

Onde eu trabalho, todos os links acessados por qualquer computador da empresa são armazenados em um mesmo arquivo de registro na rede, o acessos.log, para maior controle do que os funcionários andam acessando durante o horário de trabalho. O log está organizado desta forma:
https://alura.com.br
http://instagram.com
https://www.alura.com.br
http://google.com
https://gmail.com
...
Uma vez por semana, checamos todo esse registro. Uma das verificações consiste em ver quais sites foram acessados sem o protocolo de segurança HTTPS.
Para facilitar isso, criamos um script em Python utilizando nossos conhecimentos sobre compreensão de lista, leitura de arquivos e o método de string startswith(), que verifica se uma string começa com uma determinada substring passada no parâmetro:
registro = open(‘acessos.log’, ‘r’)
sites_sem_https = [url for url in registro if url.startswith('http://')]
Podemos agora checar o primeiro link:
print(sites_sem_https[0])
E temos como resposta:
http://instagram.com
Ok! Apareceu o primeiro site que foi acessado apenas com HTTP. Se quiséssemos saber os próximos resultados, poderíamos, também, fazer um laço sobre toda a lista.
O problema da memória
Tudo certo, até que, por desorganização, ficamos algumas semanas sem fazer a checagem. Quando fomos verificar, o arquivo acessos.log já tinha mais de 5 GB! Tentamos rodar nosso código e olha o que aconteceu:
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
MemoryError
Recebemos uma exceção de tipo MemoryError! O Python não conseguiu fazer o que queríamos. Mas por que esse problema ocorreu?
Isso é porque a compreensão de lista armazena todos os valores de uma vez, ao mesmo tempo. Assim, se todos os links acessados fossem sem HTTPS, por exemplo, a memória RAM de nossa máquina ficaria ocupada de mais 5 GB, lentificando (e muito) nosso computador.
Como podemos solucionar todo esse problema, então?

Imaginando uma solução com lazy evaluation
Por enquanto, lemos nosso arquivo de registro linha por linha e armazenamos as linhas em uma lista. Estamos, então, iterando sobre nosso arquivo, isto é, repetindo o mesmo procedimento sobre ele para se obter cada linha.
Conseguimos fazer isso porque nosso arquivo aberto no Python é um iterável, um tipo de objeto que possibilita a ação de repetição sobre seus elementos, como listas e strings.
No Python, um objeto é considerado iterável se ele implementa o método __iter__, permitindo, por exemplo, que um loop for seja executado sobre ele.
Sabendo disso e considerando nosso problema com a memória do computador, uma solução hipotética seria ter um iterável que nos permitisse gerar uma URL por vez a cada iteração, à medida do necessário.
Esse tipo de lógica, na computação, tem nome - avaliação preguiçosa, ou, em inglês, lazy evaluation.
A avaliação preguiçosa, como já indica o nome, atrasa o processamento de uma expressão até que o resultado seja de fato necessário. Então como podemos utilizar dessa técnica no Python?
Implementando iteradores no Python
No Python (e, na verdade, em diversas outras linguagens), temos o conceito de iterador. Um iterador é sempre um iterável, mas que produz um valor a cada vez que é usado como argumento da função nativa next().
Um iterador deve sempre implementar o método next(), no Python 2, ou __next__(), no Python 3. Esse método deve retornar a exceção StopIteration quando não há mais valores para o iterador produzir.
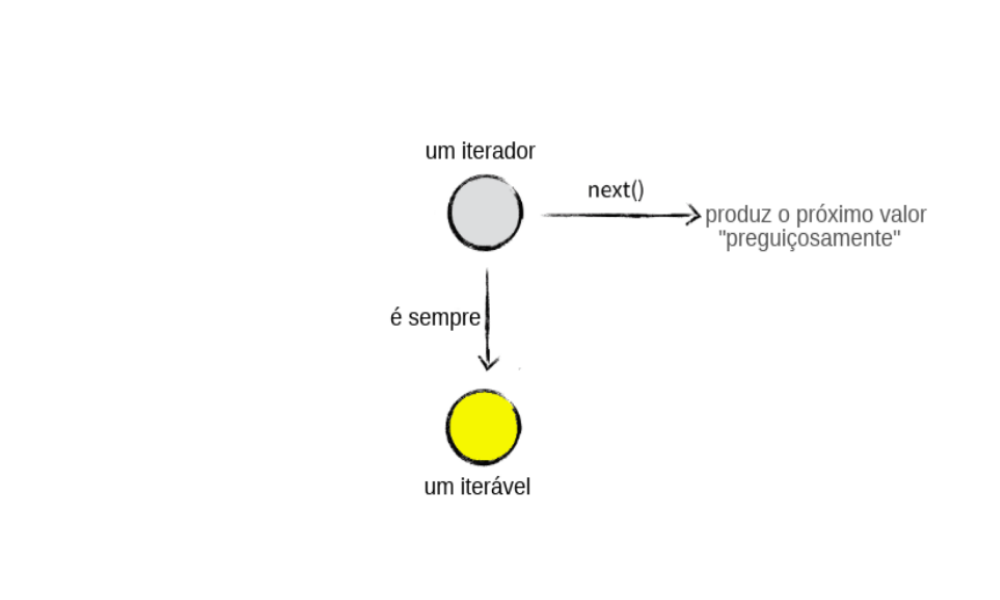
É com um iterador que o nosso problema de memória é facilmente solucionado! O iterador vai computar apenas um valor por vez, ou seja, vai usar a avaliação preguiçosa para gerar a próxima URL através da função next().
Mas como podemos criar um iterador que faça o que queremos, então? Temos que criar uma classe que contenha um método __iter()__ para ser um iterável, e o método __next()__ para ser um iterador.
Como o método __iter__() serve para retornar um iterador e nossa classe será, de fato, um iterador, faremos com que ele retorne o próprio objeto. No caso do método __next()__, implementaremos o código que devolverá uma linha que queremos por vez:
class IteradorHttp():
def __init__(self):
self.registro = open(‘acessos.log’, ‘r’)
self.linha_atual = ‘’
def __iter__(self):
return self
def __next__(self):
self.linha_atual = self.registro.readline()
while self.linha_atual and not self.linha_atual.startswith(‘http://’):
self.linha_atual = self.registro.readline()
if self.linha_atual:
return self.linha_atual
raise StopIteration
iterador = IteradorHttp()
Assim, podemos ir pegando (e, na verdade, gerando) URL por URL com a função next():
print(next(iterador))
print(next(iterador))
E o resultado é:
http://instagram.com
http://google.com
Certo! Mas o que acontece se tentarmos dar next() em um iterador que já acabou de produzir seus valores? Vamos ver:
print(next(iterador))
E o resultado:
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
StopIteration
Recebemos uma exceção do tipo StopIteration, nos indicando que já não há mais o que ser gerado pelo iterador, como previsto. Podemos evitar essa exceção passando um segundo parâmetro à função next(), que substituirá a impressão do StopIteration:
print(next(iterador, ‘Fim do iterador’))
Dessa vez:
Fim do iterador
Como esperado!
Como um iterador também é um iterável, podemos passar pelos elementos dele com um for, de forma que esse problema da exceção já é automaticamente resolvido:
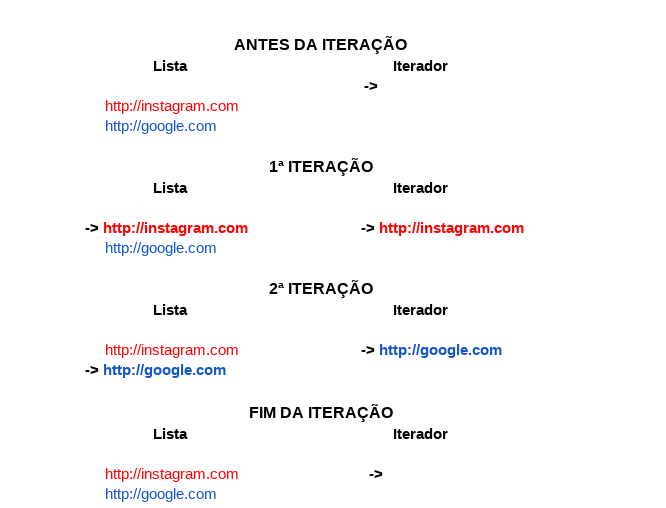
for url in iterador:
print(url)
O resultado:
http://instagram.com
http://google.com
Deu certo! O que acontece é que o próprio for usa a função next() para ir pegando os valores, mas para de iterar quando não há mais valores para gerar.
Para entender de fato a diferença entre a iteração que fazíamos antes e a que estamos fazendo agora, vamos fazer uma simulação:
Para saber mais
Conseguimos resolver nosso problema com iteradores, mas tivemos que escrever um código bastante complexo para criar nosso iterador. Será que não há uma maneira mais fácil?
Frente a toda essa complicação, o Python nos trouxe uma maneira muito mais simples de criar iteradores, através de geradores. Usando um gerador, podemos criar nosso iterador com poucas linhas de código.
Conclusão
Nesse post, conhecemos uma alternativa para a lista (e também para a funcionalidade de compreensão de lista!) que consegue poupar memória, trabalhando de outro jeito. Podemos até concluir que é boa prática usar iteradores em leitura de arquivos, por garantia.
Além disso, entendemos o que são iteráveis e iteradores, e até demos uma espiada nos geradores!
Quer aprender mais sobre conjuntos e listas no Python? Se se interessou pelo assunto e gostaria de entender mais sobre tópicos similares, dê uma olhada em nossos posts no blog sobre operações básicas com listas, como adicionar elementos em uma lista, diferença entre == e is no Python, ordenação de lista e compreensão de lista.
E aí? Gostou de conhecer essa funcionalidade no Python? Quer se aprofundar mais na linguagem? Na Alura, temos diversos cursos sobre Python que você pode aproveitar muito, confira!