AWS Data Lake: criando uma pipeline para ingestão de dados
Preparando o ambiente na AWS - Apresentação
Olá, sou Ana Hashimoto.
Audiodescrição: Ana é uma mulher branca de cabelos longos lisos pretos e olhos pretos. Está vestindo uma blusa azul e usa brincos triangulares grandes e dourados e uma gargantilha dourada. Também está com uma maquiagem leve, destacada pelos olhos delineados e um batom vermelho. Está sentada em uma cadeira de encosto alto preto. No fundo desfocado, à direita há uma estante de estilo industrial com decorações de livros, plantas, um quadro, um enfeite com a logo da Alura e uma máquina de escrever. À esquerda há um vaso de plantas. A parede está iluminada por uma luz led azul claro.
Vou acompanhar você no curso AWS Data Lake: Pipeline para Ingestão de Dados, focado para pessoas que desejam aprender sobre AWS na prática. Neste curso, construiremos uma pipeline completa para ingestão de dados externos, utilizando serviços para garantir a segurança do ambiente cloud (nuvem):
- IAM;
- Lake Formation;
- S3;
- Conta AWS;
- Alerta de custos.
Para isso, usaremos uma base de dados chamada Data Boston, que contém seis anos de informações sobre diversas solicitações da cidade de Boston. A partir dessa base de dados, vamos construir nossa pipeline para ingestão de dados externos dentro da camada bronze do nosso Bucket S3. Além disso, faremos a configuração do Lake Formation e do usuário IAM, garantindo, assim, uma camada adicional de segurança dentro do ambiente AWS.
Ao fim do curso, você conseguirá construir uma pipeline completa de ingestão de dados externos na AWS, e terá aprendido sobre os serviços na prática. Para aproveitar o conteúdo, recomendamos que você tenha conhecimento em Python e Cloud Computing.
Vamos começar a nossa jornada?
Preparando o ambiente na AWS - Conhecendo o Data Boston
Somos pessoas engenheiras de dados contratadas para analisar uma base de dados do site Data Boston (Dados de Boston), que contém seis anos de informações sobre as solicitações de melhorias feitas pelas pessoas moradoras. Esta base de dados contém diversas informações, por exemplo, solicitações de melhorias na cidade, tais como falta de luz, pichações nos carros, entre outras solicitações.
Temos como desafio deste curso, analisar essa base de dados, para que seja possível a extração de insights. Como primeira etapa, entraremos no site Data Boston. Ao acessarmos o site, através do endereço data.boston.gov, clicaremos no botão de "Menu", no canto superior esquerdo, e clicaremos em "Organizations". Na página aberta, clicaremos na opção "Boston 311" e, na nova pasta, em "311 service requests" (Requisições de serviço 311).
Ao acessarmos a página 311 service requests, encontramos todas as informações e uma base de dados de 2011 até 2023. Solicitaram para nós, enquanto pessoas engenheiras de dados, analisarmos a base de 2015 até 2020. Neste caso, abriremos a amostra de 2015 para fazermos a análise.
Ao abrirmos o relatório "311 SERVICE REQUESTE - 2015", encontramos algumas informações, como os botões de "Download" e "Data API" (API de dados), na parte superior direita e, no centro superior, a fonte de onde essa informação foi extraída. Descendo um pouco a página, encontramos uma amostra das dez primeiras linhas do ano de 2015 em uma tabela de dados.
Nessa tabela, temos informações de como e quando a solicitação foi aberta, quando ela foi fechada, qual é o status, o motivo desta solicitação e o agrupamento correspondente. Por exemplo, temos uma solicitação de limpeza.
Movendo a tabela para direita, encontramos outros campos da tabela, como o agrupamento desta solicitação. Alguns exemplos são: construção, problema de água e sanitização. Assim, podemos ver que a base é muito completa, contendo informações desde agrupamentos, até informações mais granulares, como o tipo da solicitação, quando ela foi aberta, quando ela foi fechada e quem a abriu.
Dessa forma, temos uma base completa para que possamos iniciar nosso trabalho para a ingestão destes dados no nosso Data Lake no AWS e, de fato, a construção do nosso Data Lake. No próximo vídeo, faremos a construção dos próximos passos do pipeline para ingestão destes dados na AWS.
Preparando o ambiente na AWS - Entendendo a pipeline
Agora que já compreendemos a nossa base de dados do site Data Boston (Dados de Boston), percebemos que se trata de uma base com dados relacionais, que são dados estruturados. O desafio neste vídeo é entender a nossa arquitetura AWS. Como vamos construir a arquitetura para fazer a ingestão desses dados dentro do nosso Data Lake na AWS?
Vou acessar o Draw.io, que é um sistema amplamente utilizado para desenhos de arquitetura, desde arquiteturas on-premises até arquiteturas cloud. À esquerda da janela, há uma coluna com diversas opções de formatos na seção "Geral", por exemplo, triângulos e nuvens.
Rolando a coluna para baixo, encontramos também algumas opções de ícones dos serviços utilizados, por exemplo, ícones da AWS, na seção "AWS / Analytics". Isso facilita o entendimento da arquitetura AWS. No meio da tela do projeto que abri, no espaço de criação, temos o nosso primeiro desenho de arquitetura, que delineará como faremos a ingestão do site Data Boston.
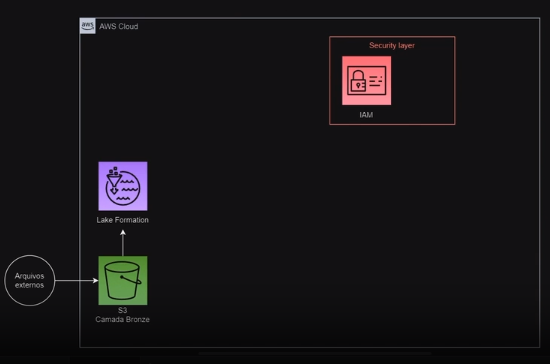
Na parte inferior esquerda, temos um círculo escrito arquivos externos. Este círculo de arquivos externos representa os dados de seis anos do site Data Boston. Para fazermos a ingestão destes dados, primeiramente vamos utilizar o Bucket S3, dentro da camada bronze, representado pelo ícone verde. Construiremos duas camadas: a camada bronze, que irá armazenar os dados brutos, e a camada silver, onde armazenaremos os dados processados posteriormente.
Acima do Bucket S3, temos o ícone do Lake Formation, que é um serviço na AWS bastante utilizado para construções de Data Lake. Com isso, obtemos diversos benefícios com a utilização deste serviço, como maior segurança dos dados e acesso aos nossos metadados. Dessa forma, conseguimos uma centralização dos dados e melhor gerenciamento das informações.
Por fim, na parte superior direita, em vermelho, temos o Security Layer (camada de segurança), que representa a nossa camada de segurança dentro da AWS. Para isso, utilizaremos o serviço chamado IAM, que é um serviço no qual conseguimos criar um usuário diferente do usuário raiz. Não é recomendado que você utilize o usuário raiz para nenhum serviço na AWS. Portanto, utilizaremos o serviço IAM para a criarmos de um usuário auxiliar, que criará esses dados para nós dentro do Data Lake.
Então, essa é a nossa arquitetura AWS. Já vimos que nossos dados são dados estruturados do site Data Boston, então faremos a ingestão na AWS dentro da camada bronze do nosso Bucket S3. No próximo vídeo, iniciaremos as configurações do nosso Data Lake.
Sobre o curso AWS Data Lake: criando uma pipeline para ingestão de dados
O curso AWS Data Lake: criando uma pipeline para ingestão de dados possui 92 minutos de vídeos, em um total de 46 atividades. Gostou? Conheça nossos outros cursos de SQL e Banco de Dados em Data Science, ou leia nossos artigos de Data Science.
Matricule-se e comece a estudar com a gente hoje! Conheça outros tópicos abordados durante o curso:
- Preparando o ambiente na AWS
- Extração, tratamento e carga dos dados no S3
- Estruturando o Data Lake
- Criando o banco de dados no Lake Formation
- Compreendendo os gastos associados