


De acordo com a pesquisa da McKinsey, 46% das empresas já usaram o Machine Learning em seus negócios.
O Machine Learning é um dos desdobramentos mais importantes da inteligência artificial (IA), que tem se mostrado fundamental em estratégias de negócios para aumentar a produtividade.
Não por menos, profissionais especialistas em modelos de Machine Learning (ML) ganham cada vez mais destaque no mercado de trabalho.
Isso tudo é suficiente para mostrar a necessidade de se preparar para trabalhar com essa tecnologia, não é mesmo?
Pensando nisso, o objetivo deste artigo é explorar o que é Machine Learning, especialmente sobre o que é e quais aplicações dessa tecnologia :)
O que é Machine Learning?
Machine Learning, ou Aprendizado de máquina, é um ramo da Inteligência Artificial que se concentra em criar sistemas que podem aprender a partir de dados.
Ao invés de serem programados com regras específicas para executar uma tarefa diretamente, esses sistemas são treinados usando dados e algoritmos que lhes permitem melhorar seu desempenho para realizar seu objetivo.
Em outras palavras, o Machine Learning permite que computadores aprendam com os dados, sem que precise explicitamente programar essa tarefa.
Isso contribui para a antecipação de cenários em diversas aplicações que vão desde a previsão do tempo até a detecção de fraudes em transações bancárias.

É possível aplicar o aprendizado de máquina em muitas áreas diferentes como, por exemplo, previsão de vendas, detecção de fraudes, recomendação de produtos, diagnóstico médico e daí por diante.
Isso se deve graças à grande quantidade de dados que armazenamos hoje em dia. Esses dados podem ser de vários tipos, como números, textos, imagens, vídeos e áudios.
Ou seja, basicamente, qualquer informação que possamos guardar no computador pode ser usada para treinar um algoritmo de aprendizado de máquina.

Como funciona o Machine Learning?
Dependendo da técnica de aprendizado de máquina, a aplicação do treinamento de um modelo é diferente. Mas conseguimos sintetizar esse processo utilizando de características que estão presentes em todos os métodos de aprendizagem de máquina.
De modo geral, o trabalho do aprendizado de máquina é buscar detectar vários padrões que estão presentes em um determinado conjunto de dados.
Para fazer isso, enviam-se dados iniciais a um algoritmo de Machine Learning, que executa o treinamento desse modelo para aprender a identificar os padrões nos dados.
Após o treinamento, é possível testar, avaliar, otimizar e colocar em produção, o modelo de Machine Learning, dependendo do objetivo da aplicação do modelo.
Como funciona o Machine Learning? | #AluraMais

O resultado de um modelo de aprendizado de máquina depende do tipo de algoritmo que se usa. Se for um algoritmo de classificação, que tem como objetivo identificar a qual categoria uma determinada amostra pertence, o modelo vai retornar a classe prevista para essa amostra.
Se for um algoritmo de regressão, que busca prever um valor numérico com base nas características da amostra, o modelo vai retornar um valor numérico.
Ou, se for um algoritmo de agrupamento, que tem como objetivo agrupar amostras semelhantes, o modelo vai retornar os grupos formados a partir das características das amostras.
História: como surgiu o Machine Learning?
Arthur Samuel é o programador pioneiro no campo da aprendizagem de máquina, principalmente porque desenvolveu o primeiro programa de aprendizado de máquina do mundo, além de ter cunhado, pela primeira vez, o termo “Machine Learning”.
Infelizmente, entre as décadas de 70 a 80 aconteceu o “Inverno da IA”, um período em que as pessoas demonstraram pouco interesse em pesquisar e investir no campo do ML ou IA.
O fim dessa era foi assinalado por muitos avanços envolvendo o desenvolvimento de algoritmos especialistas, como a NETtalk, em 1985, uma Rede Neural Artificial que aprendeu a pronunciar textos escritos em inglês, associando as palavras com suas fonéticas.
Ou um caso mais famoso, o Deep Blue, um algoritmo capaz de jogar xadrez e que, em 1997, venceu Garry Kasparov, campeão nesta modalidade da época.
O início da comercialização de máquinas virtuais pela Amazon com o Elastic Compute Cloud (Amazon EC2) marcou a década de 2000, que facilitaram a implementação de modelos de ML com maior necessidade de poder de processamento.
Isso possibilitou que estudos envolvendo dados e modelos mais complexos pudessem ser amplamente avançados para o que temos atualmente.
Para que servem os modelos de Machine Learning
Como você já sabe, é possível aplicar Machine Learning em diversas situações e áreas de atuação. As que mais se destacam são as seguintes:
- Previsão e Análise;
- Reconhecimento de padrões;
- Personalização de experiência;
- Classificação e Categorização;
- Otimização de processos;
- Diagnóstico Médico;
- Segurança Cibernética; e
- Prevenção de Manutenção.
1) Previsão e análise
Em setores como finanças e negócios, destaca-se a aplicação de machine learning para previsão e análise. Ou seja, algoritmos podem analisar históricos de mercado para prever tendências futuras.
Por exemplo, o treinamento de um modelo de machine learning com dados passados pode prever com precisão flutuações de preços de ações, auxiliando investidores na tomada de decisões sobre compra ou venda de ativos.
2) Reconhecimento de padrões
Uma aplicação interessante com reconhecimento de padrões é em visão computacional, como em sistemas de reconhecimento facial.
Por meio de algoritmos de machine learning, esses sistemas podem identificar padrões únicos na estrutura facial, permitindo a autenticação segura.
Nesse caso, as aplicações práticas incluem o desbloqueio de smartphones e sistemas de segurança que utilizam a biometria facial para autorização de acesso.
Além do exemplo anterior, é possível usar essa aplicação em diversas situações, desde o reconhecimento de voz até a detecção de fraudes em transações financeiras.
3) Personalização de experiência
Plataformas de streaming, como o Netflix, aplicam o machine learning para personalizar a experiência das pessoas usuárias.
Nesse caso, os algoritmos de machine learning analisam o histórico de visualizações, comportamentos e preferências das pessoas usuárias. Com base nessas informações, recomenda conteúdos personalizados.
O resultado disso é uma experiência muito mais envolvente e, provavelmente, muito mais satisfatória, a partir das sugestões. Case Adyen: Machine Learning e Pagamentos – Hipsters Ponto Tech #308
4) Classificação e categorização
Na área de e-mails, emprega-se o machine learning para classificar as mensagens de forma automática, como spam ou legítimas.
Usando algoritmos que identificam padrões nos textos e comportamentos associados a e-mails indesejados, os sistemas de classificação conseguem separar eficientemente as mensagens.
Assim, é possível garantir que as pessoas usuárias só receberão correspondências relevantes em suas caixas de entrada. A proposta de valor é a economia de tempo e o aumento da eficácia da comunicação eletrônica.
5) Otimização de processos
Na otimização de processos, aplica-se o machine learning em diversos setores, como logística e cadeia de suprimentos.
Os objetivos, nesses casos, são prever demandas futuras, reduzir estoques desnecessários e melhorar o fluxo de produção.
Por exemplo, empresas de entrega utilizam algoritmos de aprendizado de máquina para otimizar rotas de entrega, minimizando o tempo e os custos de transporte, resultando em maior eficiência operacional.
6) Diagnóstico médico
Na área da saúde, os algoritmos são treinados com grandes conjuntos de dados clínicos, como exames de imagem e dados laboratoriais, para auxiliar pessoas profissionais em medicina na identificação de doenças.
Um exemplo é o uso de redes neurais convolucionais (CNNs) em radiologia para analisar imagens de tomografia computadorizada e identificar anomalias, como tumores ou fraturas, com alta precisão, possibilitando intervenções mais rápidas e precisas.
7) Segurança cibernética
Em segurança cibernética, emprega-se o machine learning para detectar padrões de comportamento suspeitos em redes e sistemas.
Por exemplo, algoritmos de detecção de anomalias podem identificar atividades não usuais, como acessos não autorizados ou tentativas de intrusão, protegendo assim contra ataques cibernéticos.
Esses sistemas aprendem com dados históricos e em tempo real para antecipar e responder a ameaças de segurança, mantendo a integridade dos sistemas e dados corporativos.
8) Prevenção de manutenção
Na indústria, destaca-se a aplicação de machine learning na prevenção de manutenção como uma ferramenta valiosa para evitar falhas inesperadas em equipamentos.
Para isso, treinam-se os algoritmos com dados de desempenho e condições operacionais para prever quando uma máquina pode falhar.
Ao monitorar constantemente variáveis como temperatura, vibração e eficiência, os sistemas de machine learning podem antecipar a necessidade de manutenção, permitindo intervenções programadas antes que ocorram falhas.
Isso não apenas reduz os custos associados a paradas não programadas, mas também aumenta a vida útil dos equipamentos e melhora a eficiência operacional.
Casos de uso de ML no mundo real
Além dessas aplicações, existem muitas empresas que já se beneficiaram da aplicação de machine learning como solução de problemas em sua infraestrutura.
3 aplicações de Machine Learning onde você nem imagina com Thiago Santos | #HipstersPontoTube

Uma empresa de destaque é a Suzano, a maior produtora de celulose de eucalipto e referência global em uso sustentável de recursos naturais, que aplica uma cultura de aprendizagem e engajamento em Tech.
Entre os casos de sucesso da Suzano destacam-se:
Identificação de avarias nos fardos de celulose; e Otimização da estufagem de veículos.
Suzano: Identificação de avarias nos fardos de celulose
A Suzano, em busca de otimizar sua produção de celulose, lançou um projeto inovador: a detecção de avarias em fardos, visando reduzir perdas durante o processo.
Essa estratégia envolveu a aplicação de visão computacional e técnicas de Machine Learning, desenvolvidas pelo time de Manutenção e Confiabilidade da Unidade de Três Lagoas, no Mato Grosso do Sul.
Os participantes do projeto passaram por trilhas de aprendizagem da Alura Para Empresas, abordando temas como Machine Learning, Python básica, Python para Data Science e Visão computacional.
O objetivo principal era criar uma Inteligência Artificial capaz de identificar, em tempo real, avarias nos fardos de celulose durante a produção.
A solução, integrando o código em Python com o sistema de controle das linhas de enfardamento, proporcionou automação completa e respostas rápidas em caso de problemas.
Além dos benefícios em produtividade e prevenção de perdas, a iniciativa também contribuiu para a segurança no trabalho, mitigando riscos associados à remoção de fardos danificados e ao desmonte dos agrupamentos.
Suzano: Otimização da Estufagem de Veículos
Na busca por otimizar a estufagem de veículos, a Suzano investiu no desenvolvimento da equipe de logística da UNPE (Unidade de Negócios de Papéis e Embalagens).
A estufagem determina como cada material é adicionado ao veículo ou container, por isso envolve dimensões, disposição e tempo de carregamento.
A otimização dos espaços permitiu um carregamento mais estratégico, aumentando o KPI de toneladas por carro e resultando em uma economia notável de R$ 3 milhões anuais.
Para isso, foram conduzidas trilhas de aprendizagem em Python básica, Python para Data Science e Machine Learning em parceria com a Alura Para Empresas.
Saiba mais em 3 projetos da Suzano mostram que desenvolver pessoas traz resultados.
Diferença entre Machine Learning e Inteligência artificial
Muitas pessoas confundem os termos “Machine Learning” e “Inteligência Artificial”. No entanto, é importante saber que não são conceitos idênticos.
Plugins no ChatGPT, IA constitucional e machine learning ético – Hipsters: Fora de Controle #06
A IA é o termo mais abrangente, que compreende qualquer aplicativo ou máquina que imite a inteligência humana, como o GPT-3 e GPT-4 e ChatGPT, Midjourney e Generative AI Studio.
Tutorial MIDJOURNEY: Como usar e fazer Prompts Perfeitos

Sendo assim, o Aprendizado de Máquina é um subconjunto da IA. É como se fosse um dos tipos (ou espécie) da inteligência artificial.
De forma geral, trata-se máquinas ou programas que, depois de receberem treinamentos com dados existentes, podem identificar padrões, fazer previsões ou executar tarefas diante de dados inéditos.
Essa técnica envolve a conversão de dados e experiência em conhecimento, geralmente expresso por meio de modelos matemáticos.
Um exemplo disso é um sistema de Aprendizado de Máquina que, através de treinamentos por imagens, desenvolveu a capacidade de analisar ressonância magnética para reconhecer padrões de tumores, superando frequentemente a capacidade de especialistas.
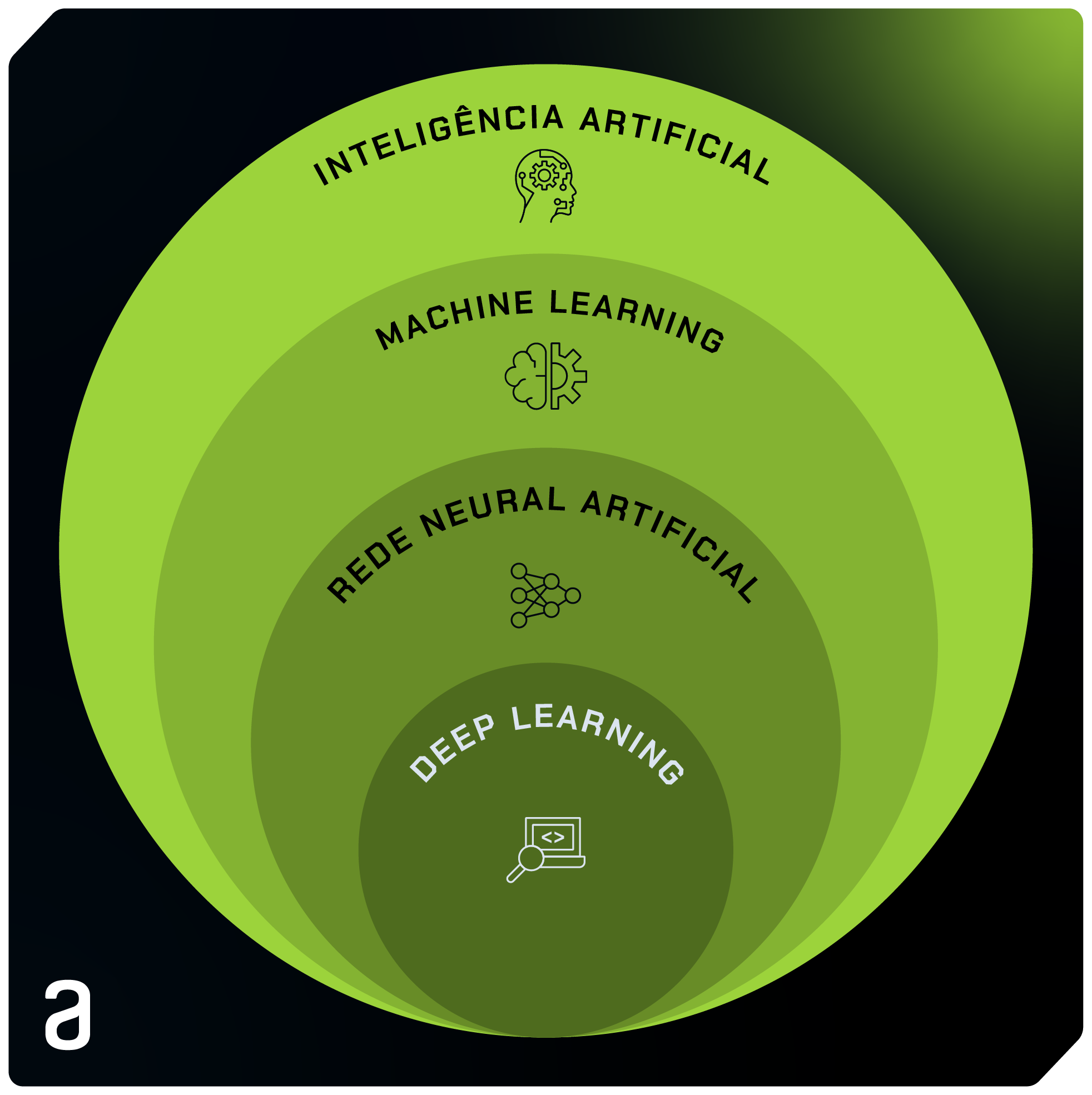
A partir do Diagrama de Venn, é possível observar a relação entre Inteligência Artificial e Machine Learning: o ML é uma subárea do campo de Inteligência Artificial.
Embora o nome "Inteligência Artificial" sugira que sempre terá um algoritmo de Machine Learning, nesse campo também há aplicações que não utilizam ML.
Um subconjunto em questão é chamado de GOFAI (Good Old-Fashioned Artificial Intelligence), ou "boa e velha IA".
Nele os sistemas de IA se baseiam em regras e lógicas programadas manualmente por pessoas desenvolvedoras, sem depender da capacidade de aprender com dados.
Um exemplo clássico de GOFAI são os chatbots simples que respondem a perguntas fornecendo respostas pré-programadas, muito utilizados em serviços de atendimento ao cliente.
Se quiser se aprofundar nesse assunto, esse artigo explora a diferença entre Data Science, Machine Learning e Inteligência Artificial.
Deep Learning, Redes Neurais e Machine Learning
Machine Learning, Deep Learning e Redes Neurais são conceitos que se relacionam entre si, cada um desempenhando um papel específico no campo da Inteligência Artificial.
O Machine Learning é o campo mais amplo entre os três, representando um conjunto de algoritmos que permitem a um sistema aprender padrões a partir de dados e tomar decisões com base nesse aprendizado.
Existem uma diversidade de algoritmos de ML e alguns deles estão dentro do campo do Deep Learning.
As Redes Neurais se caracterizam por serem uma técnica de aprendizagem dentro do domínio mais amplo do Machine Learning.
Ela é uma estrutura computacional composta por nós computacionais (os “neurônios”), que se organizam em camadas. Essas camadas incluem uma camada de entrada, uma camada de saída e, potencialmente, camadas ocultas.
Quando a rede neural tem mais camadas além da entrada e da saída (ou seja, mais de três ou mais camadas), é classificada como "profunda". Nesse caso, é um exemplo de Aprendizado Profundo, ou Deep Learning.
O Deep Learning é uma abordagem avançada dentro do campo do Machine Learning que se destaca pela utilização de Redes Neurais Artificiais Profundas.
A estrutura com mais camadas permite que a rede modele padrões complexos e realize tarefas sofisticadas de processamento de informações, comumente simulando o funcionamento do cérebro humano.
Em comparação com os algoritmos de Deep Learning, uma Rede Neural Artificial comum consegue resolver apenas problemas mais simples de aprendizagem.
O que é Deep Learning? #HipstersPontoTube

Tipos de Aprendizado de máquina
Atualmente, existem quatro tipos de aprendizado de máquina:
Aprendizado supervisionado; Aprendizado não supervisionado; Aprendizado semissupervisionado; e Aprendizado por reforço.
1) Aprendizado supervisionado
O aprendizado supervisionado é uma abordagem em aprendizado de máquina na qual a máquina é treinada usando exemplos de entrada e suas correspondentes saídas.
Em outras palavras, o modelo é ensinado a associar dados de entrada a resultados conhecidos. Por exemplo, ao construir um sistema para reconhecimento de flores, o aprendizado supervisionado envolveria alimentar o algoritmo com imagens de flores já rotuladas com suas espécies correspondentes.
O modelo aprende a identificar padrões e características associadas a cada espécie durante o treinamento. Posteriormente, quando apresentado a uma nova imagem de flor, o modelo consegue predizer a espécie com base nos padrões aprendidos.
2) Aprendizado não supervisionado
No aprendizado não supervisionado os modelos exploram dados não rotulados para identificar padrões e estruturas ocultas.
Uma técnica comum nesse tipo de aprendizado é o Clustering (ou Agrupamento), que consiste em agrupar dados semelhantes.
Por exemplo, considerando um conjunto de dados sobre interações em redes sociais, o aprendizado não supervisionado poderia revelar agrupamentos naturais de pessoas que compartilham interesses semelhantes.
Essa análise permite a descoberta de comunidades ou grupos de pessoas usuárias com base em padrões de comportamento, contribuindo para uma compreensão mais profunda da dinâmica social na plataforma.
3) Aprendizado semissupervisionado
O aprendizado semissupervisionado é uma categoria que se localiza na intersecção entre o aprendizado supervisionado e o não supervisionado. Ele surgiu diante da dificuldade de definir rótulos manualmente de um grande volume de dados em contextos reais.
Nessa perspectiva, o aprendizado semissupervisionado é aplicado em conjuntos de dados nos quais apenas uma parte dos exemplos está rotulada, enquanto outra parte permanece sem rótulos.
Com esses dados, o modelo de aprendizado tem acesso a informações parciais sobre o resultado desejado, permitindo-lhe aprender padrões e relações a partir dos dados rotulados disponíveis.
Ao mesmo tempo, o modelo utiliza os dados não rotulados para extrapolar e generalizar esses padrões para instâncias não observadas.
Por exemplo, uma empresa pode ter um grande conjunto de dados sobre seus clientes, como histórico de compras, comportamento de navegação no site e daí por diante.
No entanto, só pode rotular uma pequena parte desses dados, como, por exemplo, se a pessoa fez uma compra ou não.
O aprendizado semissupervisionado pode ser usado para identificar padrões nos dados não rotulados com base nas informações aprendidas dos dados rotulados. Isso pode ajudar a empresa a identificar potenciais clientes e aprimorar suas estratégias de marketing.
4) Aprendizado por reforço
O aprendizado por reforço é uma técnica de aprendizado de máquina baseada em feedback, na qual um agente aprende a se comportar em um ambiente realizando ações e observando os resultados.
Cada ação bem-sucedida resulta em feedback positivo para o agente, enquanto ações inadequadas recebem feedback negativo ou penalidades.
Diferentemente do aprendizado supervisionado, no aprendizado por reforço o agente aprende automaticamente por meio de feedbacks, sem depender de dados rotulados.
Podemos trazer uma aplicação para desenvolvimento de jogos. Em um jogo, uma agente (a pessoa que está jogando) precisa tomar uma série de decisões (ações) para alcançar um objetivo (ganhar o jogo).
A agente não tem instruções explícitas sobre como jogar o jogo, mas recebe feedback (recompensas) com base no resultado de suas ações.
Um exemplo famoso de aprendizado por reforço em jogos é o programa AlphaGo da DeepMind, que foi o primeiro programa de inteligência artificial a derrotar um campeão mundial humano no jogo de Go e tinha como algoritmo de Machine Learning um modelo de aprendizado por reforço.
Algoritmos comuns de ML
Existe uma grande diversidade de algoritmos de Machine Learning que abrangem os mais diversos problemas e objetivos. Entre os mais comuns podemos citar:
Regressão Linear
A Regressão Linear é um dos algoritmos mais simples e comuns de Machine Learning. Ele trabalha com conceitos matemáticos e estatísticos para prever um valor, por isso é comumente utilizado em problemas de Regressão com Aprendizado Supervisionado.
- Saiba mais em: Como funciona a regressão?.
A principal estratégia desse modelo é identificar a relação matemática e linear entre um valor de saída e os valores de entrada. A regressão linear encontra a reta que melhor representa a relação entre variáveis.
A representação que melhor demonstra essa relação será uma reta que minimiza as distâncias entre ela e todos os pontos de intersecção entre os valores das variáveis.
Por exemplo, se estivermos prevendo preços de casas, a regressão linear aprenderia a relação entre características das casas, como o número de cômodos e seus preços, encontrando a melhor reta para fazer previsões.
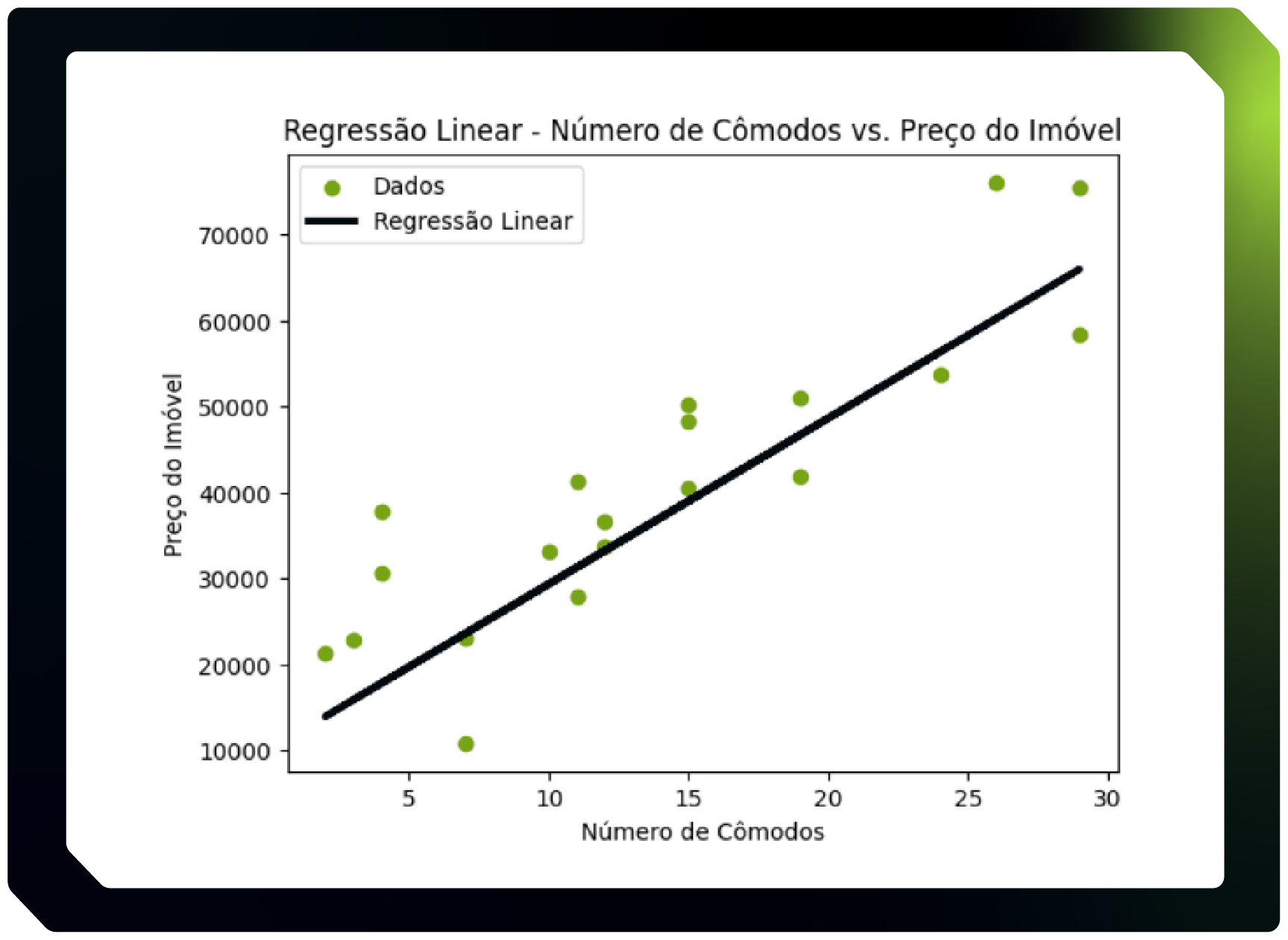
Infelizmente, o que torna a Regressão Linear um algoritmo simples, também o torna muito limitado, pois para que o modelo funcione de maneira adequada, é preciso existir uma relação linear entre as variáveis de entrada e a variável de saída rotulada.
Em contraposição a essa desvantagem, na Regressão Linear é possível observar a representação gráfica da relação linear entre as variáveis. Mais exemplos você pode ver no artigo Desvendando a Regressão Linear.
Regressão Logística
Mesmo existindo “Regressão” em seu nome e podendo ser aplicada em problemas de Regressão, a Regressão Logística é comumente utilizada em problemas de Classificação binária.
Isso é alcançado porque a Regressão Logística fornece valores probabilísticos entre 0 e 1, que podem representar a probabilidade de uma amostra pertencer a uma classe específica.
A palavra “Logística” no nome do algoritmo, refere-se a função logística (também conhecida como Sigmóide) que é aplicada a combinação linear das características do conjunto de dados.
Ao contrário da Regressão Linear que tem uma reta que pode atingir diversos valores, a função logística tem forma de "S" e faz a transformação dos valores em uma escala de 0 a 1.
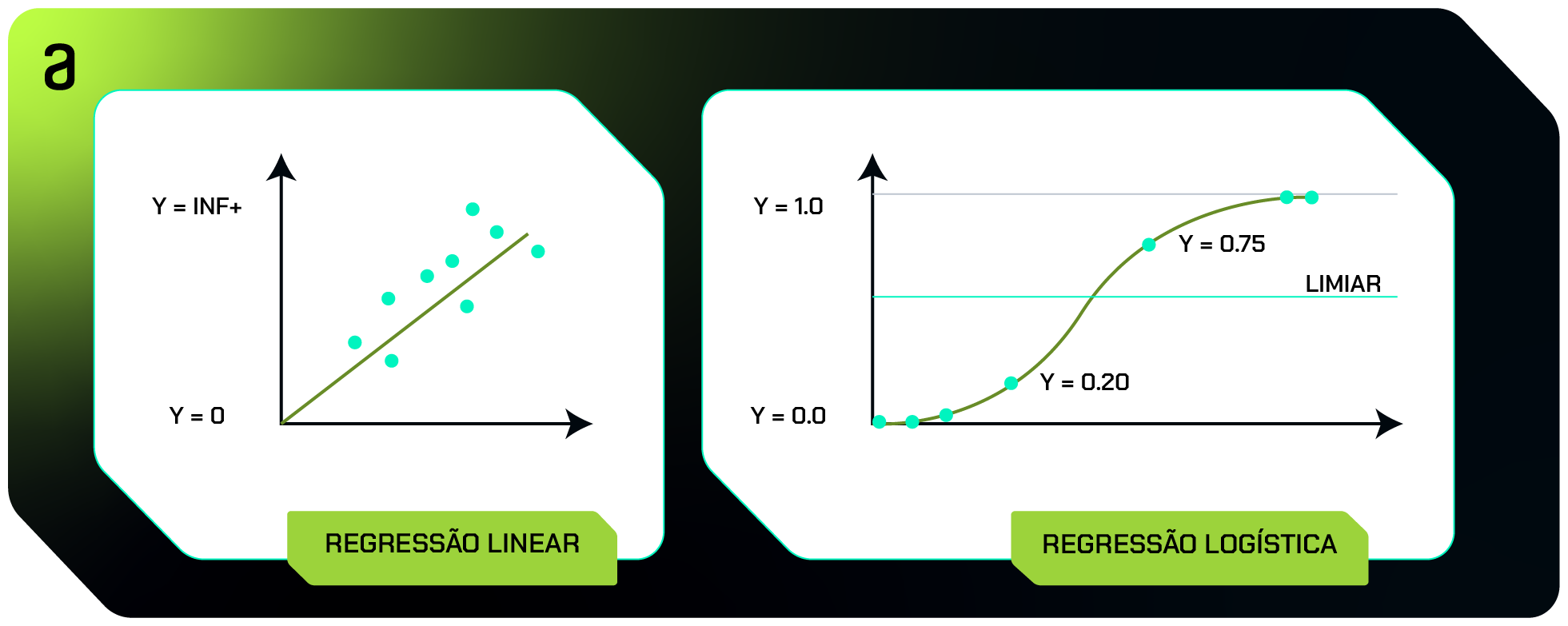
Para decidir a probabilidade de uma amostra pertencer a uma categoria, o modelo utiliza do Limiar (ou threshold) que determina a fronteira entre as classes.
Geralmente esse valor é especificado como 0.5 e tem grande impacto nas decisões: se a probabilidade Y estiver acima do Limiar, a instância é atribuída à classe positiva; caso contrário, à classe negativa.
Árvores de decisão
A Árvore de Decisão, empregada em aprendizado supervisionado para classificação e regressão, é uma estrutura hierárquica composta por nós de decisão e nós folha.
Durante o treinamento, o algoritmo inicia com um nó raiz representando todo o conjunto de dados, dividindo-o recursivamente com base em variáveis de entrada até que cada subconjunto contenha apenas uma classe ou valor de saída.
A estrutura final mostra uma raiz conectada a nós de decisão, representando escolhas com base nas variáveis de entrada, e a nós folha, indicando resultados finais. Como podemos observar no esquema simplificado desta estrutura:
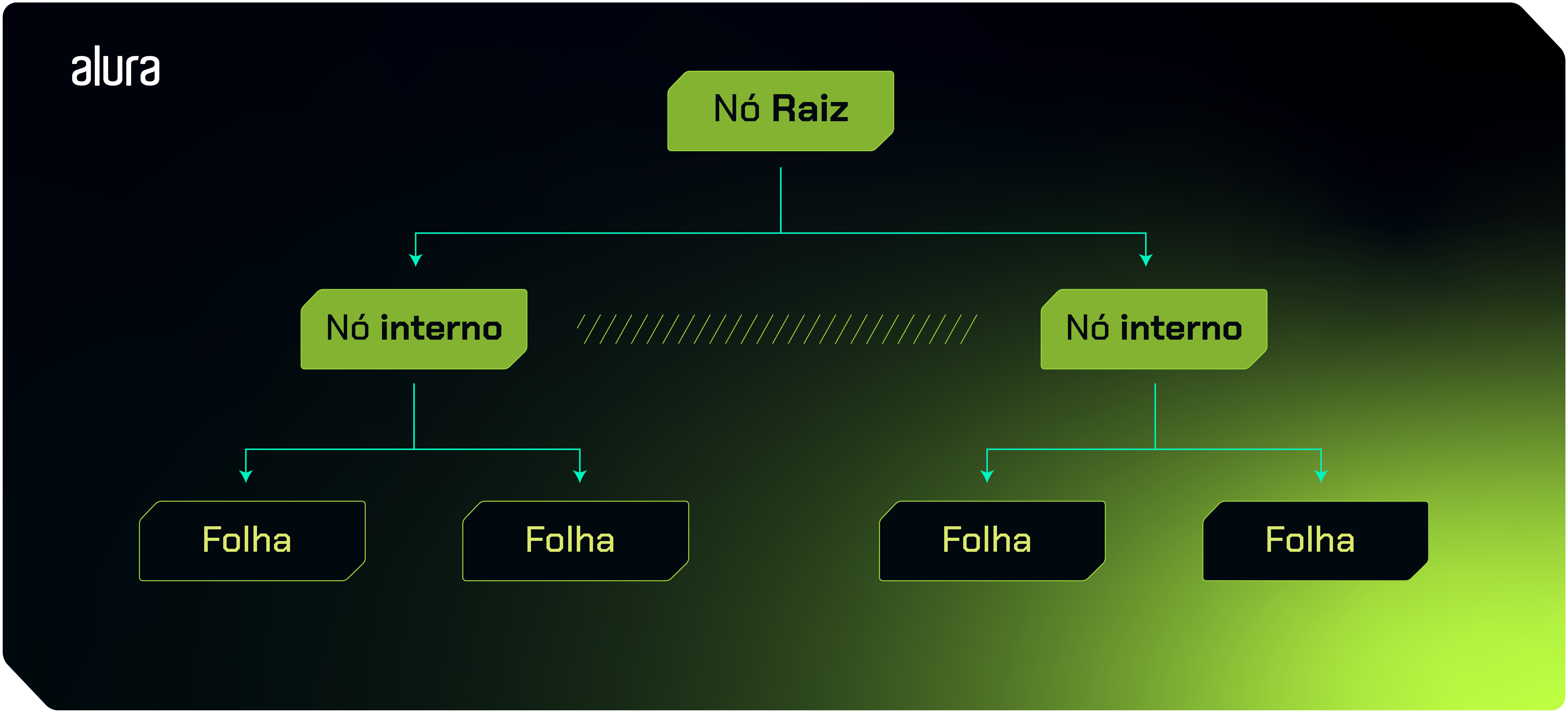
A estrutura de uma Árvore de Decisão assemelha-se a uma árvore comum, começando pela raiz da árvore que é o nó superior e representa todo o conjunto de dados.
A partir disso, a árvore se ramifica em nós de decisão, que representam as escolhas que podem ser feitas com base nas variáveis de entrada.
Cada nó de decisão tem ramos que representam as diferentes opções que podem ser escolhidas. Esses ramos levam a outros nós de decisão ou a nós folha, que representam os resultados finais.
Os nós folha são os nós finais da árvore e representam os resultados finais da análise. Eles não têm ramos saindo deles. Cada nó folha representa uma classe, em caso de problemas de classificação ou valor de saída, em problemas de regressão.
Florestas aleatórias
O Random Forest é um algoritmo de aprendizado de máquina supervisionado que se destaca pela diversidade.
Ao treinar, em vez de usar todos os dados disponíveis, ele seleciona aleatoriamente amostras do conjunto de treino.
Da mesma forma, ao construir cada árvore, o algoritmo não considera todas as variáveis, mas escolhe, de forma aleatória, algumas delas para determinar os melhores nós.
Esse processo adiciona uma camada de aleatoriedade e diversidade ao modelo, ajudando a evitar um foco excessivo em um conjunto específico de variáveis e, consequentemente, o overfitting.
Machine Learning: o que é overfit? | #AluraMais

A seleção aleatória de variáveis e amostras pode parecer estranha à primeira vista, mas é altamente eficaz. Essa estratégia resulta em diversas árvores, cada uma com pequenas imperfeições aleatórias, o que evita o overfitting a um conjunto particular de dados.
A pluralidade de árvores contribui para a robustez do modelo, e no final, as árvores combinam suas previsões para gerar um resultado mais confiável, seja tirando a média das previsões em problemas de regressão ou selecionando o resultado mais comum em problemas de classificação.
K-means clustering
O algoritmo de K-Means Clustering é uma técnica de Aprendizado Não Supervisionado que agrupa um conjunto de dados não rotulados em diferentes clusters.
Nesse método, o valor de K (número de clusters desejado) é pré-definido pela pessoa especialista, indicando quantos grupos serão criados durante o processo.
O algoritmo funciona da seguinte maneira: primeiro, o usuário especifica o número de clusters desejado (K), para explicar vamos considerar K = 3.
Em seguida, o algoritmo seleciona aleatoriamente 3 pontos (K pontos) do conjunto de dados como centros iniciais dos clusters.
A cada iteração, cada ponto de dados é atribuído ao cluster cujo centro está mais próximo. Os centros dos clusters são então recalculados com base nos pontos atribuídos a eles, e o processo é repetido até que a atribuição dos pontos aos clusters não mude significativamente entre iterações. Desse modo, vamos ter ao final 3 clusters:
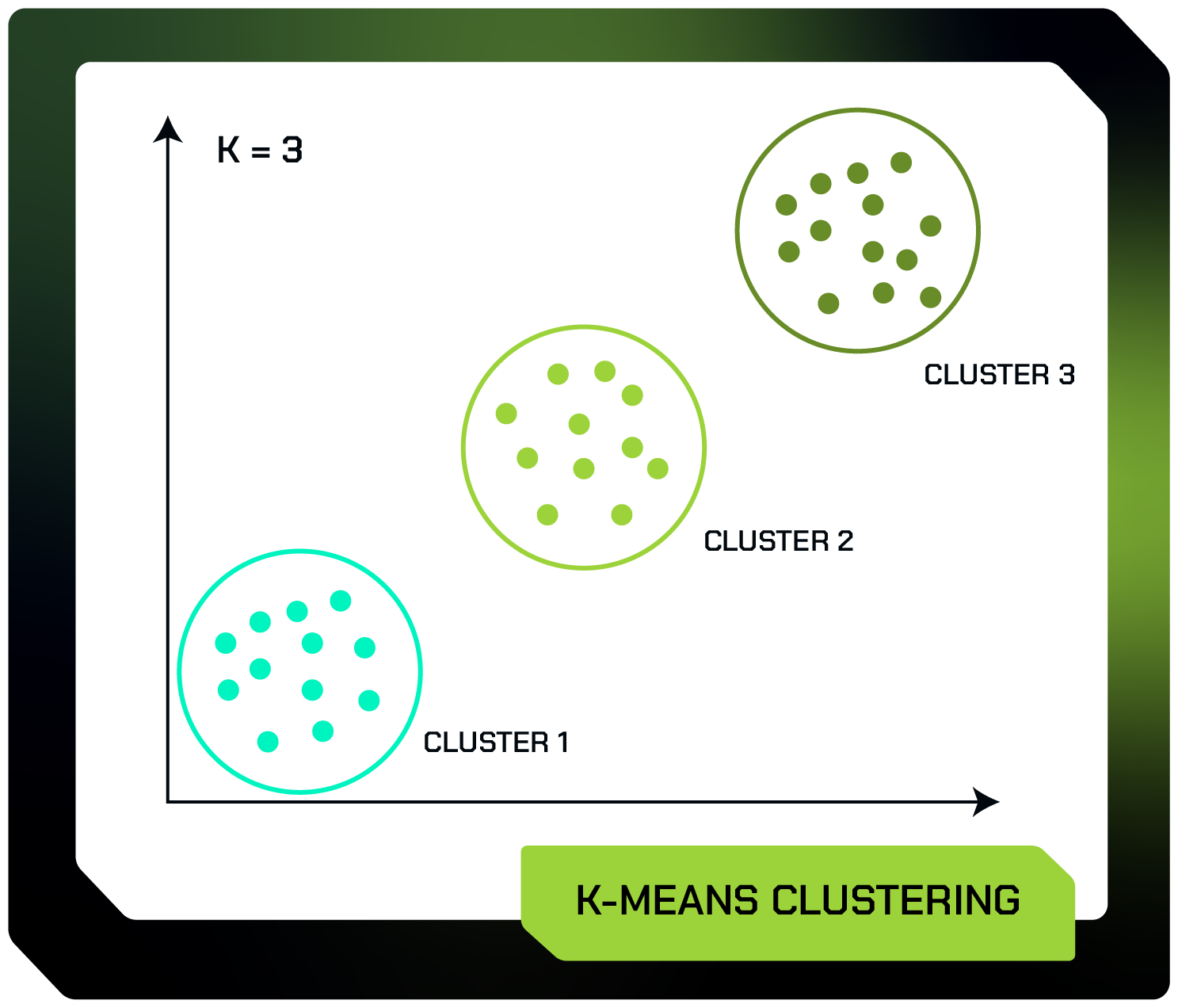
Ao final, esse algoritmo divide o conjunto de dados em 3 clusters (K clusters) de modo que cada conjunto pertença a apenas um grupo com propriedades semelhantes.
A ideia principal é minimizar a soma das distâncias entre os pontos de dados e os centróides correspondentes.
- Saiba mais: Agrupando dados com Python
Redes Neurais
Originadas de simples Perceptron, as Redes Neurais Artificiais são uma arquitetura fundamental que serve como base para redes neurais mais avançadas. Mesmo existindo Redes Neurais Simples, são as Redes Neurais focadas em Aprendizado Profundo que carregam a fama das Redes Neurais. Vamos conhecer as mais notáveis:
Redes Neurais Feedforward (FF)
As Redes Neurais Feedforward são uma das formas mais antigas de redes neurais. Nesse tipo de arquitetura, os dados fluem em uma única direção, passando por diferentes camadas de neurônios artificiais até que a saída desejada seja alcançada.
Cada camada processa as informações e as transfere para a próxima camada sem formar ciclos de realimentação, tornando-as eficazes em tarefas como classificação e regressão, onde os dados podem ser representados como entradas independentes e a ordem das entradas não possui um significado especial, como dados não sequenciais.
Redes Neurais Recorrentes (RNN)
As Redes Neurais Recorrentes são projetadas para lidar com dados sequenciais, como séries temporais. Elas introduzem a ideia de "memória" nas redes neurais, onde as saídas anteriores influenciam as saídas futuras. No entanto, as RNNs enfrentam desafios de retenção de informações a longo prazo.
Memória de Longo/Curto Prazo (LSTM)
As LSTMs são uma forma avançada de RNN que aborda o problema de curto alcance de retenção de informações. Elas são capazes de "lembrar" eventos importantes de camadas anteriores, permitindo a manipulação eficaz de dados sequenciais mais extensos.
Essa capacidade de retenção de informações de longo prazo faz com que as LSTMs se destaquem em tarefas complexas, como tradução automática e geração de texto buscando prever a próxima letra.
Redes Neurais Convolucionais (CNN)
As Redes Neurais Convolucionais são amplamente empregadas em tarefas de Visão Computacional.
Com uma arquitetura composta por camadas convolucionais e de pooling, as CNNs são eficientes em extrair padrões espaciais em dados, sendo ideais para o processamento de imagens.
Elas aplicam filtros para identificar características relevantes antes de passar para camadas totalmente conectadas para tomadas de decisão.
Redes Adversárias Generativas (GAN)
As Redes Adversárias Generativas levam uma abordagem que envolve duas redes neurais, uma geradora e uma discriminadora, competindo entre si. A geradora cria dados que tentam ser idênticos aos dados reais, enquanto a discriminadora tenta diferenciá-los.
Os dados criados e discriminados podem ser imagens, áudios, vídeos e até textos, tudo depende do objetivo da GAN. Essa competição resulta em um aprendizado mais refinado, sendo utilizado em aplicações como geração de imagens e tradução de estilo.
Vantagens e desvantagens de ML
O uso e desenvolvimento de Machine Learning tem diversas vantagens e desvantagens. Entre as vantagens podemos listar:
- Os modelos de Machine Learning podem analisar grandes conjuntos de dados e identificar padrões complexos, melhorando a precisão nas tomadas de decisões.
- O ML automatiza tarefas repetitivas e demoradas, aumentando a eficiência operacional.
- Os algoritmos de ML podem ser treinados com novos dados, tornando-os adaptáveis a mudanças nas condições do ambiente.
- O Machine Learning é eficaz em reconhecer padrões e tendências em dados, auxiliando na previsão de resultados futuros.
Enquanto desvantagens, podemos citar:
- Se os dados utilizados para treinar modelos contêm viés, o Machine Learning pode reproduzir e amplificar esses preconceitos, o que pode levar a resultados discriminatórios.
- Alguns modelos de ML, especialmente os mais complexos, podem ser difíceis de interpretar seu funcionamento, o que pode dificultar a compreensão de como as decisões são tomadas.
- O desempenho dos modelos de ML depende da qualidade dos dados utilizados no treinamento. Dados imprecisos ou enviesados podem resultar em previsões incorretas.
- O uso extensivo de dados pode levantar preocupações sobre privacidade, especialmente quando se trata de dados pessoais sensíveis.
Carreiras em Machine Learning
O mercado para Machine Learning é relativamente novo, mas tem um bom potencial de crescimento. Junto ao advento das Inteligências Artificiais no mercado da tecnologia, o Machine Learning conseguiu ser destaque na demanda por pessoas especializadas nesse campo. Atualmente já existem carreiras em que o ML é presente em seu campo de atuação.
Carreira de Cientista de Dados
Inicialmente, a pessoa cientista de dados tinha o foco em realizar análises descritivas e desenvolvimento de modelos estatísticos, mas posteriormente seu papel se estendeu para também realizar a criação de modelos de Aprendizado de Máquina.
Atualmente, uma pessoa Cientista de Dados precisa saber executar com maestria tarefas como coleta de dados, limpeza de dados e processamento de dados, buscando preparar um conjunto de valores para se transformar em informação útil. Com os dados prontos, esse profissional consegue executar análises e desenvolver modelos de Machine Learning.
Hipsters Ponto Tube: O que faz uma Cientista de Dados?
Focando nas habilidades envolvendo Machine Learning, uma pessoa cientista de dados compreende os fundamentos estatísticos por trás de modelos de ML e tem a capacidade de aplicar técnicas avançadas de aprendizado de máquina para resolver problemas específicos.
Para isso, possuem habilidades sólidas em programação e estão familiarizados com bibliotecas e frameworks relevantes para ML.
Para além das competências técnicas, cientistas de dados são verdadeiros profissionais em <T> pois além de precisarem colaborar com outras equipes, como engenharia de software, análise de negócios e engenharia de dados, garantindo que os modelos desenvolvidos se alinhem às metas e necessidades gerais da organização, também é preciso ter a habilidade de traduzir insights complexos em linguagem compreensível para as partes interessadas e não técnicas.
Dev em T: programação, carreira e tipos de perfil | #HipstersPontoTube

Carreira de Engenharia de ML | MLOps
A pessoa Engenheira de Machine Learning (Machine Learning Engineer) desempenha um papel crucial na integração de modelos de aprendizado de máquina aos sistemas existentes, combinando habilidades de engenharia de software, ciência de dados e DevOps.
Nessa função, é essencial garantir a harmonia entre os modelos de ML e os sistemas de produção, facilitando o consumo e o treinamento de dados. Além disso, um profissional é responsável pelo monitoramento contínuo do desempenho dos modelos, exigindo automação eficiente para ajustes e retreinamento, garantindo a manutenção da precisão ao longo do tempo.
Ops em Machine Learning Revisitado – Hipsters Ponto Tech #333
Essa posição híbrida demanda competências sólidas em estatística, ciência de dados e programação, destacando-se por suas habilidades de engenharia de software.
Uma pessoa ML Engineer atua como um elo entre diversas áreas, colaborando estreitamente com a Engenharia de Dados, desenvolvimento de software e equipes de DevOps.
Sua capacidade de comunicação e trabalho em equipe é fundamental, pois o profissional de engenharia de ML é intrinsecamente multidisciplinar, desempenhando um papel central na comunicação entre as áreas técnica e de dados.
O que faz uma pessoa engenheira de Machine Learning? com Thiago Santos | #HipstersPontoTube
Em organizações de menor porte, esse profissional pode assumir também as funções de um cientista de dados, refletindo a versatilidade e adaptabilidade necessárias para manter sistemas de produção de ML eficientes e em perfeito funcionamento.
À medida que a automação dos algoritmos de ML continua a evoluir, a relevância e demanda por Engenheiros de Machine Learning crescem, representando uma profissão em constante destaque e amadurecimento no cenário tecnológico.
- Saiba mais: ML Engineer, o Dev em
Carreira de pessoa Pesquisadora de ML
Enquanto existir espaço para a descoberta de novas tecnologias, sistemas e métodos, irá existir a pessoa pesquisadora. Uma pessoa pesquisadora em Machine Learning busca por novos algoritmos e aplicações no mercado.
Diversas empresas de tecnologia investem em uma equipe de pessoas que se dedicam a investigar e desenvolver abordagens inovadoras para desafios específicos dentro do campo de Machine Learning.
A pessoa pesquisadora em ML pode atuar em diversas organizações como empresas de tecnologia, indústrias, instituições acadêmicas e órgãos governamentais.
De maneira geral, uma pessoa profissional nesse ramo conduz estudos, experimentos e análises aprofundadas para avançar o estado da arte, contribuindo para o desenvolvimento teórico e prático do campo de estudo da organização na qual ela faz parte.
Será que eu faço uma faculdade de tecnologia? com Mikaeri Ohana | #HipstersPontoTube

O futuro do Machine Learning
Agora que já conhecemos bem a temática de Machine Learning, que tal verificar possibilidades para o futuro de ML?
Nesse espaço, a Mirla contou com a participação da Letícia Pires, Alura Star, em uma entrevista com insights preciosos. Vamos conferir?

Quais as tendências para o campo de Machine Learning?
Acredito que uma tendência daqui para frente, e que já estamos acompanhando, é o avanço das LLMs, como o GPT-4. Ferramentas como essa têm transformado a maneira como compreendemos e interagimos com os dados, o que abre porta para diversas aplicações. Além disso, com o aumento da complexidade dos modelos, a questão ética tem sido colocada em foco. A proteção de dados, promoção de diversidade e mitigação de viés, criação de algoritmos mais justos e responsáveis têm se tornado cada vez mais importantes.
Quais os desafios mais significativos de pessoas que atuam nessa área?
A dimensão ética é um ponto bem importante e que exige uma constante reflexão sobre responsabilidade no desenvolvimento de um algoritmo. A reestruturação organizacional para se adaptar às novas IAs é outro desafio que pode demandar uma mudança cultural e estrutural nas empresas. Além disso, por ser uma tecnologia recente, existe uma escassez de conteúdos relacionados, especialmente em português, o que pode representar um desafio para quem deseja imergir no assunto. Por consequência, o inglês acaba se tornando um desafio grande e que é cada vez mais importante.
Como as novas tecnologias, como as IAs, impactam o trabalho de profissionais em Machine Learning?
De maneira positiva, essas novas tecnologias ajudam demais a detalhar ideias, automatizar tarefas repetitivas e agilizar processos, o que proporciona eficiência e permite que profissionais se concentrem em aspectos mais estratégicos. No entanto, existem alguns pontos negativos associados, como a possibilidade de obter informações incorretas. Além disso, existem as considerações éticas, como o uso inadequado de imagens. Um exemplo que gerou muitas discussões, foi o uso de IA em uma peça de publicidade para simular imagem de Elis Regina, falecida em 1982. Algumas questões foram levantadas se o deepfake de Elis Regina constituía ou não violação ética. É uma tecnologia nova que alarma demais, e, por isso, ainda estão sendo decididos os limites em torno dela e é crucial manter debates sobre o assunto.
Como acompanhar tantos avanços e desenvolvimento de novas tecnologias neste campo?
A participação em eventos é crucial, não apenas para se manter atualizado, mas também para expandir conexões e criar networking. Além disso, participar de hackathons é uma forma de conhecer mais sobre outros projetos ou pontos em pauta, criação de portfólio e contatos com pessoas referentes na área. Outra forma é consumir alguns conteúdos da área no Linkedin, vídeos no YouTube, cursos, participação em comunidades, certificações - como forma de auxiliar no conhecimento de novas tecnologias.
Que tal conferir outras dicas e conteúdos que você pode encontrar aqui na Alura?
Cursos na área de ML
Na Alura temos uma diversidade de cursos focados no tema de Machine Learning. Neles você aprende desde o básico da aprendizagem até a construção de modelos mais complexos.
- Machine Learning com Python: Classificação;
- Machine Learning;
- Machine Learning Avançada;
- Machine Learning para Negócios Digitais.
Aprenda mais sobre Machine Learning gratuitamente
Acesse gratuitamente as primeiras aulas da Formação Machine Learning, feito pela Escola de Data Science da Alura e continue aprendendo sobre temas como:
Machine Learning parte 1: otimização de modelos através de hiperparâmetros
Machine Learning parte 2: otimização com exploração aleatória

Conclusão
O Machine Learning se destaca como ferramenta útil em diversas organizações e empresas por contribuir na automatização de processos, tomada de decisões, identificação de problemas, previsão de cenários futuros, etc.
É notável o avanço desse campo e sua grande adaptabilidade ao contexto digital moderno, impulsionando inovações que vão desde assistentes virtuais como a Amazon Alexa até a identificação de falhas em linhas de produção e estufagem de container.
Mesmo tendo suas desvantagens, o ML vem trazendo cases de sucesso e otimização em diversos setores. Com técnicas variadas, como Agrupamento, Classificação e Regressão, além de abordagens de aprendizagem Supervisionada, Não Supervisionada, Semissupervisionada e por Reforço, o Machine Learning contemporâneo se mostra muito versátil em diversos problemas.
Bibliografia
Hands-On Machine Learning with R de Bradley Boehmke & Brandon Greenwell. Capítulos 1, 4, 5, 9, 11, 13, e 20.
3 projetos da Suzano mostram que desenvolver pessoas traz resultados de Athena Bastos
Caltech - California Institute of Technology How Do AI and Machine Learning Differ?
Google Cloud What's the difference between deep learning, machine learning, and artificial intelligence?
O que é machine learning? Supervised vs. unsupervised learning: What's the difference?
JataTpoint Machine Learning Tutorial
AI without machine learning de Dr. Frank Säuberlich e Prof. Dr. Danko Nikolić
MIT Technology Review What is machine learning? de Karen Hao
Machine Learning – Guia de Referência Rápida: Trabalhando com Dados Estruturados em Python
Créditos
Criação Textual: Mirla Costa
Participação externa - Especialista de mercado: Letícia Pires | Redes sociais: Linkedin, Instagram, Youtube
Produção técnica: Rodrigo Dias
Produção didática: Pedro Drago
Designer gráfico: Alysson Manso
Apoio Rômulo Henrique
Perguntas Frequentes:
Qual o objetivo do Machine Learning?
O objetivo do Machine Learning é desenvolver algoritmos e modelos capazes de aprender a partir de dados e realizar tarefas específicas sem serem explicitamente programados. Ele permite que os computadores automaticamente descubram padrões e façam previsões ou tomem decisões com base nesses padrões.
Quais são os tipos de machine learning?
Existem três tipos principais de Machine Learning: o aprendizado supervisionado, no qual os modelos são treinados com dados rotulados para fazer previsões ou classificações; o aprendizado não supervisionado, em que os modelos encontram padrões nos dados sem rótulos; e o aprendizado por reforço, no qual os modelos aprendem através de tentativa e erro, recebendo recompensas ou penalidades.
Qual a diferença entre Inteligência Artificial e Machine Learning?
A Inteligência Artificial (IA) é um campo mais amplo que abrange diferentes técnicas e abordagens para criar sistemas que podem simular a inteligência humana. Machine Learning, por outro lado, é uma subárea da IA que se concentra em desenvolver algoritmos que permitem que os computadores aprendam com os dados e melhorem seu desempenho ao longo do tempo, sem serem explicitamente programados.
Machine Learning e Python: Qual a relação?
Python é uma das linguagens de programação mais populares para desenvolver soluções de Machine Learning (ML). Ela oferece uma ampla gama de bibliotecas e frameworks, como TensorFlow e scikit-learn, que simplificam a implementação de algoritmos de Machine Learning. Python é conhecido por sua sintaxe clara e de fácil aprendizado, tornando-o uma escolha comum para os profissionais que trabalham com ML.
Deep Learning e Machine Learning: Principais diferenças
Deep Learning é uma subárea do Machine Learning que se concentra no treinamento de redes neurais profundas para aprender representações hierárquicas de dados. Enquanto o Machine Learning tradicional requer a extração manual de características dos dados, o Deep Learning é capaz de aprender essas características automaticamente. Isso permite que o Deep Learning lide com problemas mais complexos e com grandes volumes de dados, mas também requer mais recursos computacionais e conjuntos de dados de treinamento maiores.
