Estatísticas com R: correlação e regressão
Entendendo a reta - Apresentação
Boas-vindas ao curso Estatísticas com R: correlação e regressão. Meu nome é Marcelo Cruz, sou instrutor na Escola de Dados, e irei te acompanhar durante essa jornada de aprendizagem.
Audiodescrição: Marcelo se descreve como um homem de pele clara, com cabelo curto cacheado castanho-escuro, barba média castanho-escura, sobrancelhas castanho-escuras e olhos castanhos. Ele veste uma camisa preta, usa um headset preto, e está sentado em frente a uma parede branca iluminada em gradiente verde-claro e azul-claro.
Para quem é este curso?
Este curso foi desenvolvido para você, que deseja dar o próximo passo na carreira e ampliar seus conhecimentos na área de estatística, utilizando a linguagem R.
O que vamos aprender?
O objetivo do curso é a criação de modelos de regressão linear simples e múltipla, nos quais analisaremos os resultados e faremos previsões de valores.
No projeto, realizaremos a previsão de valores de imóveis de uma imobiliária.
Para melhor aproveitamento do conteúdo, recomendamos realizar as atividades disponibilizadas nas aulas, onde você encontrará textos complementares e exercícios práticos. O objetivo é que você tenha uma aprendizagem ativa.
Quais são os requisitos?
Este curso tem como requisito o curso Estatística com R: testes de hipóteses.
Conclusão
Em caso de dúvidas, acesse o fórum ou participe da nossa comunidade no Discord, onde você terá acesso à equipe de pessoas monitoras e a outras pessoas estudantes.
Contamos com você neste curso! Vamos começar?
Entendendo a reta - Conhecendo os dados
Recebemos dados de uma imobiliária com informações sobre vendas de imóveis, e nos foi dada a tarefa de precificar, ou seja, estimar os preços dos imóveis. Para isso, realizaremos três etapas:
- Identificar as características que ajudarão na precificação dos imóveis;
- Entender quais características têm mais influência na precificação;
- Precificar imóveis novos.
No entanto, antes de começar, precisamos conhecer os dados.
Conhecendo os dados
Começaremos com um notebook do Google Colab aberto com no projeto, onde disponibilizamos um texto introdutório para você se ambientar.
Tanto o projeto quanto os dados estarão disponíveis para acesso nas atividades desta aula.
Carregando o pacote dplyr
Para conhecer os dados, vamos primeiro carregar o pacote que será utilizado: o dplyr. Em uma nova célula, chamaremos a função library(dplyr) e executaremos o código.
# Carregando o pacote dplyr
library(dplyr)
Lendo os dados
O próximo passo será ler os dados. Ao baixar os dados na atividade, uma forma de fazer upload no Colab é acessando o menu lateral esquerdo, clicando em "Files", e depois no ícone para abrir a pasta dos arquivos. Feito isso, buscaremos o arquivo baixado que será utilizado: o precos_de_casas.csv.
Em uma nova célula, criaremos um dataset chamado dados e atribuiremos a ele (<-) a função read.csv(), passando entre parênteses o caminho dos dados.
Para obter o caminho, basta clicar no ícone ⁝ à direita do arquivo e selecionar a opção "Copy path". Por fim, colamos o caminho copiado entre parênteses e aspas simples.
# Lendo os dados
dados <- read.csv('/content/precos_de_casas.csv')
Dessa forma, o dataset é criado corretamente.
Exibindo os dados do dataset
Agora, vamos exibir o dataset. Para isso, chamaremos a função head(dados). Dessa forma, teremos acesso aos dados da imobiliária com informações dos imóveis.
# Exibindo o dataset
head(dados)
Visualização dos cinco primeiros registros da tabela. Para visualizá-la na íntegra, execute as células na sua máquina e utilize apenas
dados.
Id | area_primeiro_andar | existe_segundo_andar | area_segundo_andar | quantidade_banheiros | capacidade_carros_garagem | qualidade_da_cozinha_Excelente | preco_de_venda |
|---|---|---|---|---|---|---|---|
<int> | <dbl> | <int> | <dbl> | <int> | <int> | <int> | <dbl> |
| 1 | 79.5224 | 1 | 79.3366 | 2 | 548 | 0 | 1027905 |
| 2 | 117.2398 | 0 | 0.0000 | 2 | 460 | 0 | 894795 |
| 3 | 85.4680 | 1 | 80.4514 | 2 | 608 | 0 | 1101855 |
| 4 | 89.2769 | 1 | 70.2324 | 1 | 642 | 0 | 690200 |
| 5 | 106.3705 | 1 | 97.8237 | 2 | 836 | 0 | 1232500 |
| 6 | 73.9484 | 1 | 52.5814 | 1 | 480 | 0 | 704990 |
Os dados presentes no dataset incluem:
- O campo de ID (
Id);- A área do primeiro andar (
area_primeiro_andar);- A existência de segundo andar (
existe_segundo_andar);- A área do segundo andar (
area_segundo_andar);- A quantidade de banheiros (
quantidade_banheiros);- A capacidade de carros na garagem (
capacidade_carros_garagem);- A qualidade da cozinha (
qualidade_da_cozinha_Excelente);- E o preço de venda de cada imóvel (
preco_da_venda).
Conhecendo a estrutura dos dados
Para conhecermos melhor os dados e entendermos sua estrutura, podemos utilizar a função str() sobre dados em uma nova célula para ter essa visualização.
# Estrutura dos dados
str(dados)
Retorno da célula:
'data.frame': 1438 obs. of 8 variables:
$ Id : int 1 2 3 4 5 6 7 8 9 10 …
$ area_primeiro_andar : num 79.5 117.2 85.5 89.3 106.4 …
$ existe_segundo_andar : int 1 0 1 1 1 1 0 1 1 0 …
$ area_segundo_andar : num 79.3 0 80.5 70.2 97.8 …
$ quantidade_banheiros : int 2 2 2 1 2 1 2 2 2 1 …
$ capacidade_carros_garagem : int 548 460 608 642 836 480 636 484 468 205 …
$ qualidade_da_cozinha_Excelente: int 0 0 0 0 0 0 0 0 0 0 …
$ preco_de_venda : num 1027905 894795 1101855 690200 1232500 …
O retorno nos informa quantas observações temos; neste caso, são 1438 registros, organizados em oito campos, isto é, oito colunas. Abaixo, é indicado o tipo de dado de cada campo e são apresentados alguns exemplos iniciais. Por exemplo: o campo Id é do tipo int, area_primeiro_andar é num, existencia_segundo_andar também é int, entre outros.
Relembrando: a coluna area_primeiro_andar possui números fracionários. A existencia_segundo_andar é um campo binário, com valores 0 ou 1, assim como qualidade_da_cozinha_Excelente. Por outro lado, quantidade_banheiros é um número inteiro, como 2, 1, 3, e assim por diante. Da mesma forma, temos a coluna capacidade_carros_garagem.
Removendo o campo de Id
Um campo que não precisamos neste momento é o Id. Precisamos apenas dos campos com as características da casa e o preço de venda.
Para solucionar isso, podemos remover o campo do dataset. Em uma nova célula, faremos uma seleção sem esse campo e salvaremos no dataset dados.
Atribuindo um valor a dados, utilizaremos o operador pipe (%>%) e chamaremos a função select(), excluindo a coluna com o comando -Id.
# Removendo ID
dados <- dados %>% select(-Id)
Após executar o código, podemos verificar a estrutura tratada com str():
# Estrutura tratada
str(dados)
Retorno da célula:
'data.frame': 1438 obs. of 7 variables:
$ area_primeiro_andar : num 79.5 117.2 85.5 89.3 106.4 …
$ existe_segundo_andar : int 1 0 1 1 1 1 0 1 1 0 …
$ area_segundo_andar : num 79.3 0 80.5 70.2 97.8 …
$ quantidade_banheiros : int 2 2 2 1 2 1 2 2 2 1 …
$ capacidade_carros_garagem : int 548 460 608 642 836 480 636 484 468 205 …
$ qualidade_da_cozinha_Excelente: int 0 0 0 0 0 0 0 0 0 0 …
$ preco_de_venda : num 1027905 894795 1101855 690200 1232500 …
Agora, estamos sem o campo Id, que não será utilizado.
Conclusão
Durante o curso, nossa ideia é estimar o preço de venda com base nas características da casa. Nesse caso, temos sete campos (ou variáveis) para precificar e descobrir o valor de venda da casa.
No entanto, neste momento, não utilizaremos todas as sete variáveis para precificar os imóveis. A ideia é testar com apenas uma característica.
Ao precificar e verificar o valor de uma casa, um dos principais fatores observados é o tamanho do imóvel, ou seja, o metro quadrado. Portanto, o primeiro campo que testaremos e analisaremos para precificar o imóvel será a área do primeiro andar (area_primeiro_andar).
Mais adiante, podemos analisar e entender melhor as outras características.
Agora que definimos a primeira variável para testar a relação e precificar o imóvel, podemos entender o relacionamento entre a área do primeiro andar (area_primeiro_andar) e o preço de venda (preco_de_venda). Abordaremos esse tema no próximo vídeo!
Entendendo a reta - Verificando a lineariedade
Queremos estimar o preço de venda do imóvel. Para isso, utilizaremos a área do primeiro andar (campo area_primeiro_andar do dataset dados) como ponto de partida.
Verificando a linearidade
Qual será a relação entre essas duas variáveis? Para entender essa relação, utilizaremos duas abordagens. A primeira será uma abordagem visual, enquanto a segunda será numérica.
Neste vídeo, focaremos apenas na abordagem visual. Iremos usar um gráfico de dispersão para visualizar a distribuição dos dados entre a área do primeiro andar e o preço de venda.
Carregando o pacote ggplot2
De volta ao Google Colab, começaremos carregando o pacote que será utilizado: o ggplot2. Para isso, usaremos a função library() recebendo ggplot2 entre parênteses.
# Carregar o pacote ggplot2
library(ggplot2)
Criando um gráfico de dispersão
Na sequência, temos uma nova célula com o seguinte código:
# Criar o gráfico de dispersão - área do primeiro andar x preço de venda
ggplot(data = dados, aes(x = area_primeiro_andar, y = preco_de_venda)) +
geom_point() +
labs(
title = "Relação entre Preço e Área Primeiro Andar",
x = "Área do primeiro andar",
y = "Preço de venda"
)
Nesse código, chamamos a função ggplot() e passamos para ela os dados (data = dados). No eixo x, colocamos a area_primeiro_andar, enquanto no eixo y inserimos o preco_de_venda.
Em seguida, adicionamos as legendas do gráfico, com o título (title), a legenda do eixo x (x), que é "Área do primeiro andar", e também do eixo y (y), que é "Preço de venda".
Ao executar o código, recebemos o seguinte gráfico:
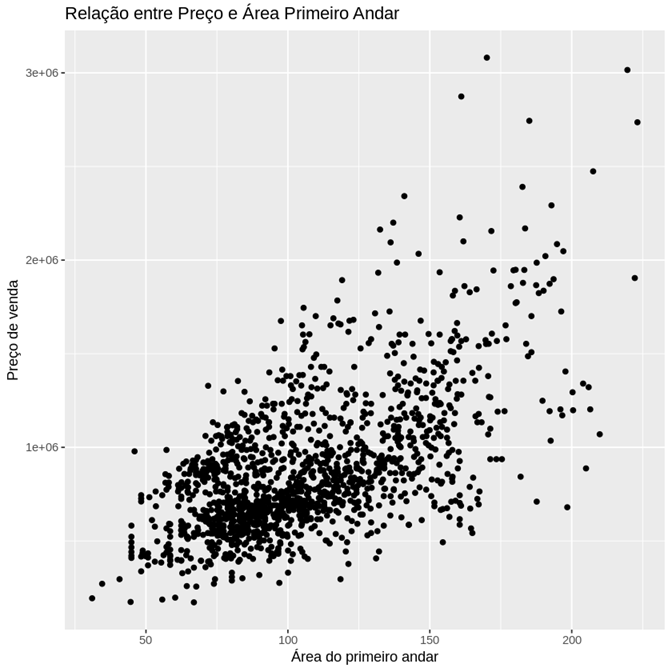
Criado o gráfico, percebemos a relação entre área do primeiro andar e preço de venda. Inicialmente, ao visualizar os dados, a relação segue uma distribuição no formato de reta. Conforme a área do primeiro andar aumenta, o preço de venda também sobe. Para visualizar melhor essa relação, podemos traçar uma linha reta nos dados, facilitando a identificação da tendência.
Traçando uma reta no gráfico de dispersão
Abaixo, temos o código preparado para a inclusão da reta:
# Traçar a reta no gráfico de dispersão
ggplot(data = dados, aes(x = area_primeiro_andar, y = preco_de_venda)) +
geom_point() +
geom_segment(aes(x = 66, y = 250000, xend = 190, yend = 1800000), color = "red", linewidth = 1) +
labs(
title = "Relação entre Preço e Área com Linha Reta Manual",
x = "Área do primeiro andar",
y = "Preço de venda"
)
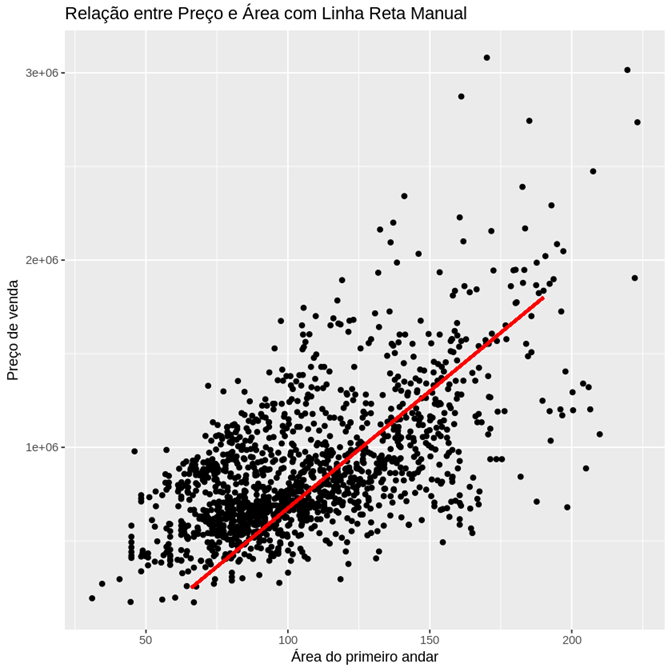
A reta foi criada de forma arbitrária, apenas para orientar a relação e a distribuição. Definimos um eixo x e um eixo y iniciais, onde a reta começa, e eixos x e y finais, onde a reta termina.
Conclusão
Com isso, conseguimos visualizar o formato de reta na relação entre a área do primeiro andar e o preço de venda. Este é um bom indício em relação aos dados.
No entanto, há um problema com a análise: ela é muito subjetiva. Pode ser que uma pessoa consiga visualizar a relação linear, enquanto outra não a identifique.
Portanto, seria interessante realizar a análise de forma mais objetiva, usando informações numéricas e diretas, que nos permitam entender melhor a relação sem depender da interpretação visual, que pode variar para cada pessoa.
Faremos essa análise mais objetiva e numérica a seguir!
Sobre o curso Estatísticas com R: correlação e regressão
O curso Estatísticas com R: correlação e regressão possui 70 minutos de vídeos, em um total de 53 atividades. Gostou? Conheça nossos outros cursos de Estatística em Data Science, ou leia nossos artigos de Data Science.
Matricule-se e comece a estudar com a gente hoje! Conheça outros tópicos abordados durante o curso:
- Entendendo a reta
- Regressão linear simples
- Métricas e testes
- Regressão linear múltipla
- Análise final