ORM com Node.js: desenvolvendo uma API com Sequelize e SQLite
Conhecendo o Sequelize - Apresentação
Boas-vindas ao curso de API Rest com ORM, utilizando Node, Express e Sequelize.
Audiodescrição: Juliana Amoasei é uma mulher branca, de olhos castanhos e cabelos curtos, lisos e pintados de azul. Usa óculos com moldura fina e arredondada, na cor preta. Possui brincos e piercings nas orelhas e nariz. Está com uma camiseta preta e está no estúdio da Alura.
Para quem é este curso?
- Começando os estudos de back-end com Node.js
- Já criou as primeiras APIs
- Quer aprender a usar novas ferramentas, tipos de banco etc.
Este curso é ideal para pessoas que estão iniciando seus estudos de back-end com Node.js, já praticou a criação das primeiras APIs nos cursos anteriores desta formação e deseja aprender a utilizar novas ferramentas, outros tipos de banco de dados e afins.
O que vamos aprender?
- O que são ORMS e como são utilizados
- Como integrar uma API a um banco
- Como utilizar ORM na integração
- Especificidades no uso do ORM no desenvolvimento de API
- Os métodos utilizados para conectar com um banco
- Principais características de bancos SQL
- Praticar com as principais partes de uma API: modelos, rotas e controllers
- Organizar o código padrão MVC
- Utilizar conceitos de orientação a objetos
Neste curso, vamos aprender o que são ORMs e como eles são utilizados no desenvolvimento de uma API. Além de integrar nossa API a um banco de dados pré-existente utilizando um ORM.
Vamos explorar o conceito de um ORM para a integração, as especificidades que a utilização do ORM apresenta no desenvolvimento de uma API, seu impacto no código, e os métodos do ORM que empregamos, no caso específico, o Sequelize, para estabelecer conexões com um banco de dados SQL e realizar várias consultas.
Também abordaremos a compreensão das principais características dos bancos de dados SQL e a forma como lidamos com eles. Continuaremos praticando com elementos essenciais de uma API, incluindo modelos, rotas e controladores.
Além disso, organizaremos nosso código seguindo o padrão MVC e aplicaremos conceitos de orientação a objetos para torná-lo reutilizável e bem estruturado.
O que você precisa saber?
- Fundamentos do JavaScript
- Orientação a objetos
- APIs Rest com Node.js
- HTTP
- Comandos do terminal
Para obter o máximo proveito deste curso, é necessário ter uma base sólida em fundamentos do JavaScript, como arrays, objetos, tipos de dados, bem como em orientação a objetos, incluindo a criação de classes e construtores de classe.
Esses temas foram tratados em cursos anteriores desta formação, bem como o conhecimento em APIs, que é aconselhável que você já tenha, pois iremos construir a partir do entendimento das APIs REST com Node.js.
O curso sobre HTTP, que também faz parte desta formação, é outro pré-requisito sugerido.
Adicionalmente, é importante ter experiência e habilidade na utilização dos comandos do terminal, na navegação entre diretórios e na execução de comandos no Node.js.
Aproveite os recursos da plataforma:
Não deixe de aproveitar os recursos adicionais disponíveis em nossa plataforma, como o material complementar aos vídeos, bem como o suporte oferecido no fórum e na comunidade do Discord.
Agora, vamos começar!
Conhecendo o Sequelize - Apresentando o projeto
Neste curso, iremos desenvolver o sistema de uma plataforma de vídeos relacionados à programação.
Contextualizando
Ao considerar o produto, destacam-se dois elementos essenciais nessa plataforma: os conteúdos de cursos e as pessoas que interagem com esses conteúdos.
Essas pessoas podem ser categorizadas principalmente em dois grupos: aquelas que visualizam os cursos e aquelas que ministram as aulas.
Considerando um curso, podemos pensar em várias características que ele pode ter.
Um curso pode ter um tema, pessoas interagindo especificamente com ele, por exemplo: quem conduz o curso e quem se matriculou nele, entre várias outras propriedades. Pessoas, cursos, pagamentos, matrículas, tudo isso são dados.
Se são dados, precisamos mantê-los em algum banco de dados, que pode ser escolhido de acordo com a necessidade e os requisitos do uso.
Essa base de dados requer acesso e gestão adequados. Os dados representam a parte fundamental de qualquer produto ou empresa, quando se considera sua importância. Portanto, temos o produto definido. Agora, com base no conhecimento prévio adquirido em cursos anteriores sobre a API, revisitaremos alguns conceitos.
Revisando os conceitos de das partes fundamentais de uma API
Os componentes fundamentais de uma aplicação, em resumo, consistem em:
- Front-end, que corresponde à interface com a pessoa usuária,
- Back-end, responsável por mediar a comunicação entre o front-end e o banco de dados, que representa a camada final.
Todo o valor do produto está na base de dados e tudo o que interage com essa base precisa ser protegido, gerenciado e bem cuidado.
Para recapitular o processo:
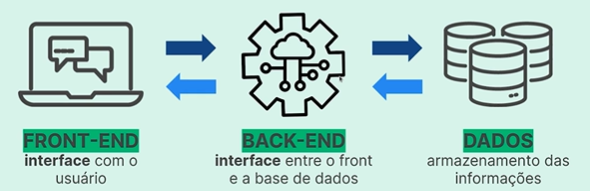
O front-end encaminha uma solicitação ao back-end (por exemplo, a pessoa usuária deseja fazer uma compra, obter informações ou visualizar uma postagem em uma rede social). O back-end então transforma essa solicitação em uma requisição de dados à camada de dados.
A camada de dados, que armazena as informações, recebe essa solicitação e a encaminha de volta para o back-end. O back-end administra esses dados, os formata de maneira que o front-end possa compreender e, por fim, o front-end os apresenta de forma acessível para a pessoa usuária da aplicação.
Naturalmente, posteriormente, esse esquema fundamental se expande conforme o escopo da aplicação, seu público, sua natureza e outros fatores relevantes. Isso inclui considerações sobre arquitetura, hospedagem, computação em nuvem e assim por diante, mas esses são os elementos essenciais.
O que construiremos neste curso?
No curso, iremos construir uma API Rest para facilitar a integração dos dados com o front-end. Focaremos na interação da API com um tipo de base de dados específica, que será apresentada durante o curso.
Pré-requisitos para o projeto
Antes dessa etapa, na atividade anterior intitulada "Atividade preparando ambiente", preparamos um vídeo com instruções sobre a instalação das ferramentas que serão utilizadas.
Além disso, disponibilizamos o link para um repositório no GitHub onde você pode encontrar nossa aplicação inicial, localizada na branch "arquivos-iniciais".
Por gentileza, baixe o repositório. Você irá cloná-lo e baixá-lo no seu computador, porque esses arquivos iniciais serão a base do nosso projeto.
Como já aprendemos a subir um servidor basico com o Express e a criar algumas rotas, para não precisarmos reescrever tudo aqui, vou fornecer esses arquivos prontos.
Analisando os arquivos iniciais no VSCode
Vamos abrir o Visual Studio Code (VSC) para dar uma analisada rápida no conteúdo dos arquivos iniciais.
Como já sabemos, aprendemos a criar um servidor local com o Express, e temos o arquivo server.js com esse servidor pronto para ser iniciado localmente.
server.js
const app = require('./src/app.js');
const PORT = 3000;
app.listen(PORT, () => {
console.log('servidor escutando!');
});
Além disso, temos a pasta src à esquerda, com o arquivo app.js.
app.js
const express = require('express');
const app = express();
app.use(express.json());
app.get('/teste', (req, res) => {
res
.status(200)
.send({ mensagem: 'boas-vindas à API' });
});
module.exports = app;
Neste arquivo, estamos iniciando uma rota de teste básica, um tipo de rota get com o Express, e deixamos nossa aplicação pronta para receber middlewares do Express. Já trabalhamos com isso nos cursos anteriores.
Há uma pasta chamada arquivos-base, com alguns arquivos que chamamos de seeder:
- entidades.png
- seederCategorias.js
- seederCursos.js
- seederMatriculas.js
- seederPessoas.js
Mais adiante no curso, utilizaremos esses arquivos e descobriremos o que são os seeders. Também há um arquivo .png (entidades.png) com um diagrama do nosso Mínimo Produto Viável (MVP), que é o que vamos desenvolver durante o curso.
O diagrama contém informações sobre pessoas, cursos e outras propriedades que essas pessoas e cursos podem ter e será frequentemente consultado.
Além disso, temos o arquivo .gitignore, que evita que a pasta node_modules seja enviada para seu repositório.
Há também um arquivo de configuração do .eslintrc.json, que é verificador do estilo do nosso código, para deixá-lo bem organizado.
Por último, temos o arquivo package.json. Este é o nosso arquivo de manifesto, onde já preparamos a instalação de três dependências:
package.json
{
"name": "api-express-sequelize",
"version": "1.0.0",
"description": "",
"main": "server.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1",
"dev": "nodemon server.js"
},
"keywords": [],
"author": "",
"license": "ISC",
"dependencies": {
"express": "4.18.2"
},
"devDependencies": {
"eslint": "8.46.0",
"nodemon": "3.0.1"
}
}
O Express, para iniciar o servidor desde o início; ESlint, nosso verificador estático de código; e Nodemon, uma ferramenta que usamos para dar auto-refresh no nosso servidor local sempre que houver uma alteração, facilitando o desenvolvimento do nosso projeto.
Também há um script que preparei para iniciar este servidor, um script chamado dev, que executará o Nodemon em server.js ("dev": "nodemon server.js").
Já aprendemos tudo isso em cursos anteriores.
Instalação do projeto
Agora, retornaremos ao nosso terminal. Já clonamos e baixamos o repositório, e entramos no terminal, na pasta certa, onde estão nossos arquivos (node-sequelize). Vamos instalar usando o comando npm install.
npm install
Essa instalação deve ser bastante rápida, pois essas dependências são relativamente pequenas, com exceção do Express.
Com tudo instalado, podemos executar o script que está no package.json, que é npm run dev, para ver se nosso servidor local é iniciado.
npm run dev
O servidor se iniciou, o Nodemon já notificou isso:
servidor escutando!
Observem que essa mensagem está dentro do arquivo server.js.
Podemos realizar um teste rápido no navegador indo para o endereço localhost:3000/test. Lembrando que test é a rota que deixamos pronta no arquivo app.js.
localhost:3000/test
Tudo está funcionando conforme o esperado em relação à rota que preparamos em app.js e a mensagem. Obtemos a seguinte mensagem no navegador:
mensagem: "boas-vindas à API"
Tudo está configurado.
No entanto, antes de começarmos a codificar nossa API, dois avisos importantes:
Vamos abrir a documentação para entender melhor.
No curso, estamos utilizando a versão 6 do Sequelize. É importante mencionar que, no momento da gravação, a versão 7 do Sequelize estava em fase alfa, o que significa que ainda não estava pronta para ser utilizada em nenhum contexto, pois estava em estágio inicial de desenvolvimento.
Portanto, nossa referência é a versão 6, que é a atual no momento do curso, e não há previsão de lançamento para a versão 7. Se você se deparar com algum código Sequelize que precise ser modificado durante o seu trabalho, é muito provável que esse código esteja na versão 6 ou na versão 5.
Portanto, nossa base é a versão 6 neste curso.
Procure também verificar se você está utilizando a mesma versão do Node que eu, vou interromper meu servidor rapidamente apenas para fazer um teste com o comando node -v.
node -v
No meu caso, estou utilizando a versão 18.7.1. No módulo "Preparando o Ambiente", existem instruções caso você precise gerenciar as versões do Node.
Sobre a versão do Sequelize, utilizaremos a v6 e a versão 18.17.1 do Node. Uma coisa que talvez já tenha notado no código, é que estou utilizando o CommonJS para importar e exportar módulos no JavaScript, ao invés do ECMAScript Modules.
app.js
const express = require('express');
// código omitido
Isso se percebe facilmente, pois uso o padrão const, nome da constante, igual a require() para controle de módulos, ao invés do import-export.
Por que estou usando CommonJS e não import-export? Porque algumas ferramentas específicas do Sequelize, como a ferramenta de linha de comando que utilizaremos neste curso, funcionam melhor com CommonJS e ainda não se adaptaram tão bem ao import-export.
Também é para mantermos uma compatibilidade com a documentação, que por enquanto está toda usando CommonJS.
Mas após entendermos como cada exportação de módulos funciona, caso queira utilizar algum dos métodos alternativos que podem ser feitos para usar o Sequelize com import-export, posso disponibilizar material extra, caso tenha interesse.
Agora que esclarecemos esses pontos, estamos prontos para começar?
Então, vamos lá!
Conhecendo o Sequelize - Conhecendo o Sequelize
Neste momento, já temos um servidor local com o Express em funcionamento e uma rota básica estabelecida. Conversamos também sobre o Sequelize, uma das ferramentas que será bastante abordada neste curso.
Mas qual seria exatamente a nossa necessidade do Sequelize?
Retornemos à discussão sobre dados. Conforme discutimos anteriormente, pessoas são dados, cursos são dados, e assim por diante.
Dados
Há diversas formas de organizar, coletar, armazenar e persistir dados, a depender do que precisamos fazer com eles. Será necessário um acesso rápido? Há uma grande quantidade de dados para lidar? É preciso fazer cache de dados?
Uma das maneiras mais comuns de armazenar dados é utilizando bancos de dados do tipo SQL, também chamados de bancos de dados relacionais.
Structured Query Language (SQL)
Utilizaremos esse tipo de banco de dados neste curso para persistir os dados da nossa API, armazenando informações sobre as pessoas, cursos e outros elementos relacionados.
A característica principal do SQL é o uso de tabelas para armazenar os dados, organizados em linhas e colunas. Caso se pergunte, sim, podemos compará-lo ao Excel. Por exemplo:
| id | nome | cpf | |
|---|---|---|---|
| 1 | Frodo Baggins | frodo@shire.me | 12345678912 |
| 2 | Samwise Gamgee | sam@shire.me | 23456789123 |
| 3 | Meriadoc Brandybuck | merry@shire.me | 34567891234 |
| 4 | Peregrin Tük | pippin@shire.me | 45678912345 |
No entanto, um banco de dados SQL normalmente não é acessível através de um arquivo comum. São servidores específicos para armazenar esses tipos de dados e possuem métodos próprios para acessar esses dados.
Uma exceção é o SQLite, um tipo de banco de dados SQL que utilizaremos neste curso e será abordado com mais detalhes mais tarde.
Por exemplo, as pessoas em nosso banco de dados serão armazenadas em uma tabela de pessoas com informações únicas sobre elas, cada pessoa tem um identificador único, um ID, que é utilizado para identificar esse registro na tabela.
Uma pessoa tem um nome, um e-mail e um CPF. Assim sendo, não podemos ter duas pessoas com o mesmo CPF ou o mesmo e-mail no banco de dados.
Outro ponto importante é que o próprio nome SQL se refere a uma linguagem específica: SQL (Structured Query Language), ou Linguagem de Consulta Estruturada. É uma linguagem para consultas, consultas em bancos de dados do tipo SQL.
SELECT `id`, `nome`, `email`, `cpf` FROM `users`;
INSERT INTO `users` (`id`,`nome`, `email`, `cpf`) VALUES ("Gandalf", "gandalf@arda.ea", "56789123456");
A linguagem SQL, assim como a linguagem de programação, também pode ter seus tipos de condicionais, seus tipos de dados, pode trabalhar com variáveis, mas é muito diferente do JavaScript.
const mysql = require('mysql');
const conexao = //dados da conexão
conexao.query(
INSERT INTO 'users' ('id', 'nome', 'email', 'cpf')
VALUES ('Gandalf', 'gandalf@arda.ea', '56789123456');',
(error, results) => {
// código
});
Dessa forma, para realizarmos consultas ao banco usando nosso back-end, devemos lembrar do CRUD (Create (criar), Read (ler), Update (atualizar) e Delete (apagar)), que são as operações básicas que fazemos na API com dados.
Então, como podemos unir as duas coisas? Precisamos nos conectar com o banco de dados SQL usando a linguagem SQL para fazer as consultas e temos o JavaScript, que é a linguagem que utilizamos na nossa API.
Como juntar JavaScript e SQL?
Poderíamos, por exemplo, utilizar uma biblioteca Node.js, uma vez que estamos empregando uma API desenvolvida em Node.js.
O Node.js dispõe de uma biblioteca para operações com SQL. Poderíamos empregar essa biblioteca e seu método denominado query para inserir uma string que representasse um código SQL diretamente em um código JavaScript.
Essa string seria interpretada pelo método query. Essa abordagem funcionaria? Sim.
Poderíamos, inclusive, ter variáveis, usar template strings, entre outros recursos. No entanto, há outra abordagem que será explorada neste curso.
const pessoa = new Pessoa();
const novaPessoa = {
nome: 'Gandalf',
email:'gandalf@arda.ea',
cpf: 156789123456',
};
pessoa.create(novaPessoa);
Seria interessante termos uma forma de abstrair as consultas, os comandos escritos em SQL, para que não precisássemos nos preocupar em escrever consultas em SQL.
Porque, embora as consultas simples sejam mais sucintas e nós consigamos identificar facilmente o que elas fazem, as consultas em SQL podem ficar complexas.
Portanto, seria mais tranquilo e rápido para nós, pessoas desenvolvedoras, se existisse uma maneira de fazermos isso usando apenas nossa linguagem de programação, no caso, o JavaScript.
Ao invés de inserir um código SQL dentro de um código JavaScript, simplesmente poderíamos criar uma nova instância de uma classificação em JavaScript, pegar um objeto no formato Objeto JavaScript, inserir os dados dessa nova pessoa nesse objeto. Em seguida, passar esse objeto para dentro de um método do próprio JavaScript.
Portanto, conseguimos interpretar ou analisar esse código e entender: bom, isso é apenas JavaScript, posso lidar melhor e mais rapidamente com isso, sem precisar trabalhar com SQL no meio de tudo isso.
Nesse ponto, entra em cena a ferramenta que vamos usar, o SQLite. SQLite é um ORM.
ORM (Object-Relational Mapping)
ORM significa Object-Relational Mapping (Mapeamento Objeto Relacional).
Portanto, o mapeamento é tanto a técnica quanto a ferramenta que utilizamos. Trata-se literalmente de fazer o mapeamento de dados entre uma base de dados relacional e uma plataforma, em uma linguagem orientada a objetos, ou que utilize, entre outros, o paradigma de orientação a objetos em seu core.
**Cada linguagem desenvolve seu próprio ORM. **
O SQLite é amplamente utilizado em JavaScript e também oferece suporte ao TypeScript. Portanto, JavaScript e TypeScript têm outros ORMs, mas o SQLite é muito usado.
Portanto, é a ferramenta que utilizaremos para fazer esse mapeamento entre SQL e a linguagem JavaScript.
Cada ORM tem seus próprios métodos, classes e sua própria sintaxe. Mas as ferramentas básicas que eles oferecem são parecidas.
Por que usamos ORMs?
- aumento na produtividade
- maior legibilidade
- abstração ajuda na manutenção
- segurança nos inputs
Primeiramente, iremos abstrair as funcionalidades do SQL para uma biblioteca (lib) que utilizaremos com métodos em JavaScript. Isso reduz consideravelmente a curva de aprendizado e acelera o processo de desenvolvimento, pois a lib realizará muitas tarefas automaticamente.
Dessa forma, a conexão com o banco de dados, o tratamento de tipos, datas, entre outros aspectos, tornam a curva de aprendizado mais suave em comparação com a necessidade de aprender a escrever queries SQL detalhadas.
O código se torna mais legível ao utilizarmos nossa linguagem de programação e sua sintaxe, juntamente com os métodos, em vez de reescrever as queries em SQL. Além disso, essa abstração facilita a manutenção do código.
Facilita a adição de funcionalidades e a modificação de qualquer coisa, porque se tivermos que alterar a consulta, corremos o risco de errar ao modificar a query.
Obviamente, se você conhece muito bem SQL, não terá esse problema. Mas para um time com várias pessoas, onde nem todos têm a habilidade de escrever e entender como SQL funciona, a manutenção é muito mais tranquila.
Lembrando que isso é quase sempre feito em equipes, portanto, não é só você modificando o código, há várias outras pessoas envolvidas.
Por fim, os ORMs nos auxiliam a prevenir certos tipos de ataques específicos do SQL, como as SQL Injections. Deixaremos mais materiais sobre esse assunto nas atividades extras.
ORM não é a solução perfeita
- abstração adiciona complexidade;
- flexibilidade limitada a alguns usos;
- SQL ainda é necessário;
Quando o ORM pode não ser tão bom ou não ser tão recomendado?
Por exemplo, toda a estrutura da lib, ou seja, essa abstração que o ORM cria sobre a camada de dados e a biblioteca adicionada à aplicação, pode resultar em um fenômeno chamado de overhead (sobrecarga) quando há um uso excessivo de recursos, como memória, capacidade de processamento e até largura de banda de transmissão.
Quando introduzimos excessos, a execução de uma consulta SQL pode ser retardada, uma vez que além da própria consulta SQL, há uma camada de abstração que precisa ser traduzida.
O uso normal dessas consultas não costuma ser problemático, mas quando é necessária uma lógica mais complexa e as consultas SQL tornam-se igualmente complexas, pode começar a surgir um problema.
Em operações básicas de CRUD, que fazemos na maior parte das APIs Rest, isso não costuma ser um problema.
Vale lembrar que as ORMs trabalham com um conjunto de funcionalidades mais limitadas comparadas a escrever SQL do zero, ou seja, ela está normalmente mais atrelada a casos comuns, especialmente os de CRUD.
Portanto, não é um problema utilizar um ORM para CRUD, como construímos e como as APIs Rest funcionam a maior parte do tempo.
No entanto, consultas complexas podem precisar ser escritas à mão, usando SQL. Para isso, ainda podemos usar um intermédio do ORM para colocar essas consultas dentro do código. Ou seja, a SQL continua necessária.
Não será necessário escrever todas as consultas em SQL. O ORM realizará a maior parte do trabalho, mas ainda é importante compreender pelo menos o essencial sobre como essa linguagem de consulta funciona.
A vantagem é que podemos aprender isso gradualmente enquanto utilizamos o ORM.
Porém, a SQL continua sendo um ponto de atenção. Talvez não seja necessário, neste momento, dominar a escrita de consultas complexas, mas é fundamental compreender como as consultas simples funcionam.
Conclusão
Agora que já temos o projeto e identificamos o problema, temos uma ideia mais clara do produto que pretendemos desenvolver. É hora de começarmos a utilizar a ferramenta.
Vamos lá!
Sobre o curso ORM com Node.js: desenvolvendo uma API com Sequelize e SQLite
O curso ORM com Node.js: desenvolvendo uma API com Sequelize e SQLite possui 193 minutos de vídeos, em um total de 59 atividades. Gostou? Conheça nossos outros cursos de Node.JS em Programação, ou leia nossos artigos de Programação.
Matricule-se e comece a estudar com a gente hoje! Conheça outros tópicos abordados durante o curso:
- Conhecendo o Sequelize
- Criando um modelo
- Desenvolvendo a API
- Relações e associações
- Atualizando a API