

Em toda área de atuação existem diversos problemas que devem ser enfrentados para alcançar um objetivo, e na área de Machine Learning não é diferente. Em diferentes contextos, podemos encontrar soluções que surgem de uma mesma origem. Ao explorar o vasto universo do aprendizado de máquina, identificamos uma técnica fundamental para resolver diversos problemas: a classificação. Neste artigo, vamos abordar os principais problemas resolvidos por algoritmos de classificação em Machine Learning, explorando como podem ser solucionados por meio de três categorias.
Classificação
A classificação faz parte de um conjunto de técnicas que aprendem a partir de exemplos, conhecido como Aprendizado Supervisionado. Neste tipo de aprendizado, sabemos quais são os nossos dados de entrada e também quais são os rótulos corretos. Ao treinar o modelo com base nos resultados conhecidos, é possível encontrar padrões nos dados, pois o processo envolve o ajuste dos parâmetros dos modelos para minimizar o erro entre as previsões e os valores reais
A classificação é um dos principais conceitos de Machine Learning, que envolve a categorização de dados com base nas suas características. Em outras palavras, é o processo de entender, reconhecer padrões e agrupar o conjunto de dados em categorias, com a ajuda de dados de treino pré-categorizados, de maneira que seja possível determinar quais rótulos serão aplicados em dados não observados.
Imagine que você está montando uma playlist de músicas para uma festa e precisa escolher três estilos musicais diferentes: rock, música eletrônica e hip-hop. Nesse caso, você precisa conhecer as características de cada um desses estilos para criar uma playlist que seus convidados gostem.
Como alguém que gosta de música, você já ouviu esses estilos antes e consegue identificar os padrões únicos de cada um deles. Essa habilidade de identificar os padrões é semelhante à classificação de dados em Machine Learning, como categorizar o gênero musical de uma canção com base em suas características. Abaixo temos uma representação gráfica desse exemplo:
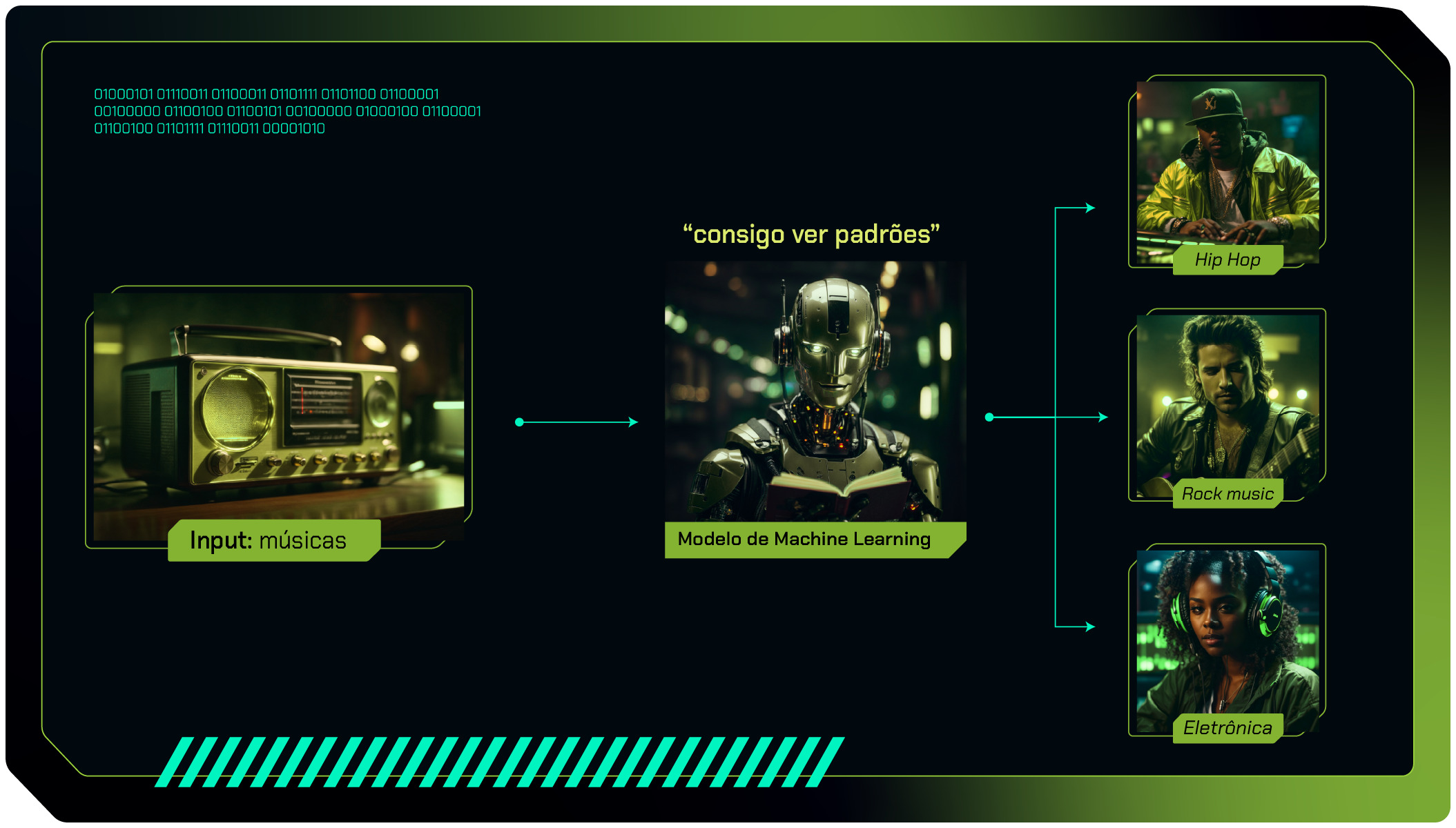
Na classificação, esse mesmo princípio acontece, pois precisamos saber antecipadamente quais são as respostas corretas para aprendermos os atributos que caracterizam cada categoria. Isso nos permite responder novas perguntas sobre o assunto.
Algoritmos de classificação
Os algoritmos de classificação são essenciais para categorizar dados, pois por meio deles podemos compreender e responder a questões específicas em diversos contextos e desafios. A seguir, apresentamos alguns exemplos:
- Naive Bayes: classifica dados com base em probabilidades condicionais.
- Redes Neurais Artificiais: reconhece padrões e processamento de linguagem natural inspirado no funcionamento do cérebro humano.
- Support Vector Machines (SVM): mapeia dados em um espaço multidimensional e encontra um hiperplano de separação.
- Regressão Logística: usada principalmente para problemas de classificação binária com intuito de estimar a probabilidade de pertencer a uma das duas classes possíveis.
- Árvore de Decisão: classifica novos dados seguindo um conjunto de regras.
- Random Forest: utiliza várias árvores de decisão em conjunto para melhorar a precisão da classificação e reduzir o overfitting.
- Gradient Boosting: constrói um modelo forte combinando vários modelos fracos de forma iterativa, minimizando os erros anteriores.
- K-Nearest Neighbors: faz previsões com base na maioria dos k pontos de dados mais próximos ao ponto de consulta.

Categorias da Classificação
Os algoritmos de classificação podem ser divididos em três categorias principais: classificação binária, classificação multiclasse e classificação multirrótulo. A seguir, vamos conferir cada uma delas.
Classificação binária
Na classificação binária, a ideia é classificar os dados em apenas duas categorias. Os dados são rotulados de forma binária, por exemplo: verdadeiro ou falso, 0 ou 1, spam ou não spam, etc. Exemplos de algoritmos de classificação binária são:
- Naive Bayes
- Redes Neurais Artificiais
- Regressão Logística
- Support Vector Machines
- Árvore de Decisão
Abaixo, temos um exemplo da classificação de animais, identificando em cachorro ou gato:
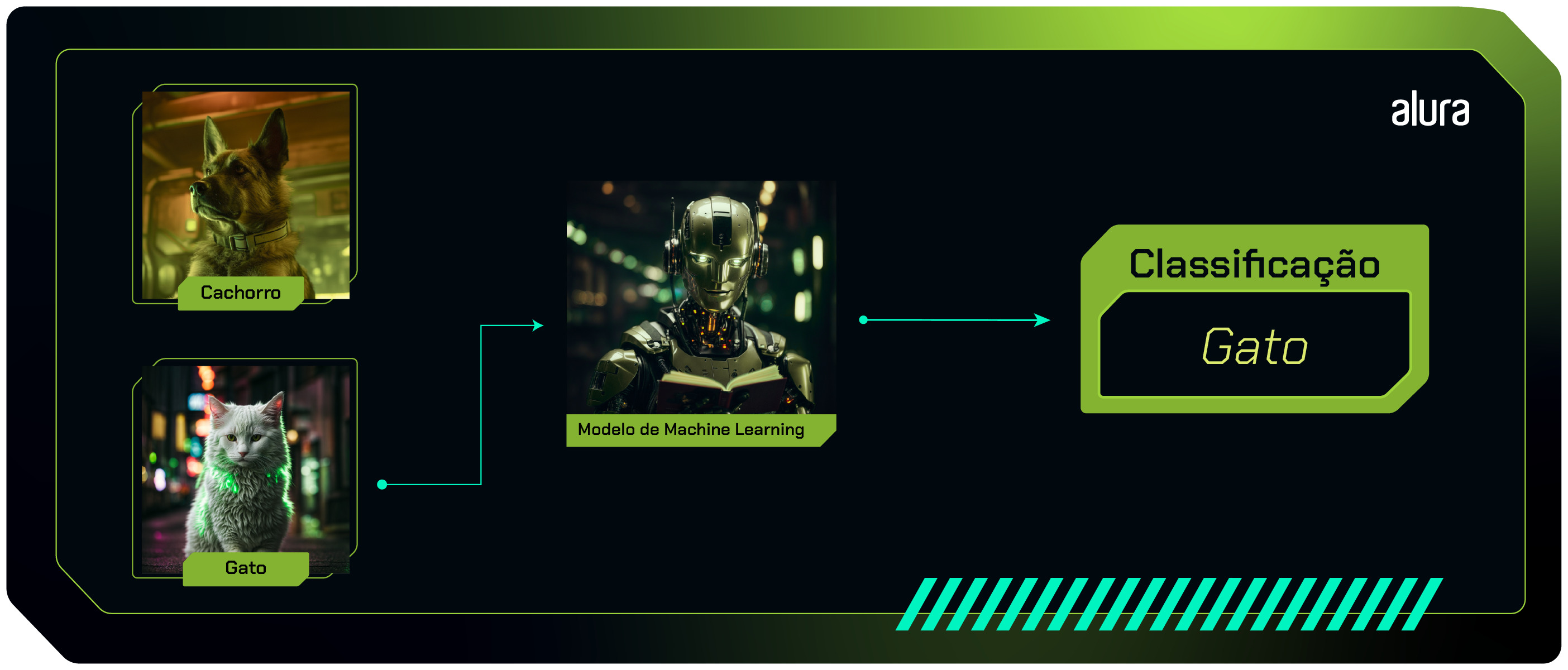
Classificação multiclasse
Na classificação multiclasse, os dados são classificados em pelo menos duas categorias. A ideia é descobrir a qual das duas ou mais categorias o dado pertence. A maioria dos algoritmos utilizados na classificação binária pode ser utilizada para a classificação multiclasse. Alguns algoritmos que fazem parte dessa classificação são:
- Naive Bayes
- Regressão Logística
- Support Vector Machines
- K-Nearest Neighbors
- Gradient Boosting
- Random Forest
Como exemplo, podemos adicionar mais uma categoria ao exemplo anterior, ficando com três categorias: cachorro, gato e pássaro.
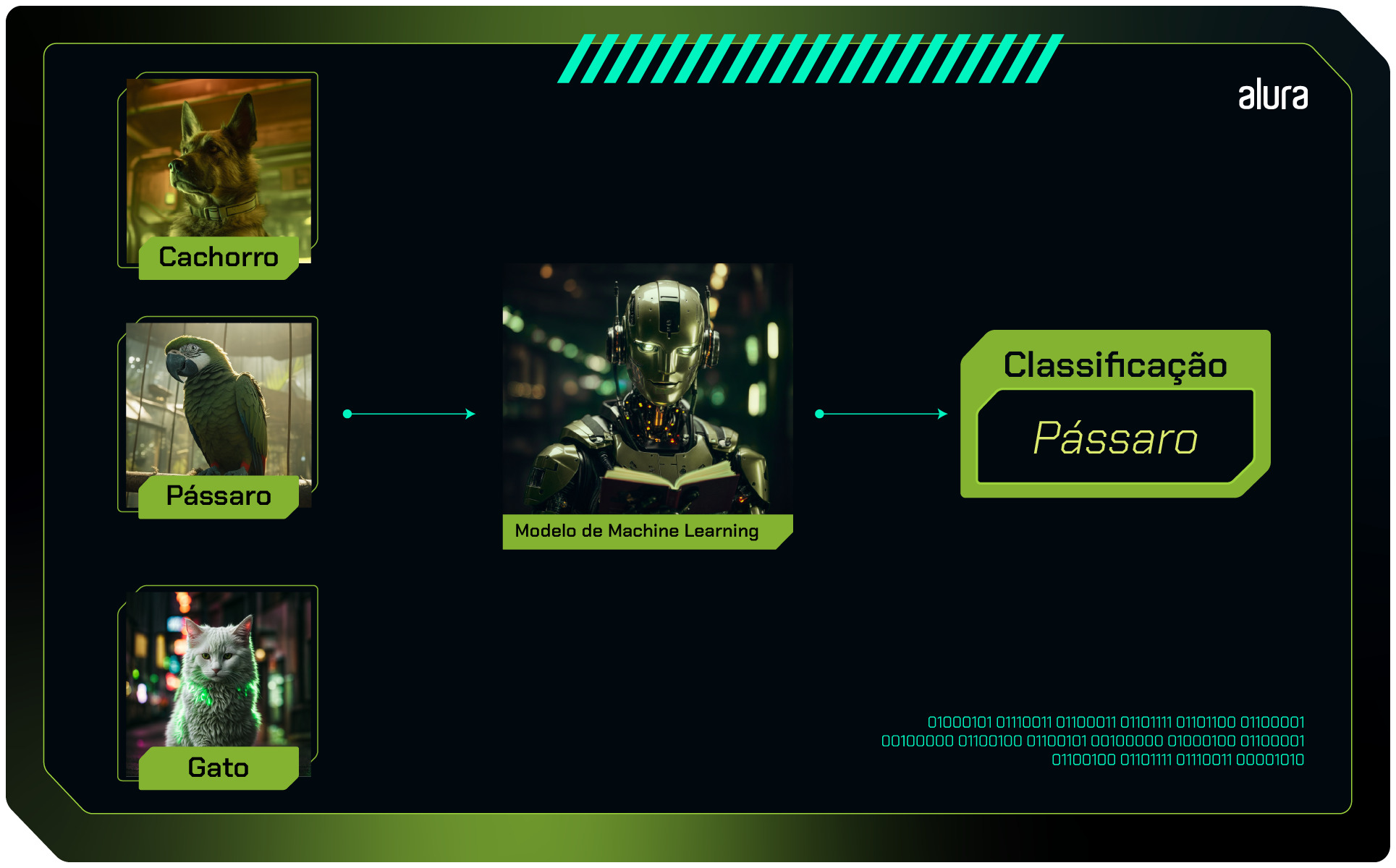
Classificação multirrótulo
Na classificação multirrótulo, os dados são classificados em 0 ou mais categorias. Nesse caso, um mesmo dado pode ser rotulado em várias categorias. Para esse tipo de classificação, diversos algoritmos padrão possuem sua versão adaptada. Alguns exemplos são:
- Árvore de Decisão multirrótulo
- Gradient Boosting multirrótulo
- Random Forest multirrótulo
Como exemplo, podemos ter uma imagem contendo diversos animais, onde o algoritmo irá encontrar cada animal presente na imagem:

Problemas resolvidos por Classificação
Através dos algoritmos de classificação, podemos resolver diversos tipos de problemas. A seguir, vamos verificar diversos problemas que são solucionados por algoritmos de classificação e compreender por que esses algoritmos são aplicados a esses determinados problemas.
Detecção de Spam
A detecção de spam é um problema comum em comunicações online, como e-mails, comentários em sites e redes sociais. Algoritmos de classificação são cruciais para filtrar mensagens indesejadas com base em certas características, como palavras-chave, padrões textuais, links suspeitos e outras informações relevantes.
Algoritmos utilizados e suas características:
- Naive Bayes: são rápidos de treinar e podem lidar bem com alta dimensionalidade de dados, como as representações de texto usadas na detecção de spam.
- Redes Neurais Artificiais: permitem capturar representações semânticas complexas de palavras e frases, tornando-os adequados para processamento de linguagem natural.
- Support Vector Machines (SVM): são eficazes para regras simples e heurísticas, tornando-os adequados para cenários onde existem padrões conhecidos de spam.
Previsão de Churn
A previsão de churn, ou taxa de cancelamento de clientes, é importante para empresas que buscam reter seus clientes. Algoritmos de classificação podem analisar dados de clientes e comportamentos de compra para classificar os clientes em categorias como "propenso a churn" ou "não propenso a churn", permitindo estratégias proativas de retenção.
Algoritmos utilizados e suas características:
- Regressão Logística e Árvores de Decisão: são interpretáveis e podem fornecer insights sobre quais características têm maior influência na previsão de churn.
- Random Forest: é altamente versátil, oferece uma combinação de várias árvores de decisão e lida bem com dados complexos, características mistas e potenciais interações entre variáveis.
Detecção de Fraude
A detecção de fraudes é um problema crucial em muitos setores, especialmente em finanças e comércio eletrônico. Algoritmos de classificação podem analisar padrões de comportamento e transações para identificar atividades suspeitas, minimizando perdas e mantendo a segurança. Eles podem classificar transações como "fraude" ou "não fraude" com base em características como localização, valor, tipo de transação e comportamento do cliente.
Algoritmos utilizados e suas características:
- Regressão Logística: pode ser útil em casos em que as relações entre as variáveis são mais simples e a interpretabilidade é importante.
- Árvores de Decisão: é excelente para lidar com dados desbalanceados e pode capturar relações não lineares entre características. Isso é importante para identificar padrões sutis de fraude.
Análise de Crédito
A análise de crédito é fundamental para instituições financeiras ao avaliar a probabilidade de um cliente pagar ou não suas dívidas. Algoritmos de classificação avaliam o risco de crédito de indivíduos com base em histórico de pagamento, renda e informações financeiras para classificar os candidatos em categorias como "baixo risco", "médio risco" e "alto risco". Isso ajuda as instituições a tomar decisões informadas sobre concessão de crédito e limites.
Algoritmos utilizados e suas características:
- Regressão Logística: é uma escolha comum para problemas de classificação binária, como decidir se um candidato tem baixo ou alto risco de crédito.
- Árvores de Decisão: permite lidar com atributos mistos (numéricos e categóricos) frequentemente presentes em dados de análise de crédito.
Outros problemas
Além dos problemas destacados acima, os algoritmos de machine learning também são aplicados com sucesso em várias outras áreas:
- Classificação de documentos ou textos: são usados para categorizar documentos e textos automaticamente, tornando mais eficiente a organização e busca de informações.
- Análise de sentimento: é a capacidade de determinar sentimentos em textos, como positivo, negativo ou neutro, o que é útil para análises de opiniões e feedbacks.
- Classificação de imagens: são usados para identificar objetos e padrões em imagens, sendo úteis em áreas como medicina, indústria e automação.
Conclusão
Os algoritmos de classificação são fundamentais no campo de Machine Learning, permitindo a categorização precisa de dados com base em seus diferentes aspectos. A classificação é uma técnica versátil que pode ser utilizada para solucionar problemas em diversas áreas, como negócios e marketing, saúde, mídia e entretenimento, finanças, processamento de linguagem natural, entre outras. Para alcançar resultados eficazes, é essencial escolher os algoritmos adequados para cada tipo de problema, levando em consideração suas características específicas.
E aí, curtiu a leitura? Aqui na Alura temos muitos outros conteúdos para te ajudar a estruturar seus conhecimentos em Machine Learning. Bora mergulhar em tecnologia? Venha estudar conosco! 🤿
Créditos
- Conteúdo: Marcelo Cruz
- Produção técnica: Rodrigo Dias
- Produção didática: Cláudia Machado
- Designer gráfico: Alysson Manso
- Apoio: Rômulo Henrique
