Persistência poliglota com PHP: implementando buscas, mensageria, bancos de dados de grafos e colunares
Implementando buscas textuais - Apresentação
Boas-vindas à Alura! Me chamo Vinícius Dias e vou guiar vocês neste curso sobre Persistência Poliglota com PHP. Por motivos de acessibilidade, vou me auto descrever:
Audiodescrição: Vini se descreve como um homem branco de cabelo escuro e curto, com bigode e cavanhaque. Está vestindo uma camisa preta com a inscrição em marrom, PHPest, com alguns detalhes visuais remetendo ao Nordeste Brasileiro.
O que vamos aprender?
- Conexão, indexação de documentos e buscas em Bancos de Dados de Busca Textual (Elasticsearch);
- Banco de Dados Colunares (Wide-column Database);
- Mensageria;
- Banco de Dados de Grafos (Graph Database)
Se deseja aprender a se conectar a diversos tipos de bancos de dados utilizando PHP, este curso é ideal para você. Abordaremos a conexão com bancos de dados de busca textual, como o Elasticsearch (Busca Elástica), explorando a indexação de documentos e execução de buscas nesse tipo de banco de dados.
Aprenderemos sobre o Wide-Column Database (Coluna Larga), um tipo de banco de dados colunar, e exploraremos os cenários nos quais podem ser úteis. Além disso, discutiremos sobre mensageria, que, embora não seja um banco de dados propriamente dito, pode ser considerada uma forma de persistência. Mensagens ficam armazenadas em filas até que sejam consumidas, e abordaremos a produção e consumo dessas mensagens.
No final, abordaremos um tipo de banco de dados um pouco diferente, o banco de dados de grafos. Exploraremos os cenários em que esses bancos de dados são utilizados. Inclusive, como demonstrado na tela, realizaremos alguns relacionamentos.
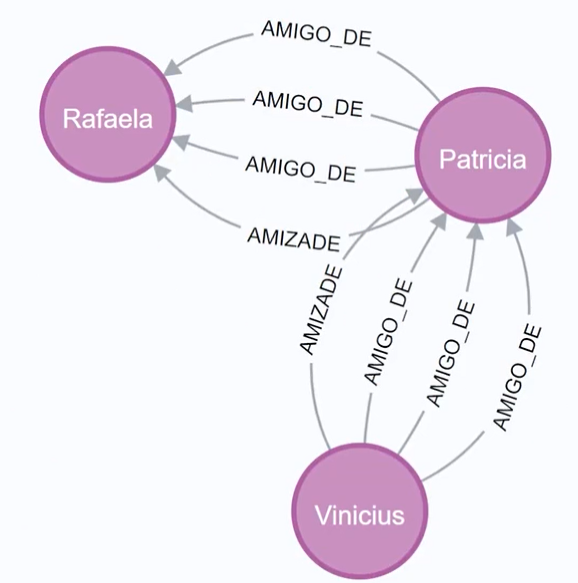
Em um cenário de rede social, por exemplo, podemos ter usuários com relacionamentos entre eles. A proposta é sugerir amigos para uma dessas pessoas usuárias, e exploraremos como isso pode ser feito com um banco de dados de grafos.
Pré-requisitos para este curso
É importante que para continuar, você já tenha feito o curso anterior de persistência poliglota, onde aprendemos sobre vários mecanismos de persistência, vários bancos de dados com PHP. Lá, temos toda a base para continuar esse projeto.
Portanto, é importante que você tenha feito esse curso e tenha um sólido conhecimento de Docker, porque vamos utilizar Docker para instalar nossas dependências, para ter cada um dos nossos bancos de dados em funcionamento.
Tire suas dúvidas!
Tendo compreendido tudo o que é necessário saber e o que aprenderemos neste curso, convidamos você a assistir com atenção cada uma das aulas. Em caso de dúvidas sobre como o PHP interage com esses bancos de dados, sugerimos que você abra uma dúvida, inicie um tópico ou uma conversa em nosso fórum, ou participe de nosso servidor no Discord, onde a interação é mais dinâmica.
Um detalhe importante que não podemos deixar de mencionar: este não é um curso de bancos de dados, onde ensinaremos como utilizar, configurar bancos de dados, criar queries, etc. É um curso que destaca a interação do PHP com diversos bancos de dados.
Desejo que você absorva muito conhecimento. Conto com a sua presença na próxima aula, onde começaremos a prática, trabalhando com bancos de dados de busca textual.
Implementando buscas textuais - Configurando o banco
Olá, pessoal! Boas-vindas de volta.
Agora que já configuraram o projeto, vamos levantar o seguinte cenário: imaginem que estão criando uma loja virtual ou até mesmo um blog, algo mais simples. Nesse contexto, muito provavelmente, terão uma pesquisa, onde poderão digitar, por exemplo, o nome de um produto que desejam encontrar, ou o nome de um post no blog que querem buscar. Portanto, terão buscas textuais.
É viável realizar buscas textuais mais simples utilizando um banco de dados relacional, com índices de full text (texto completo) e demais recursos. No entanto, existem ferramentas e mecanismos de persistência dedicados para buscas textuais.
Nesta aula, nos conectaremos ao mecanismo de persistência mais renomado do mercado para buscas textuais, o Elasticsearch.
Podemos pesquisar por "Elasticsearch PHP" para descobrir como se conectar ao Elasticsearch usando PHP, mas preferimos mostrar diretamente na documentação. Acessamos no navegador o site elastic.co e clicamos em "documentação" na parte superior, onde encontraremos informações sobre Elasticsearch.
Descendo consideravelmente, encontramos a seção denominada "Elasticsearch: Store, Search, and Analyze" (Armazene, Busque e Analise). Dentro desse menu, um dos tópicos é "Elasticsearch Clients" (Clientes do Elasticsearch). Clicamos neste link para mais detalhes.
Encontramos todos os clientes oficiais para Elasticsearch, e um deles, em Active Clients (Clientes Ativos), é o de PHP. Clicamos em "PHP Client" nele e temos um botão Get Started (Comece Agora). Agora sim, clicando nesse botão, estamos na documentação para esse cliente do Elasticsearch .
Notem que ele está utilizando a versão 8.10, que no momento da gravação é a que estamos utilizando. Recomendamos que utilizem também a 8.10, só para garantir que tudo será compatível.
A primeira coisa que a documentação nos orienta a fazer é instalar o componente do Elasticsearch. Mas antes de instalar esse componente, temos um outro detalhe. Se nos conectarmos a algum servidor Elasticsearch, precisamos ter a infraestrutura adequada, não é mesmo?
Agora, encontrada a documentação e conhecendo o ponto de partida para a parte do PHP, configuraremos nossa infraestrutura.
Configurando a infraestrutura
Abrimos o arquivo docker-compose.yml em nosso projeto. Nele, criamos um novo serviço chamado busca_textual, representando o tipo de banco de dados que utilizaremos.
Recapitulando, já temos serviços de PHP, que é onde rodamos nossos códigos, temos o Relacional, ChaveValor*, em_memoria e documentos. Agora, criaremos um para busca_textual. Buscaremos a imagem de Elasticsearch.
Conforme indicado na documentação, podemos buscar um caminho mais completo. Ao selecionar Image (Imagem) no Elasticsearch, ele encontra automaticamente o servidor necessário. A versão específica que utilizaremos é o elasticsearch:8.10, sendo esta a mais recente no momento da gravação, com a versão .2. Portanto, utilizaremos a versão 8.10.2.
#código omitido
busca_textual:
image: elasticsearch:8.10.2
Agora, destacamos alguns detalhes essenciais para a operação contínua do nosso banco. Foi desenvolvido um environment (ambiente), no qual são inseridas variáveis de ambiente, sendo primordial configurar xpack.security.enabled=false inicialmente.
Isso viabiliza a conexão descomplicada com o Elasticsearch, dispensando a configuração de credenciais e a utilização de HTTPS, simplificando o processo. Em um cenário de produção, essas configurações estariam ativadas, tornando obrigatório o emprego de HTTPS e a necessidade de credenciais.
Outro detalhe é o modo de descoberta do Elasticsearch. Estudando mais sobre isso, entenderão melhor. Mas, basicamente, queremos apenas um nó do Elasticsearch. Então, informamos que o discovery.type é igual a single-node.
#código omitido
busca_textual:
image: elasticsearch:8.10.2
environment:
- xpack.security.enabled=false
- discovery.type=single-node
Essas configurações são essenciais para o funcionamento do Elasticsearch, o próximo passo consiste em abrir o terminal e inserir docker compose up -d.
docker compose up -d
Isso subirá todos os containers, sendo crucial assegurar o correto funcionamento do serviço de busca textual. Para isso, usamos docker compose logs -f busca_textual no terminal.
docker compose logs -f busca_textual
Isso para garantir que os índices estão sendo criados. Observem nas últimas mensagens de retorno no terminal, que as mensagens precisam ser algo do tipo: adding index template [logs] for index patterns…. Ou seja, adding index e alguma outra informação.
Teclamos "Ctrl + C" para sair dos logs no terminal e voltamos ao código.
Agora que o banco está operacional, podemos retomar aquela fase. Com uma conexão estabelecida, o servidor Elasticsearch está ativo. Instalamos a dependência no PHP para facilitar a conexão com o Elasticsearch, digitando:
composer require elasticsearch/elasticsearch
Conforme indicado na documentação , na seção "Installation".
Conforme observado no curso anterior, surge um desafio ao utilizar o Docker enquanto instalamos as dependências com um composer local. Nesse caso, ocorrerá uma notificação alegando a ausência de extensões como Mongo e Memcached. Contudo, é sabido que essas extensões estão presentes no Docker.
Assim, basta copiarmos as informações fornecidas no retorno do terminal, incluindo as opções --ignore-platform-rec=ext-redis, --ignore-platform-rec=ext-memcached e --ignore-platform-rec=ext-mongodb.
composer require --ignore-platform-req=ext-redis --ignore-platform-req=ext-memcached --ignore-platform-req=ext-mongodb elasticsearch/elasticsearch
Faremos isso para informar que estamos instalando uma nova dependência e que não há necessidade de se preocupar com as extensões que precisamos.
Deixando a instalação ocorrer, minimizaremos o terminal e exibiremos o conteúdo do nosso composer.json .
composer.json
{
"require": {
"ext-pdo": "*",
"ext-redis": "*",
"ext-memcached": "*",
"ext-mongodb": "*",
"mongodb/mongodb": "^1.16",
"aws/aws-sdk-php": "^3.280",
"elasticsearch/elasticsearch": "^8.10",
"ext-cassandra": "*"
},
"config": {
"allow-plugins": {
"php-http/discovery": true
}
}
}
O Elasticsearch já foi adicionado. O aviso é emitido porque no require do PHP, especificamos que o PHP precisa de extensões como pdo, redis, memcached e mongodb.
Retornando ao terminal, a versão 8.10 está instalada novamente. No seu caso, execute composer require elasticsearch/elasticsearch:^8.10 para instalar a versão mais recente do 8.10.
Conclusão
Com o cliente do PHP instalado, e o servidor em execução. Entenderemos como nos conectar ao servidor Elasticsearch através do PHP no próximo vídeo.
Até mais!
Implementando buscas textuais - Conexão com ElasticSearch
Nossa infraestrutura está configurada. Voltaremos à documentação para discutir o Elasticsearch (Mecanismo de persistência de dados). Trata-se de um banco de dados específico para buscas textuais, amplamente empregado, por exemplo, em pesquisas realizadas em lojas ou blogs.
Contudo, o Elasticsearch também é bastante aplicado em diversos contextos quando não nos conectamos ao código para acessá-lo, como na leitura de logs (Registros de eventos). É comum integrar várias ferramentas ao Elasticsearch para buscar logs de uma aplicação. Essa prática é frequente em alguns cursos de monitoramento e observabilidade oferecidos na Alura.
Conectando ao Elasticsearch a partir do PHP
De volta ao nosso cenário de conexão ao Elasticsearch a partir do PHP, criaremos um novo arquivo em nosso projeto chamado busca_textual , mantendo o padrão estabelecido no curso anterior de nomear conforme o tipo de banco de dados.
busca_textual.php
<?php
declare(stricy_types=1);
A primeira ação a ser realizada consiste em empregar o require_once 'vendor/autoload.php';. Realizaremos o require do autoload do composer para poder utilizar o client do Elasticsearch.
Precisamos criar exatamente esse client. Criaremos uma variável client proveniente do clientBuilder. Observe que esse ClientBuilder pertence ao namespace elastic/elasticsearch. Possuímos um ClientBuilder e invocamos o método estático create().
busca_textual.php
<?php
declare(strict_types=1);
require_once 'vendor/autoload.php';
$client = \Elastic\Elasticsearch\ClientBuilder::create()
Este é um construtor de client. Podemos fornecer configurações, como o endereço do nosso banco de dados Elasticsearch, por meio do método setHosts().
Espera-se um array neste ponto, pois, seguindo o exemplo do memcached ou redis, é bastante simples termos vários servidores de Elasticsearch. Configurar dessa maneira é fácil, bastando passar um array de servidores.
Em nossa situação, será apenas um servidor. O único item desse array será uma string contendo http://busca_textual:9200.
busca_textual.php
<?php
declare(strict_types=1);
require_once 'vendor/autoload.php';
$client = \Elastic\Elasticsearch\ClientBuilder::create()
->setHosts(['http://busca_textual:9200'])
O Elasticsearch disponibiliza uma API HTTP, uma API REST. Por essa razão, começamos com http://. O endereço corresponde ao nome do serviço estabelecido no docker-compose. No arquivo de busca textual, especificamente, definimos esse endereço como o host, cujo nome no docker-compose é busca_textual.
A porta de acesso é indicada pelo sufixo :9200, padrão utilizado pelo Elasticsearch. Embora seja possível alterar essa configuração, no nosso cenário, optamos por manter a configuração padrão.
Outras configurações podem ser estabelecidas. Por exemplo, ao invocar o método setAPIKey(), é possível utilizar uma API Key de um novo serviço do Elasticsearch. Se houver credenciais, o método setCredentials está disponível, assim como o setCABundle() para definir certificados em relação à segurança.
Todas as informações referentes à conexão podem ser especificadas no nosso ClientBuilder. No nosso contexto, a única configuração necessária é o método setHosts(). Ao chamar o método build(), estamos construindo nosso client.
busca_textual.php
<?php
declare(strict_types=1);
require_once 'vendor/autoload.php';
$client = \Elastic\Elasticsearch\ClientBuilder::create()
->setHosts(['http://busca_textual:9200'])
->build();
Com o client pronto, tentamos realizar uma operação simples, como acessar os índices usando o método indices(), $client->indices()->create(). No método create(), é necessário fornecer alguns parâmetros, os quais devem ser passados em formato de array.
Diversos parâmetros podem ser fornecidos, mas a única obrigatória é o nome do índice. No código, passaremos um index e seu nome, denominado meu_indice, dentro do array associativo no método create(). Este processo é bastante simples.
O método create() retorna uma response. Vale lembrar que o Elasticsearch disponibiliza uma API REST para interação. Assim, realizaremos uma requisição HTTP e receberemos uma resposta. Podemos utilizar um var_dump para visualizar essa response ou exibir seu conteúdo com echo.
busca_textual.php
<?php
declare(strict_types=1);
require_once 'vendor/autoload.php';
$client = \Elastic\Elasticsearch\ClientBuilder::create()
->setHosts(['http://busca_textual:9200'])
->build();
$response = $client->indices()->create([
'index' => 'meu_indice',
]);
var_dump($response);
echo $response;
Tentaremos executar esse procedimento, acessando o arquivo e verificando os resultados, conforme visto no curso anterior. Para isso, clicamos com o botão direito do mouse no arquivo de código e escolhemos as opções "Run > busca_textual.php".
Obtemos como retorno:
O retorno abaixo foi parcialmente transcrito. Para conferi-lo na íntegra, execute o código na sua máquina
} {"acknowledged": true, "shards_acknowledged":true,"index":"meu_indice"} Process finished with exit code 0
No final, ao exibir essa resposta como string, observamos que o sistema recebeu a mensagem confirmando a criação do índice chamado meu_indice. Em resumo, tudo ocorreu conforme esperado, e o índice está agora criado.
O var_dump revela que o status dessa resposta é OK, com o código HTTP 200, indicando que o processo foi bem-sucedido. Com isso, temos um índice pronto para armazenar documentos.
Para fazer uma comparação, podemos pensar no índice como um equivalente ao banco de dados em nosso ambiente relacional, como o MySQL. Assim como criamos um banco de dados no MySQL, aqui criamos um índice, onde podemos armazenar diversos tipos de documentos. Para ilustrar, suponhamos que desejamos armazenar usuários e, posteriormente, buscar esses usuários pelo nome.
Conclusão
Na próxima aula, abordaremos esse cenário específico. Vamos salvar um documento do tipo usuário e tentar localizar esse usuário realizando uma busca no Elasticsearch.
Até o próximo vídeo!
Sobre o curso Persistência poliglota com PHP: implementando buscas, mensageria, bancos de dados de grafos e colunares
O curso Persistência poliglota com PHP: implementando buscas, mensageria, bancos de dados de grafos e colunares possui 134 minutos de vídeos, em um total de 47 atividades. Gostou? Conheça nossos outros cursos de PHP em Programação, ou leia nossos artigos de Programação.
Matricule-se e comece a estudar com a gente hoje! Conheça outros tópicos abordados durante o curso:
- Implementando buscas textuais
- Usando banco de dados colunares
- Implementando o serviço de mensageria
- Usando banco de dados de grafos
- Usando diferentes bancos