Iniciando um projeto Spark no Google Colab


Quando perguntamos para uma pessoa, que já deu seus primeiros passos no universo de Data Science e Machine Learning, quais as bibliotecas que ela utilizaria para carregar e processar os dados, provavelmente ela diria SKlearn e Pandas. Ambas resolvem muito bem todas as tarefas que precisamos quando estamos lidando com uma quantidade de dados pequena.
E quando passamos para um cenário de dados mais volumosos (na casa dos milhões, bilhões ou até mais)? Será que o Pandas vai conseguir processar tudo isso? Uma vez que o Pandas faz uso de memória RAM da máquina para processar os dados, a resposta geralmente é: não vai conseguir. Então, o que uma pessoa cientista de dados pode fazer neste momento?
Hadoop e Spark
Pensando em resolver este problema, surgiram soluções como o Hadoop e o Spark. O que eles fazem é tornar possível o processamento de grandes quantidades de dados através do processamento distribuído. O Hadoop, o mais antigo dos dois, foi criado em 2008 e é composto por três camadas principais: a de processamento (MapReduce), a de armazenamento (Hadoop Distributed File System - HDFS) e a de gerenciamento de recursos (YARN). Isso permite o processamento de Big Data.
Muito legal! Mas, se o Hadoop já resolve todo o problema de processamento de dados, qual a motivação para utilizar o Spark? Isto está relacionado com o funcionamento do Hadoop. A cada operação que executa, ele precisa ler os dados e depois gravá-los de volta no armazenamento físico após o processamento. A leitura e gravação frequentes no disco geram um gargalo enorme em toda a operação que, mesmo rodando em paralelo, vai ficar limitada.
Spark resolve isso melhorando o modelo de programação MapReduce e reaproveitando todas as outras soluções (YARN e HDFS). Outra diferença importante em relação ao Hadoop é que o Spark trabalha com os dados em memória e não com leituras e gravações constantes em disco. Com isso, ele apresenta uma performance bastante superior ao Hadoop, podendo chegar a um desempenho até 100 vezes maior.
Convencidos(as) de que o Spark é a melhor opção para trabalhar com seus dados? Então vamos aprender como utilizar o Spark no seu projeto no Colab.

Instalando o Spark no Google Colab
Iremos aprender duas maneiras de instalar o Spark no Colab. A primeira é instalando o pacote PySpark através de um gerenciador de pacotes e a segunda é fazendo o download dos arquivos necessários para Spark, Hadoop e Java.
Segundo a documentação no site PyPI, que é o gerenciador de pacotes Python, temos que:
O pacote Python para Spark não se destina a substituir todos os outros casos de uso. Esta versão do pacote é adequada para interagir com um cluster existente (seja Spark standalone, YARN ou Mesos), mas não contém as ferramentas necessárias para configurar seu próprio cluster Spark standalone. Você pode baixar a versão completa do Spark na página de downloads do Apache Spark.
De maneira geral, ao utilizar somente o PySpark não é possível configurar o cluster no Spark Standalone. Então, qual devemos instalar? Inicialmente, é melhor instalar a versão do pacote PySpark, porque é mais fácil e vai atender quem está começando no mundo do Spark.
No entanto, é importante aprender o segundo método, pois ele será necessário em projetos com um grande volume de dados e com a necessidade de gerenciamento de recursos de processamento e memória, no qual será preciso acompanhar e gerenciar todos os processos executados pelo Spark.
Instalando o pacote PySpark
Para instalar o PySpark no Colab, basta digitar o comando !pip install, o nome do pacote pyspark e a versão, adicionando o sufixo ==3.3.1 ao nome do pacote.
Fique sempre atento(a) à versão recomendada para o projeto que está trabalhando.
!pip install pyspark==3.3.1E é isso! Apenas com esse comando você consegue começar a trabalhar com o PySpark.
Instalando a ferramenta Spark
Agora, vamos seguir para o segundo método de instalação do Spark que envolve mais etapas e pré-requisitos, mas também permite um maior gerenciamento dos recursos para o Spark.
Primeiro, vamos precisar instalar um kit de desenvolvimento java (JDK) que vai permitir rodar código na linguagem Scala e nas máquinas virtuais Java (JVM), que é como o Spark foi construído. Para isso, utilizaremos o comando:
!apt-get install openjdk-8-jdk-headless -qq > /dev/nullDepois vamos baixar, através da ferramenta wget, os arquivos do Spark na máquina virtual do Google. Nesse caso, optamos pela versão 3.3.1 do Spark e a versão 3 do Hadoop. (Para buscar por outras versões podemos consultar a pagina oficial do Spark).
!wget -q https://dlcdn.apache.org/spark/spark-3.3.1/spark-3.3.1-bin-hadoop3.tgzO próximo passo vai ser descompactar o arquivo que fizemos download.
!tar xf spark-3.3.1-bin-hadoop3.tgzPor fim podemos instalar o pacote findspark que será responsável por tornar o PySpark uma biblioteca possível de ser importada regularmente.
!pip install -q findsparkAgora podemos passar para o Python e definir as variáveis de ambiente para cada utilitário. Basicamente, explicaremos para o computador onde estão os programas que vamos utilizar. No nosso caso, esses programas são o Java e o Spark.
import os
os.environ["JAVA_HOME"] = "/usr/lib/jvm/java-8-openjdk-amd64"
os.environ["SPARK_HOME"] = "/content/spark-3.3.1-bin-hadoop3"Com as variáveis de ambiente definidas, podemos utilizar o findspark que vai permitir a importação dos pacotes necessários para utilizar o PySpark.
import findspark
findspark.init()Pronto! Conseguimos instalar o Spark e utilizar o PySpark.
Testando o PySpark
Independente do método, conseguimos testar a instalação da mesma maneira. Podemos, por exemplo, importar o SparkSession do módulo pyspark.sql.
from pyspark.sql import SparkSessionE, finalmente, criarmos a nossa seção Spark que nada mais é que a API que vamos utilizar para trabalhar com o Spark. Ela vai cuidar de toda a parte de gerenciamento dos nós do processamento em paralelo.
spark = SparkSession.builder \
.master('local[*]') \
.appName('Iniciando com Spark') \
.config('spark.ui.port', '4050') \
.getOrCreate()Executando apenas a variável spark em uma célula veremos algumas informações sobre a sessão Spark criada.
sparkTeremos como retorno, o nome da nossa sessão Iniciando com Spark, a versão utilizada v3.1.1 e a configuração local com todos os cores disponíveis *local[]**.
SparkSession - in-memory
SparkContext
Spark UI
Version
v3.1.1
Master
local[*]
AppName
Iniciando com SparkFeito isso, você terá acesso a todas as operações do Spark prontas para serem utilizadas.
Quais as vantagens do Spark?
É importante destacar que cada uma das ferramentas tem suas vantagens e desvantagens e é necessário refletir quando utilizar cada uma delas. O Pandas funciona muito bem para bases pequenas. Já o Hadoop pode ser a melhor escolha com bases grandes em que a perda de performance não seja muito grande.
Para o Spark pode ser uma escolha sua para quando estiver trabalhando com muitos dados que precisem de alta performance ou até com dados em streaming. Abaixo temos um gráfico de um estudo Benchmarking Apache Spark on a Single Node Machine comparando as performances do Pandas e do PySpark.
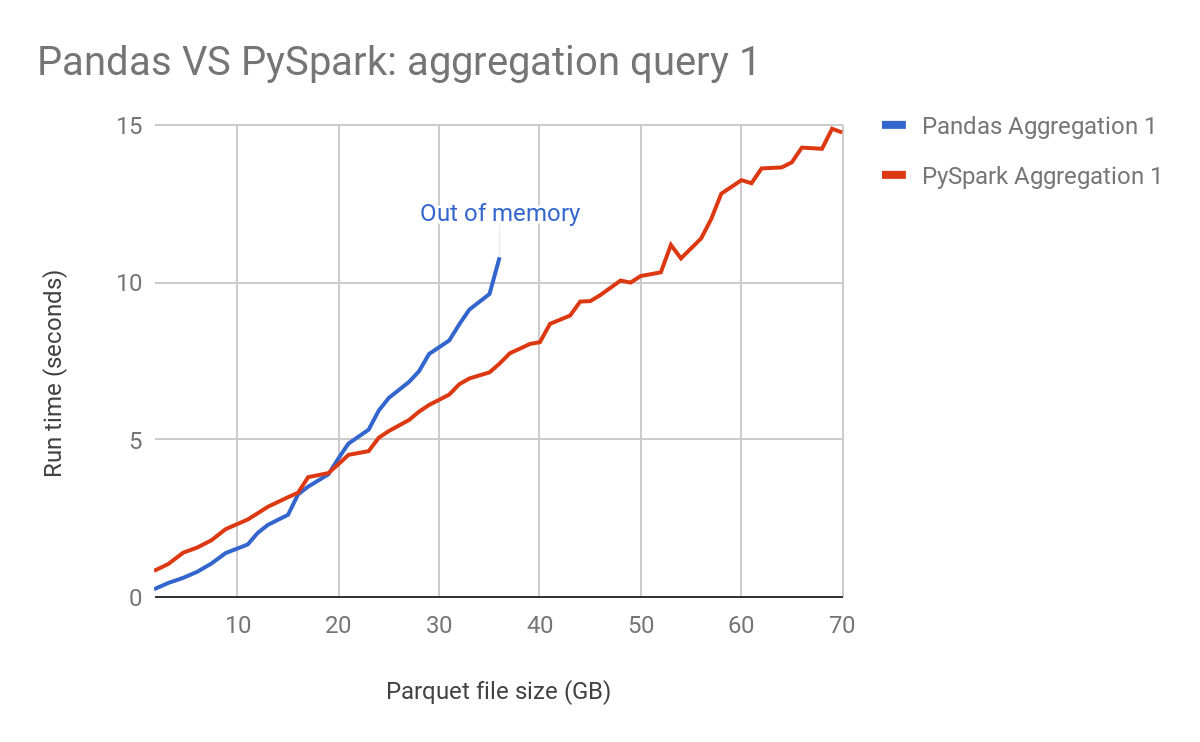
No gráfico podemos observar que o Pandas apresenta melhor performance para poucos dados e que o Pyspark é superior quando temos muitos dados.
Conclusão
Neste artigo, aprendemos como instalar os pré-requisitos para rodar o Spark no ambiente do Google Collaboratory. Aqui na Alura temos diversos conteúdos que vão apresentar várias possibilidades com o Spark, desde trabalhar com Streaming até Machine Learning.
Se quiser conhecer mais sobre a história do Spark e do Big Data, temos o Alura+ Big Data com Apache Spark. Para aprofundar ainda mais na prática do Spark, temos a formação Apache Spark com Python.
Créditos:
- Autor: Igor Nascimento Alves
- Co-autores: Bruno Raphaell e Marcus Almeida
- Produção técnica: Rodrigo Dias
- Produção didática: Morgana Gomes