamos dataframe dados_brasil e, entre colchetes e aspas, a coluna imigrantes.
plt.plot(dados_brasil['ano'], dados_brasil['imigrantes'])Ao executar esse código, vamos obter o nosso primeiro gráfico.
[<matplotlib.lines.Line2D at 0x7fae03a1b550>]
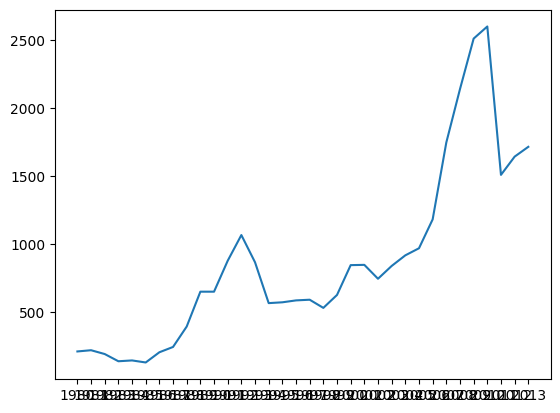
Agora, vamos entender o que é eixo e quais dados estão na horizontal e vertical.
O eixo horizontal é a linha reta na parte inferior onde temos vários valores de anos que estão sobrepostos. Mais adiante, vamos falar dessa sobreposição. Na vertical, temos os dados numéricos com a quantidade de imigrantes.
O eixo horizontal também é conhecido como eixo x, enquanto o eixo vertical é o eixo y.
Sempre que falamos de "eixo", nos referimos a essa linha na qual os dados são dispostos. No nosso caso, temos no eixo x uma variável independente, o ano. No eixo y, temos uma variável dependente, porque varia de acordo com o ano. Por exemplo, temos valores crescentes e decrescentes no gráfico.
Contudo, não conseguimos visualizar facilmente os anos do eixo x, pois estão sobrepostos por causa da quantidade de dados.
Como é possível consertar o eixo x para melhorar a leitura desses dados?
Melhora na visualização do gráfico
Escolhendo quais anos aparecerem no eixo x com plt.xticks
Vamos digitar na segunda linha do código plt.plot() usada para criar o gráfico. Queremos chamar a função xticks() que se refere as marcações do eixo x.
Para isso, colocamos plt.xticks() e passamos uma lista contendo strings com os valores que queremos que apareçam no eixo x. Vamos colocar de 5 em 5 anos para deixar a visualização mais agradável. Entre colchetes e aspas, digitamos 1980, 1985, 1990, 1995, 2000, 2005 e 2010.
Vamos executar a célula para conferir como ficaram as alterações no gráfico.
plt.plot(dados_brasil['ano'], dados_brasil['imigrantes'])
plt.xticks(['1980', '1985', '1990', '1995', '2000', '2005', '2010'])([<matplotlib.axis.XTick at 0x7fae010db160>, <matplotlib.axis.XTick at 0x7fae010db130>, <matplotlib.axis.XTick at 0x7fae0398feb0>, <matplotlib.axis.XTick at 0x7fae01098370>, <matplotlib.axis.XTick at 0x7fae01098e20>, <matplotlib.axis.XTick at 0x7fae0109d910>, <matplotlib.axis.XTick at 0x7fae010986a0>],
[Text(0.0, 0, '1980'), Text(5.0, 0, '1985'), Text(10.0, 0, '1990'), Text(15.0, 0, '1995'), Text(20.0, 0, '2000'), Text(25.0, 0, '2005'), Text(30.0, 0, '2010')])
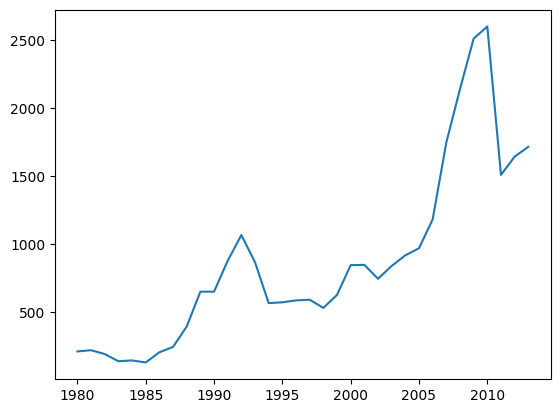
Ao colocar intervalos de 5 em 5 anos no eixo x, facilitou a leitura e é possível entender os dados.
Alterando as marcações do eixo y com plt.yticks
Além de adicionar os ticks no eixo x, também podemos alterar as marcações do eixo y. Para isso, vamos adicionar uma terceira linha no código de criação do gráfico.
Nessa linha, digitamos plt.yticks() para o eixo y. Entre os parênteses, adicionamos a lista os valores que queremos que apareçam no eixo vertical. Sem aspas, digitamos: 500, 1000, 1500, 2000, 2500 e um novo valor de 3000.
plt.plot(dados_brasil['ano'], dados_brasil['imigrantes'])
plt.xticks(['1980', '1985', '1990', '1995', '2000', '2005', '2010'])
plt.yticks([500, 1000, 1500, 2000, 2500, 3000])([<matplotlib.axis.YTick at 0x7fae010581c0>, <matplotlib.axis.YTick at 0x7fae01050b20>, <matplotlib.axis.YTick at 0x7fae01048b20>, <matplotlib.axis.YTick at 0x7fae01017d30>, <matplotlib.axis.YTick at 0x7fae01017f70>, <matplotlib.axis.YTick at 0x7fae0101d700>],
[Text(0, 500, '500'), Text(0, 1000, '1000'), Text(0, 1500, '1500'), Text(0, 2000, '2000'), Text(0, 2500, '2500'), Text(0, 3000, '3000')])
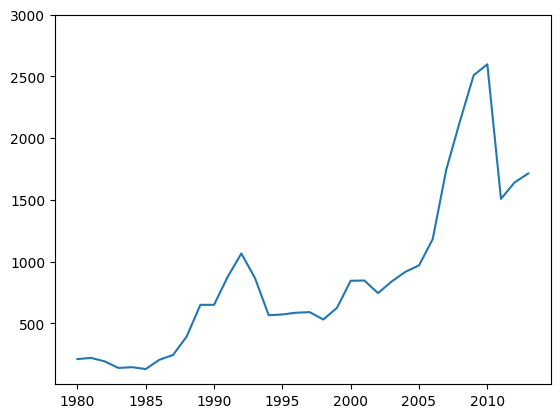
Desse modo, temos os dois eixos com valores alterados. Agora, o eixo y vai até 3000.
Exibindo gráfico com plt.show()
Essa alteração no eixo vertical não era necessária, só queríamos testar e entender como funciona. Por isso, podemos apagar a última linha de plt.yticks() e executar novamente para apontar um detalhe.
Vocês devem ter percebido que ao executar os códigos de plotagem, apareceram alguns textos em cima do gráfico:
([<matplotlib.axis.XTick at 0x7fae010db160>, <matplotlib.axis.XTick at 0x7fae010db130>, <matplotlib.axis.XTick at 0x7fae0398feb0>, <matplotlib.axis.XTick at 0x7fae01098370>, <matplotlib.axis.XTick at 0x7fae01098e20>, <matplotlib.axis.XTick at 0x7fae0109d910>, <matplotlib.axis.XTick at 0x7fae010986a0>],
[Text(0.0, 0, '1980'), Text(5.0, 0, '1985'), Text(10.0, 0, '1990'), Text(15.0, 0, '1995'), Text(20.0, 0, '2000'), Text(25.0, 0, '2005'), Text(30.0, 0, '2010')])
Nesse texto, temos várias informações como tipo de objeto, lugar em que estão armazenados na memória. Isso é comum quando criamos gráficos de plotagem no Python.
Mas, para esses dados não apareçam, podemos usar uma função do Matplotlib chamada show() que faz com que apenas o gráfico seja exibido.
Na próxima linha desse mesmo código, digitamos plt.show() e executar.
plt.plot(dados_brasil['ano'], dados_brasil['imigrantes'])
plt.xticks(['1980', '1985', '1990', '1995', '2000', '2005', '2010'])
plt.show()Agora é exibido somente o gráfico com os dados de imigração do Brasil. Todas aquelas informações antes do gráfico desapareceram.
Atenção: códigos escritos abaixo de
plt.show()não serão executados, pois o Python interrompe a execução dos códigos.
Sempre que você for usar o plt.show(), tenha certeza que seja a última linha do seu código.
Modificando o tamanho do gráfico com a função plt.figure()
Além disso, podemos mudar o tamanho de um gráfico. O tamanho normal é um quadrado, mas podemos fazer alterações.
Para isso, vamos utilizar uma outra função chamada figure() que vamos colocar na primeira linha do código de criação do gráfico.
Damos um "Enter" para saltar uma linha e colocamos plt.figure(). Com essa função, conseguimos modificar o tamanho ao usar o parâmetro figsize igual a parênteses que contém os valores em polegada da largura e altura do gráfico. Nesse caso, vamos testar os valores (8, 4).
plt.figure(figsize=(8,4))
plt.plot(dados_brasil['ano'], dados_brasil['imigrantes'])
plt.xticks(['1980', '1985', '1990', '1995', '2000', '2005', '2010'])
plt.show()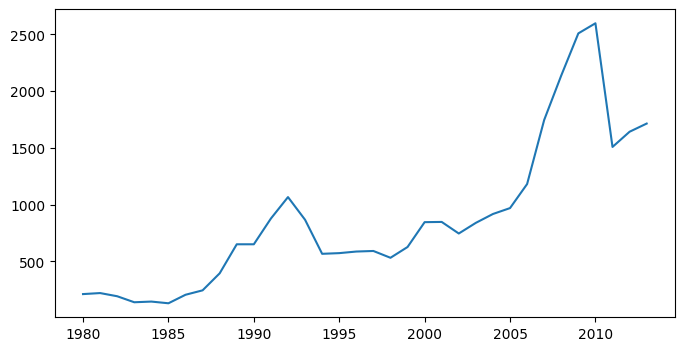
Agora, temos um gráfico com o tamanho modificado. Dessa forma, ele está mais largo, mas continua com os mesmos dados.
O nosso gráfico está praticamente finalizado, mas ainda falta um detalhe.
Um gráfico sempre precisa de um título e rótulos nos dois eixos.
Os rótulos são as informações do que temos no eixo x e no eixo y. Para quem está fazendo o gráfico essa informação é clara. Sabemos que temos o ano na horizontal, a quantidade de imigrantes na vertical e o gráfico é sobre a imigração do Brasil para o Canadá. Mas, como quem não tem familiaridade com os dados vai saber isso?
Por isso, vamos adicionar essas informações a seguir.
Sobre o curso Data Visualization: criando gráficos com bibliotecas Python
O curso Data Visualization: criando gráficos com bibliotecas Python possui 177 minutos de vídeos, em um total de 51 atividades. Gostou? Conheça nossos outros cursos de Data Science em Data Science, ou leia nossos artigos de Data Science.
Matricule-se e comece a estudar com a gente hoje! Conheça outros tópicos abordados durante o curso:
- Conhecendo a biblioteca Matplotlib
- Criando figuras com Matplotlib
- Customizando com Matplotlib
- Conhecendo a biblioteca Seaborn
- Gráficos interativos com Plotly