
Quando estamos trabalhando com dados,principalmente na fase de mineração, realizamos muitas mudanças no dataset.
Existem colunas que não queremos, ou precisamos usar, ou linhas que não contém dados válidos que precisam ser removidas.
Mas quantos mais dados não é melhor?
Quando estamos analisando dados, principalmente para treinar modelos de inteligência artificial, alguns dados podem prejudicar ao invés de ajudar. Por isso, temos que utilizar apenas os dados que fazem sentido para o modelo.
Legal! Já sabemos que precisamos tratar os dados, mas como podemos fazer isso, como remover os dados?
Removendo colunas no Pandas
Estou fazendo uma análise sobre gorjetas em transportes como táxis. Para isso, estou utilizando o Pandas que é uma biblioteca que facilita a manipulação dos dados.
No Pandas, temos um tipo de dado chamado DataFrame. Podemos dizer que um data frame é como uma planilha. Ou seja, temos linhas e colunas.
Podemos ver o começo do conteúdo da planilha utilizando o método head do data frame:
tips.head()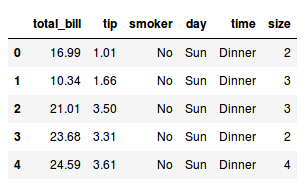
Podemos ver que o DataFrame lembra muito uma planilha. Cada coluna também conhecida como variável tem um nome, e cada linha conhecida como observação tem um índice e os dados que representam cada variável.
Para a análise que eu quero fazer, não preciso saber se as pessoas são fumantes ou não, por isso, não faz necessário analisar a coluna smoker, como podemos removê-la?
A primeira coisa que precisamos fazer é excluir a coluna que nos diz se as pessoas são fumantes ou não. Essa coluna não é necessária para o tipo de análise que queremos fazer. Então vamos removê-la. Mas como?
No Pandas, existe o método drop para os data frames. Nesse método, podemos passar o indice da linha que desejamos remover.:
>>> # no interpretador
>>> tips.drop(2)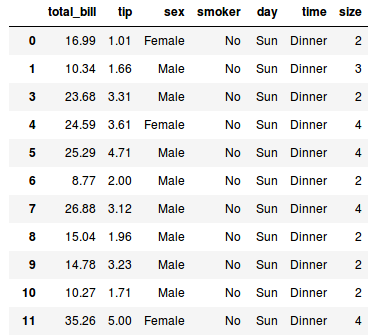
Esse comando, removemos a linha de índice 2. Mas não queremos remover uma linha e sim uma coluna. Para isso, basta passar o parâmetro columns, esse parâmetro recebe uma lista com o nome das colunas que desejamos remover, smoker no nosso caso.
Após isso, vamos falar para o Pandas nos mostrar o cabeçalho desse data frame:
tips.drop(columns=['smoker'])
tips.head()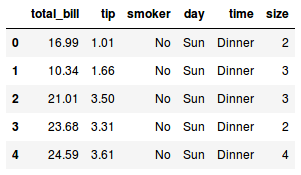
Ué? A coluna ainda está ali. O que aconteceu?
Por padrão, as operações que efetuamos em um DataFrame não afetam ele. Isto é, sempre que removemos uma coluna, linha, etc, o que o Pandas faz é devolver um novo DataFrame sem aquele dado. Ou seja, o DataFrame original se mantém intacto.
O que podemos fazer para resolver isso é atribuir esse data frame que é devolvido pelo método na mesma variável:
tips = tips.drop(columns=['smoker'])
tips.head()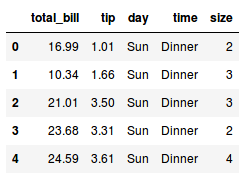
Legal! Conseguimos remover a coluna que precisávamos. Agora, vamos para outra parte do tratamento dos dados. Na análise que estou fazendo, quero analisar as gorjetas de grupos de pessoas. É considerado um grupo quando duas ou mais pessoas estão dentro do veículo.
Como podemos fazer para remover as linhas que não atendem a essa condição?

Removendo linhas
Sabemos que podemos utilizar o método drop() para retirar uma linha. Mas como remover todas as linhas que contém apenas um passageiro?
Podemos fazer um loop e iterar por cada linha no data frame e checar se o número de passageiros é maior que um. Se sim, mantemos esse dado, do contrário, removemos do data frame. Mas qual o problema dessa solução?
Mas o Pandas já tem diversas formas para trabalhar com seus data frames. O que podemos fazer é criar um filtro no qual é retornado um novo DataFrame com os dados já filtrados.
O Pandas permite filtrar um DataFrame pelos dados de sua coluna. Por exemplo, queremos pegar do data frame de gorjetas (tips) a coluna que define o número de passageiros (size) e com base nisso, queremos as linhas nas quais a coluna size é maior que um:
filtro = tips['size'] > 1Agora, basta passarmos esse filtro como seletor no DataFrame:
filtro = tips['size'] > 1
gorgetas_em_grupo = tips[filtro]Esse filtro nos retorna um DataFrame com as linhas onde o número de passageiros é maior que 1. Ou seja, os dados que passam pelo filtro:
gorgetas_em_grupo.head()
Para saber mais
Os filtros utilizados podem ser mais complexos. Podemos utilizar estruturas condicionais,como o E e OU e checar o valor de mais de uma coluna. Além disso, podemos fazer outros tipos de filtros.
Como checar se alguma linha tem um valor nulo, ou um valor de um tipo diferente do esperado. Para isso, o Pandas utiliza o conceito de comparação rica, ou rich comparison.
Além de remoção, conseguimos fazer outras operações com os data frames, operações que envolvem string, renomear colunas e adicionar colunas novas, juntar um data frame a outro, entre diversas outras operações.
Aqui na Alura, temos uma formação de data science com Pandas. Nele você verá como manipular data frames de diversas formas. Além de ver como criar gráficos, visualizar estatísticas descritivas, tratar dados faltantes e muito mais.
