Hugging Face: treinando modelos em diferentes ambientes com Accelerate
Conhecendo os dados de inferência - Apresentação
Olá! Neste curso, vamos construir um projeto de NLP (Natural Language Processing, ou seja, Processamento de Linguagem Natural) para criarmos um modelo zero-shot que realize classificações personalizadas. Ele terá um foco na tarefa de compreensão de análises de clientes em uma plataforma de vendas.
Para que você me conheça melhor, eu sou João Miranda. Vou acompanhar você durante todo o curso, então não se preocupe.
Audiodescrição: João se declara um homem branco. Tem cabelo curto ondulado e barba curta. Está vestindo uma camisa azul. Ele está sentado em uma cadeira gamer com encosto preto e branco. Atás dele, a parede está iluminada por luzes de LED azul e verde. Na parede também tem uma placa da Árvore Branca de Gondor (Senhor do Anéis) com escritos em élfico ao redor.
O projeto
Durante o projeto, utilizaremos modelos pré-treinados e realizar transferência de aprendizado em novos dados. O aspecto mais interessante será a utilização da biblioteca Accelerate, que permite a execução do código em ambientes distribuídos e com múltiplas GPUs.
Ao final do projeto, construiremos uma aplicação com Gradio, que podemos ver abaixo:
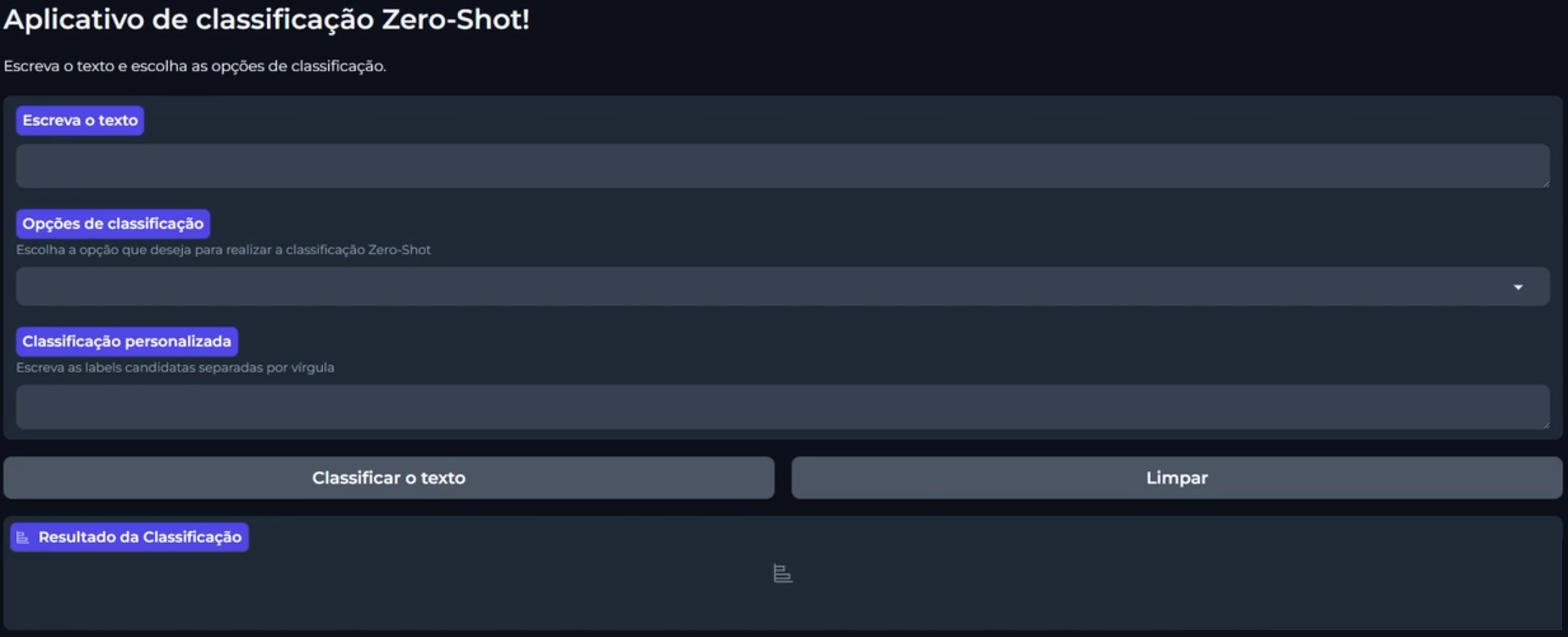
No primeiro campo dessa aplicação, podemos escrever um texto. Em seguida, podemos selecionar o tipo de classificação entre "Satisfação", "Motivo da mensagem" e "Classificação personalizada". O terceiro é onde podemos colocar nossa classificação personalizada.
Abaixo dos campos, temos os botões "Classificar o texto" e "Limpar. Ao clicarmos em "Classificar o Texto", o modelo identificará qual classificação realizar e nos retornará o resultado. Por exemplo, podemos preencher da seguinte forma:
Escreva o texto: Pelo custo-benefício, o preço é realmente muito bom.
Opções de classificação: Satisfação
Classificamos pela satisfação da pessoa cliente e clicarmos no botão "Classificar o Texto". Abaixo dos botões, temos o campo "Resultado da Classificação", onde indicou que o texto é uma "satisfação do cliente". Embaixo ainda aparece linhas indicando o nível de satisfação e insatisfação que levaram ao resultado.

Se quisermos inserir uma classificação personalizada, podemos rodar outro exemplo:
Escreva o texto: O produto veio com defeito, quero um reembolso imediato
Opções de classificação: Classificação personalizada
Classificação personalizada: Problemas técnicos,Consultas,Reclamações,Reembolso
Selecionamos que seria uma "Classificação personalizada" e, no campo indicado, passamos as categorias que queremos classificar: problemas técnicos, consultas, reclamações e reembolso. Ao clicarmos no botão "Classificar o Texto", o modelo identificará e realizará a classificação escolhida. No caso, como reembolso.

O que faremos
Para criar essa aplicação, passaremos por diversas etapas:
- Aplicar a tokenização de textos;
- Transferência de aprendizagem de modelos de linguagem;
- Criação de um modelo zero-shot;
- Configuração de uma função de looping de treinamento com a Accelerate.
Com esse looping, permitiremos que nosso código seja executado em diversos ambientes, seja com GPU ou em vários computadores.
O foco do curso será na tarefa de classificação de textos, portanto, não abordaremos a criação de modelos de imagem ou de áudio.
Pré-requisitos
Para acompanhar o conteúdo, os pré-requisitos necessários são:
- Conhecimento na linguagem de programação Python;
- Conhecimento em Machine Learning.
Vamos começar?
Conhecendo os dados de inferência - Carregando os dados
Uma loja virtual está buscando soluções para melhorar os serviços prestados e entender os pontos positivos e negativos dos produtos disponíveis na plataforma de vendas. Atualmente, as pessoas clientes podem enviar análises dos produtos que compraram, mas não existe uma maneira de analisar esses dados de forma eficiente.
Nosso papel neste projeto é criar um modelo de IA capaz de classificar essas análises. Este modelo precisa realizar duas tarefas de classificação.
- Identificar se a clientela está satisfeita ou não e;
- Entender o motivo da análise deixada pela clientela.
Planejando nosso modelo
Como podemos criar um modelo capaz de realizar duas tarefas de classificação diferentes? Podemos criar um modelo zero-shot, que consegue classificar dados de forma personalizada. Assim, com o mesmo modelo, será possível escolher qual tipo de classificação será feita e, a partir disso, encontrar o resultado que queremos.
Para realizar essa tarefa, utilizaremos dados de inferência linguística que contêm premissas, hipóteses e uma label. A label indica se a premissa:
- Implica na hipótese;
- É neutra ou;
- É uma contradição.
Esses dados estão disponíveis na plataforma do Hugging Face, na base multilingual-NLI-26lang-2mil17. Portanto, acessaremos a base multilingual-NLI no Hugging Face.
Essa é uma base de dados de inferência linguística que contém línguas de vários países. Nela, escolheremos apenas a língua portuguesa. Na aba "Dataset Card" podemos filtrar, clicando em "Split" no canto superior esquerdo.
Escolhendo a base de dados
Rolando pela lista, descobrimos cinco base de dados com a língua portuguesa: pt_anli, pt_fever, pt_ling, pt_mnli e pt_wanli. Cada uma dessas seleções que fazemos na base de dados veio de uma base de dados diferente, que era bem maior também.
Então, essa base de dados faz uma seleção de amostras de várias bases de dados e agrupa em uma mesma base. Mas utilizaremos somente uma parcela desses dados, que será o pt_anli. Não vamos utilizar os outros dados da língua portuguesa.
Faremos isso porque, mesmo utilizando uma base de dados de 25 mil linhas, como essa, demorará muito tempo na etapa de treinamento do nosso modelo. Se utilizarmos muitos dados, o modelo ficará mais robusto e com uma precisão melhor, mas também demorará muito tempo na parte de treinamento.
Então, para o nosso escopo do nosso projeto, entenderemos como construímos esse modelo, mas construiremos o modelo mais eficiente possível, porque isso demandaria muito processamento. Nesse curso, utilizaremos o Benton Lab, com apenas uma única GPU.
Copiando a base de dados
Como podemos fazer a leitura dessa base de dados pt_anli. Após selecioná-la, a página atualiza com os dados filtrados e, na parte superior direita, temos a aba "Files and versions" (Arquivos e versões). Clicando nela, vamos para outra página com uma lista de pastas e arquivos.
A primeira pasta na lista é a "data". Clicando nela, teremos todos os arquivos de base de dados. Desceremos até o final da página e pediremos para carregar mais arquivos até encontrarmos o arquivo com começo pt_anli-00000.
Esse arquivo é um parquet. Clicaremos nele, vamos para outra página, onde temos uma mensagem na parte superior do arquivo:
This file is stored with Git LFS. It is too big to display, but you can still download it.
Traduzindo, esse arquivo está armazenado no Git LFS e é muito grande para ser mostrado aqui, mas podemos fazer o download. Clicaremos com o botão direito sobre o link que está na palavra "download" e selecionaremos a opção "Copiar endereço do link". Será a partir dele que faremos a leitura dos dados.
Abrindo a base de dados no Google Colab
Agora que copiamos o caminho do arquivo, voltaremos ao ambiente do Colab. A primeira etapa que precisamos fazer é a instalação da biblioteca datasets, que será necessária para fazermos a leitura dessa base de dados. Para isso, na primeira célula escreveremos:
!pip install -q datasets
Depois, executaremos com o "Ctrl + Enter". Enquanto está instalando, já podemos construir os outros códigos. Na próxima célula escreveremos a importação da função para leitura da base de dados:
from datasets import load_datasets
Resolvendo o erro de instalação da biblioteca
Enquanto escrevíamos, a biblioteca datasets estava sendo instalada, mas tive um erro, que aparece no final do retorno, em vermelho. Ele explica que houve uma incompatibilidade de versões.
Para resolver esse problema e não termos nenhum problema executando nossos códigos, na barra superior do Colab, clicaremos em "Ambiente de execução > Reiniciar sessão". No centro da tela aparece uma janela de confirmação e clicaremos em "Sim", no canto inferior direito.
Ao fazermos isso, ele aplicará a instalação da biblioteca, que fizemos, e colocar as versões mais atualizadas que acabamos de instalar.
Após reiniciarmos a sessão, podemos deixar o código da primeira célula comentado, colocando uma hashtag (#) no começo da linha da biblioteca datasets, podendo seguir para a execução da célula de importação da função load_datasets, pressionando "Ctrl + Enter" com a célula selecionada
# !pip install -q datasets
from datasets import load_datasets
Lendo a base de dados
Agora podemos fazer a leitura dessa base de dados. Primeiro, armazenaremos o caminho daquele arquivo em uma variável chamada url. Então, em uma nova célula, vamos escrever url = '' e colar o caminho que copiamos do Hugging Face entre as aspas, com "Ctrl + V". Por fim, executaremos a célula.
url = 'https://huggingface.co/datasets/MoritzLaurer/multilingual-NLI-26lang-2mil7/resolve/main/data/pt_anli-00000-of-00001-21ca95ba4e8fa69b.parquet'
Depois disso, podemos fazer a leitura dessa base de dados. Em uma nova célula, escreveremos:
dados = load_datasets('parquet', data_files = url)
Dentro dos parênteses, passamos o tipo de arquivo que faremos a leitura. Como faremos a leitura de um arquivo parquet, escrevemos 'parquet', entre aspas. Como segundo parâmetro, passamos o caminho do arquivo, escrevendo data_files = url. Ao executarmos essa célula, o load_datasets fará a leitura somente da parte dos dados que desejamos.
É muito interessante utilizar essa forma para leitura do arquivo, caso contrário ele fará o download de toda a base de dados para depois fazermos a filtragem só da parte dos dados que queremos. Utilizando o data_files filtramos somente para essa parte dos dados do pt-anli.
Identificando o formato dos dados
Após fazer a leitura dos dados, identificaremos o formato dos dados, visualizando os nossos dados. Em uma nova célula, escreveremos dados e executaremos com "Ctrl + Enter".
dados
DatasetDict({ train: Dataset({ features: ['premise_original', 'hypothesis_original', 'label', 'premise', 'hypothesis'], num_rows: 25000 }) })
Retornou a informação de que é um DatasetDict com o nome de train. Ela tem 5 features:
premise_original(premissa original),hypothesis_original(hipótese original),label,premise(premissa),hypothesis(hipótese).
Tem dados duplicados: a premissa original e premissa, assim como a hipótese original e hipótese. Analisaremos o que é cada uma dessas informações. Além disso, recebemos a informação da quantidade de linhas: 25 mil linhas.
Acessando o dataset
Conseguimos fazer a leitura da base de dados. Para visualizarmos esses dados, em uma nova linha escreveremos:
dados['train'][0]
{ 'premise_original': 'Based on the evidence of the health threats of tobacco, based on the thousands of deaths from tobacco related diseases and the terrible toll that tobacco addiction takes on individuals in society, it is very difficult to imagine any reason for not supporting the bill and its important amendments to the Tobacco Act.', 'hypothesis_original': 'The health threats of tobacco are not known', 'label': 2, 'premise': 'Com base na evidência das ameaças à saúde do tabaco, com base nos milhares de mortes por doenças relacionadas ao tabaco e no terrível preço que a dependência do tabaco afeta os indivíduos na sociedade, é muito difícil imaginar qualquer motivo para não apoiar o projeto de lei e suas importantes alterações à Lei do Tabaco.', 'hypothesis': 'As ameaças à saúde do tabaco não são conhecidas' }
No caso, lemos apenas o primeiro elemento dessa base de dados, por isso o [0]. Ao executarmos essa célula, recebemos como retorno um dicionário com cada uma das informações que apareceram anteriormente.
Podemos identificar o que é cada uma daquelas features. Por exemplo, a premise_original e a hypothesis_original são textos em inglês. A label é um valor numérico. Por fim, a premise e hypothesis são os textos em português. O interessante nessa base de dados é que temos o dado em inglês e a tradução desse dado para a língua que escolhemos, no caso, Português.
Se quisermos visualizar todos os dados, podemos fazer é utilizar o pandas para transformar esses dados em uma tabela, deixando mais interessante.
dados['train'].to_pandas()
Executando com "Ctrl + Enter", temos uma tabela com os 25 mil dados. Em colunas diferentes temos a informação do texto em inglês, tanto da premissa, quanto da hipótese, a label e a premissa e a hipótese em português.
Já conseguimos fazer a leitura da nossa base de dados. No próximo vídeo começaremos a preparar esses dados para conseguirmos utilizá-la no nosso modelo de NLP.
Conhecendo os dados de inferência - Separando dados de treino e teste
Para aprimorar nosso entendimento das análises dos clientes da plataforma de vendas, realizamos uma leitura de uma base de dados de inferência linguística, contendo dados de premissa e hipótese. Esses dados serão muito úteis para construirmos um modelo de Zero-Shot Classification.
No momento da leitura dos dados, percebemos que há dados em inglês e em português, todos em uma mesma tabela de treinamento. É interessante, ao construirmos um modelo, ter dados de treinamento e também de validação, para avaliarmos o desempenho do nosso modelo após o treinamento.
Então, faremos a separação dos nossos dados em uma base de treinamento e validação, para conseguirmos fazer essa avaliação de desempenho posteriormente.
Filtrando os dados
O primeiro passo será filtrar os nossos dados, selecionando apenas os dados em português, pois os dados em inglês não serão utilizados para a construção do nosso modelo. Em uma nova célula, utilizaremos a função select_columns, da biblioteca datasets, para fazermos a filtragem somente das colunas que queremos. Armazenaremos esse resultado na mesma tabela dos dados selecionados.
dados_selecionados = dados.select_columns(['premise', 'hypothesis', 'label'])
dados_selecionados['train'].to_pandas()
Nos parênteses, passamos quais as colunas queremos utilizar, entre colchetes. Ao subirmos na nossa base de dados, vemos que os nomes das colunas são premise, hypothesis, que são os dados em português, e label que indica se a premissa está implicando na hipótese, se ela é neutra ou se é uma contradição.
Na mesma célula, abaixo dessa linha, escrevemos o código dados_selecionados['train'].to_pandas() para descobrirmos se a seleção foi feita corretamente. Ao executarmos com "Ctrl + Enter", recebemos como resultado uma tabela apenas com os dados que desejávamos: premise, hypothesis e label.
Inclusive, a ordem das colunas está diferente, com a label no final, por ser a ordem que passamos na função select_columns().
Separando os dados de treino e validação
Agora que já fizemos essa filtragem, resta fazer uma divisão dessa base de dados entre treino e validação. Na próxima célula, usaremos a função train_test_split(), que separa nossa base de dados em uma parcela que escolhemos uma porcentagem de dados para a parte de treino e uma parte desses dados para o teste.
dados_selecionados['train'].train_test_split(test_size=0.2, shuffle=True)
Passamos o tamanho da base de dados de teste, com test_size=0.2, e utilizamos o parâmetro shuffle=True para embaralhar os nossos dados antes de fazer essa separação. Ao executarmos a célula com "Ctrl + Enter", temos o resultado do DatasetDict().
DatasetDict({ train: Dataset({ features: ['premise', 'hypothesis', 'label'], num_rows: 20000 }), test: Dataset({ features: ['premise', 'hypothesis', 'label'], num_rows: 5000 }) })
Agora nossa base de dados está dividida. Uma parte de dados é para treino (train: Dataset), contendo as features que selecionamos e com um tamanho de 20 mil linhas. Outra parte é a base de dados de teste (test: Dataset), contento as mesmas features, mas com 5 mil linhas.
Porém, utilizando esse código, ele ainda não armazenou esse resultado em lugar nenhum, apenas retornou qual foi essa tarefa. Para salvar esse resultado, precisamos armazenar isso em uma variável. Em uma nova célula, escreveremos:
dados_selecionados = dados_selecionados['train'].train_test_split(test_size=0.2, shuffle=True)
dados_selecionados.
Os dados_selecionados recebe o código que escrevemos na célula anterior, então podemos apenas copiar e colar. E, para visualizarmos se foi armazenado corretamente, na linha abaixo pedimos o resultado. Executando com "Ctrl + Enter", recebemos os mesmos resultados.
Observando as tabelas
Para vermos as duas tabelas separadamente, podemos utilizar o pandas. Em uma nova célula, codaremos:
dados_selecionados['train'].to_pandas()
Ao executarmos essa célula, recebemos a tabela com as 20 mil linhas dos dados que foram armazenados na base de dados de treino. Podemos repetir o processo para visualizarmos a base de dados de teste, trocando train por test:
dados_selecionados['test'].to_pandas()
Ao executarmos com "Ctrl + Enter", recebemos uma tabela com as 5 mil linhas dos dados de teste que utilizaremos para validar o nosso modelo de Machine Learning (Aprendizado de Máquina).
Conclusão
Agora temos uma base de dados filtrada com somente os dados que precisamos, em português. Também já conseguimos separar os dados entre treino e teste. Agora temos duas tabelas organizadas para conseguirmos construir o nosso modelo de NLP (Processamento de Linguagem Natural).
Mas os dados continuam em um formato que o modelo ainda não conseguirá processar. Então, na próxima aula, continuaremos com esses processamentos e transformar nossa base para ser possível fazer o treinamento do nosso modelo de IA.
Sobre o curso Hugging Face: treinando modelos em diferentes ambientes com Accelerate
O curso Hugging Face: treinando modelos em diferentes ambientes com Accelerate possui 152 minutos de vídeos, em um total de 49 atividades. Gostou? Conheça nossos outros cursos de IA para Dados em Inteligência Artificial, ou leia nossos artigos de Inteligência Artificial.
Matricule-se e comece a estudar com a gente hoje! Conheça outros tópicos abordados durante o curso:
- Conhecendo os dados de inferência
- Preparando dados de texto
- Construindo loop de treinamento
- Treinando modelo Zero-Shot
- Desenvolvendo uma aplicação de classificação de texto