
Fui contratado por uma empresa para analisar o que cada cliente está comprando. A ideia é conseguir agrupar os clientes por gostos iguais. Dessa forma, serão feitas newsletters, promoções e campanhas de marketing direcionadas para clientes com algo em comum.
Para isso, precisamos pegar dados de clientes, como a categoria dos produtos que cada um costuma comprar e com que frequência isso ocorre. Bem, já temos os dados definidos, mas como podemos criar grupos com os clientes? Quantos grupos devemos criar?
O aprendizado não supervisionado
Quando estamos trabalhando com análise de dados, é muito comum utilizar o aprendizado de máquinas, ou machine learning, para criar um modelo que classifique os dados para gente. Existem algoritmos que podemos utilizar para ensinar a máquina como trabalhar, mas qual deles utilizar?
Podemos classificar os nossos dados, mas não temos um rótulo para ensinar o classificador. Podemos definir esses rótulos na mão, isto é, ir analisando o perfil um por um e criar os grupos de clientes, mas isso levaria muito tempo e seria muito trabalhoso. O que nós podemos fazer para obter esses rótulos, isso é, o grupo que cada cliente pertence?
Vamos imaginar que temos dois tipos de frutas diferentes, maçãs e maracujás. Como faríamos para agrupá-las? Bem, nesse caso, temos dois grupos, maçãs e maracujás. Assim, utilizamos algumas das características das frutas para agrupá-las: cor, formato, tamanho,gosto, entre outras.
A partir dessas características, criamos os rótulos dos nossos dados. Podemos pegar as características que extraímos dos clientes, sua frequência de compra e a qual categoria pertencem os produtos que mais compram e utilizar essas informações para agrupá-los.
Podemos criar os grupos de acordo com a necessidade de segmentação, dois, três, oito, grupos, segmentar bem o conjunto de dados ou não segmentar tanto.
Para agrupar os dados podemos pegar um cliente que compra dez vezes no mês e compra muitos livros de ficção científica. Outra cliente também compra livros de ficção, mas com uma frequência de oito vezes no mês.
Apesar de não terem as mesmas frequências de compra, elas são parecidas. Também são os gostos. Logo, se fizer sentido, podemos colocá-los em um mesmo grupo. Isso nos mostra que, se criarmos um gráfico de número de compras por categorias, os valores que estão próximos podem pertencer ao mesmo grupo.
Existem diversos algoritmos que podemos utilizar para agrupar os dados, um desses é o K-médias, ou K-means. Esse algoritmos pega cada um dos nossos dados (observações), para cada grupo (k). Cada dado pertencerá ao grupo mais próximo da média.
No Python, existe a biblioteca scikit-learn. Essa biblioteca é muito utilizada pelas pessoas que trabalham com análise de dados e com machine learning. Ela já tem implementado diversos algoritmos que usamos no dia a dia, sendo um deles o K-means.

Conhecendo a sklearn
Queremos utilizar a scikit no nosso código, então o primeiro passo é importá-la (import):
import sklearn
Legal! Mas qual função da biblioteca nós queremos utilizar? Queremos utilizar o K-means, então nós podemos, em vez de importar todos os módulos da biblioteca, importar somente o K-means.
Para isso, falamos que da biblioteca (from) sklearn, do módulo de agrupamento (cluster), queremos importar o KMeans:
from sklearn.cluster import KMeans
Já temos a classe que implementa o algoritmo, o que precisamos agora? Criar um objeto a partir dessa classe:
from sklearn.cluster import KMeans
modelo = KMeans()
Com o modelo instanciado, podemos pedir para treiná-lo e para ele predizer os dados dos usuários:
usuarios = pega_usuarios()
from sklearn.cluster import KMeans
modelo = KMeans()
modelo.fit_predict(usuarios)
Esse método nos retorna uma série de números que são os rótulos dos nossos dados, a predição. Ou seja, conseguimos atribuir esse retorno a uma variável e utilizá-la em outra partes do código:
from sklearn.cluster import KMeans
modelo = KMeans()
rotulos = modelo.fit_predict(usuarios)
Agrupamos nossos dados, mas como podemos ver esses grupos?
Visualizando os grupos
Uma das formas que temos para visualizar os dados é a criação de gráficos. Uma biblioteca muito utilizada para isso é a matplotlib. Como a outra biblioteca, precisamos importá-la para começar a utilizar suas funções.
Nessa biblioteca, queremos utilizar o módulo de criação de gráficos com o Python (pyplot):
import matplotlib.pyplot
Por convenção, muitos desenvolvedores colocam um apelido (alias) nessa importação, chamando de plt:
import matplotlib.pyplot as plt
Antes de mostrar os grupos, vamos ver como estão nossos dados. Para isso, podemos pedir para o Matplot plotar um gráfico com os pontos dos nossos dados. Esses gráficos tem dois pontos, um para o eixo X e um para o eixo Y
Como estamos querendo mostrar um gráfico do número de compras por categorias de produtos, esses serão nossos valores de X e Y, respectivamente. No meu caso, os dados dos usuários estão em um Array do Numpy, onde a primeira coluna são a frequência das compras e o segunda coluna são as categorias:
# codigo omitido
plt.scatter(usuarios[:, 0], usuarios[:, 1])
Agora só precisamos mostrar (show) o gráfico:
# codigo omitido
plt.scatter(usuarios[:, 0], usuarios[:, 1])
plt.show()
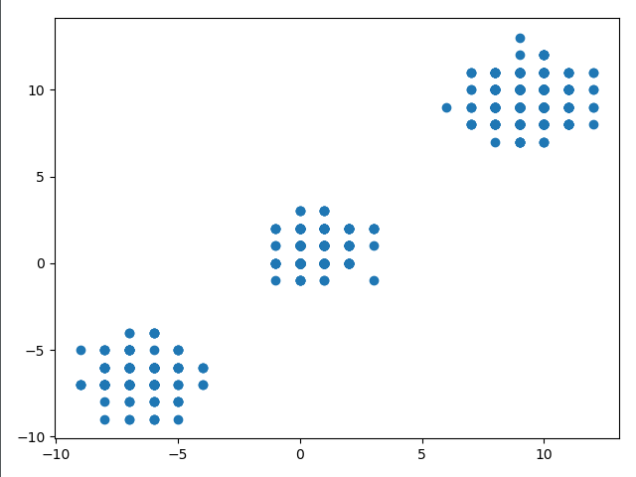
Esse é o nosso gráfico sem grupos. Agora, temos que ver os grupos. Mas como podemos ver os grupos em um gráfico? Bem, cada grupo pode ser representado por uma cor diferente.
No Matplot, podemos dizer quais cores queremos para os itens no gráfico. Existem diversos meios de escolher as cores, um deles é por meio de valores inteiros, que é justamente o tipo dos nossos rótulos. Portanto, podemos utilizar esse valores para mostrar os grupos no gráfico:
# codigo omitido
plt.scatter(usuarios[:, 0], usuarios[:, 1], c=rotulos)
plt.show()
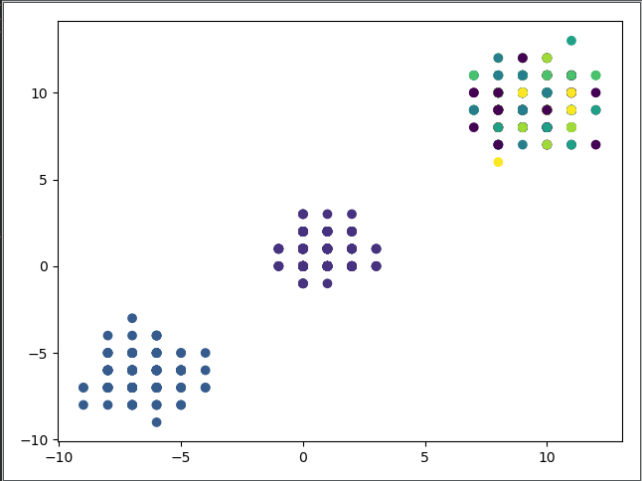
Com as cores no gráfico, podemos ver os grupos que foram formados.
Para saber mais
Nesse nosso caso foram formados oito grupos, que é o padrão do KMeans. Podemos ajustar o número de grupos passando um parâmetro nomeado no construtor da classe. Por exemplo, podemos falar que queremos, ao invés de oito, formar quatro grupos. Para isso, basta falar que o número de clusters (n_clusters) vale quatro:
# codigo omitido
modelo = KMeans(n_clusters=3)
Plotando o gráfico agora, veremos que temos apenas três grupos formados:
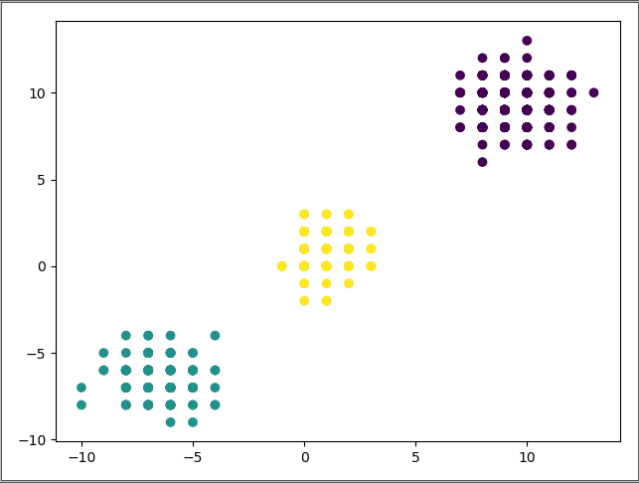
Além do K-médias, existem outros algoritmos que a SciKit implementa. Cada um deles tem seu próprio meio de agrupar os dados.
O aprendizado não supervisionado é uma das áreas no aprendizado de máquinas. Com ele, conseguimos rotular nossos dados e agrupá-los. Aqui na Alura, temos uma formação em aprendizado de máquina.
Nela você verá desde estatística, até o aprendizado de máquinas supervisionados com classificação.
