Hugging face: o que é e como usar essa plataforma


Se você está chegando na área de Machine Learning ou Inteligência Artificial, há grandes chances de já ter ouvido falar de “Hugging Face” em algum lugar.
Esse é o nome de uma plataforma que tem desempenhado um papel fundamental na democratização das tecnologias de IA e que tem se popularizado cada vez mais conforme a área cresce, tanto em conhecimento quanto em número de pessoas interessadas.
Nesse artigo, vamos nos familiarizar com o Hugging Face e descobrir como aproveitar o que a plataforma tem a oferecer.
Vamos começar?
O que é Hugging Face
Hugging Face é uma plataforma colaborativa que democratiza o acesso ao aprendizado de máquina e IA, criada em 2016.
A plataforma funciona mais ou menos como o Github onde é possível compartilhar seus próprios projetos, bem como pesquisar, se inspirar ou clonar projetos de outras pessoas.
No momento em que esse artigo está sendo escrito, o Hugging Face possui mais de 850 mil modelos disponíveis, capazes de lidar com processamento de texto, áudio e imagem.
Modelos de linguagem de grande porte (LLMs) como o GPT ou Gemini, por exemplo, exigem pagamento pela API para serem utilizados em código e não fornecem informações significativas sobre a arquitetura do treinamento do modelo ou sobre os dados utilizados.
Isso pode criar dificuldades para a utilização desses modelos e limitar a capacidade de outros desenvolvedores de ML de se inspirarem na tecnologia.
Por outro lado, a grande maioria dos modelos presentes no Hugging Face podem ser replicados de forma gratuita e são de código aberto.
Inclusive, as mesmas empresas dos modelos proprietários citados acima colaboram e disponibilizam modelos open source no Hugging Face, além de terem investido na plataforma. O estado atual da IA é construído, primordialmente, de forma colaborativa - e o Hugging Face é protagonista nessa história.
Uma comunidade super engajada permite que tudo isso seja possível!
Além do conhecimento compartilhado, outra vantagem significativa é a reutilização de treinamentos já executados. Treinar LLMs demanda muito tempo (de semanas a meses) e uma quantidade enorme de energia e recursos naturais.
A emissão de gases de efeito estufa decorrente de treinamento de IAs deve ser considerada, e a reutilização de modelos já treinados mitiga o impacto dessa tecnologia no meio ambiente.
Dica de leitura: Como criar uma Inteligência Artificial? O que é preciso, quais os exemplos e como uma IA pode te ajudar.

Navegando no hub
Hub é o nome que se dá ao ambiente onde os diferentes produtos hospedados no Hugging Face estão reunidos.
Ao entrar na plataforma, nos deparamos com vários caminhos possíveis a seguir. Pode parecer bastante informação em um primeiro contato, e é mesmo! Mas, vamos explorar cada uma das abas e compreender melhor o que compõe o Hugging Face.
Antes de tudo, é possível criar uma conta para acessar o hub - a conta não é obrigatória para ver os modelos e outros produtos presentes na plataforma, mas ela tem uma grande importância: é através da conta que podemos interagir programaticamente com o hub.
Os modelos são livres para uso, mas, em diversos deles, é preciso concordar com termos de uso ou compartilhar seu e-mail e nome de usuário, por exemplo, para ter o acesso permitido. Ao importar o modelo em um ambiente de desenvolvimento, é necessário se identificar, e é aí que entram os tokens de acesso.
O contrário também é válido: com o token de acesso você pode performar ações git nos seus repositórios que estão hospedados no Hugging Face diretamente do ambiente de desenvolvimento.
A conta é gratuita, mas o HF também oferece uma opção de conta paga com recursos adicionais, além de uma versão de conta enterprise (corporativa), com ainda mais recursos e suporte prioritário.
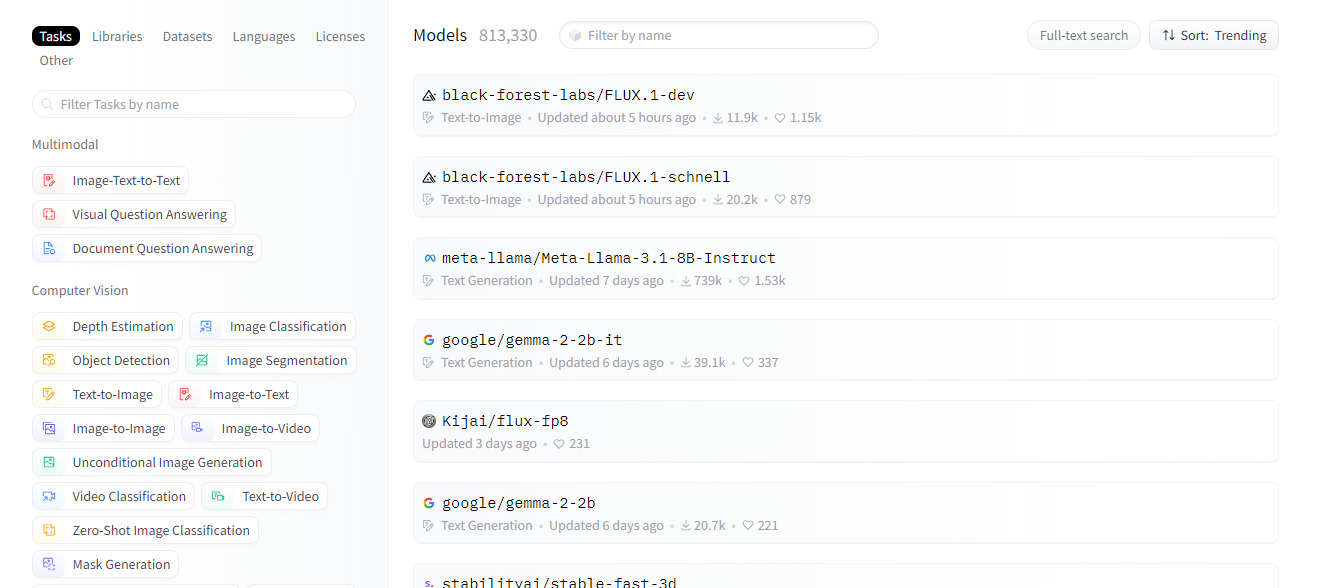
Models
Nessa aba podemos explorar os modelos públicos. Na lateral esquerda, há diversas opções de filtros que podem ser aplicados na busca pelo modelo ideal, de acordo com a necessidade específica.
É possível filtrar por tarefa desempenhada, língua, bibliotecas e dataset utilizados, entre outros critérios.
Entre as tarefas desempenhadas temos Processamento de Linguagem Natural, reconhecimento de voz, visão computacional, entre outros.
Mas… e como é o modelo?
Vamos dar uma espiada no Gemma 2, um modelo lançado pelo Google e criado com a mesma base tecnológica do Gemini.
Na página do modelo, temos acesso a:
- Descrição do modelo, explicando o objetivo do modelo, informações sobre a pesquisa, documentação, entre outros.
- Arquivos e versões no repositório Github.
- Comentários da comunidade com dúvidas ou reportando problemas, por exemplo.
- API de inferência: uma interface para interagir com o modelo.
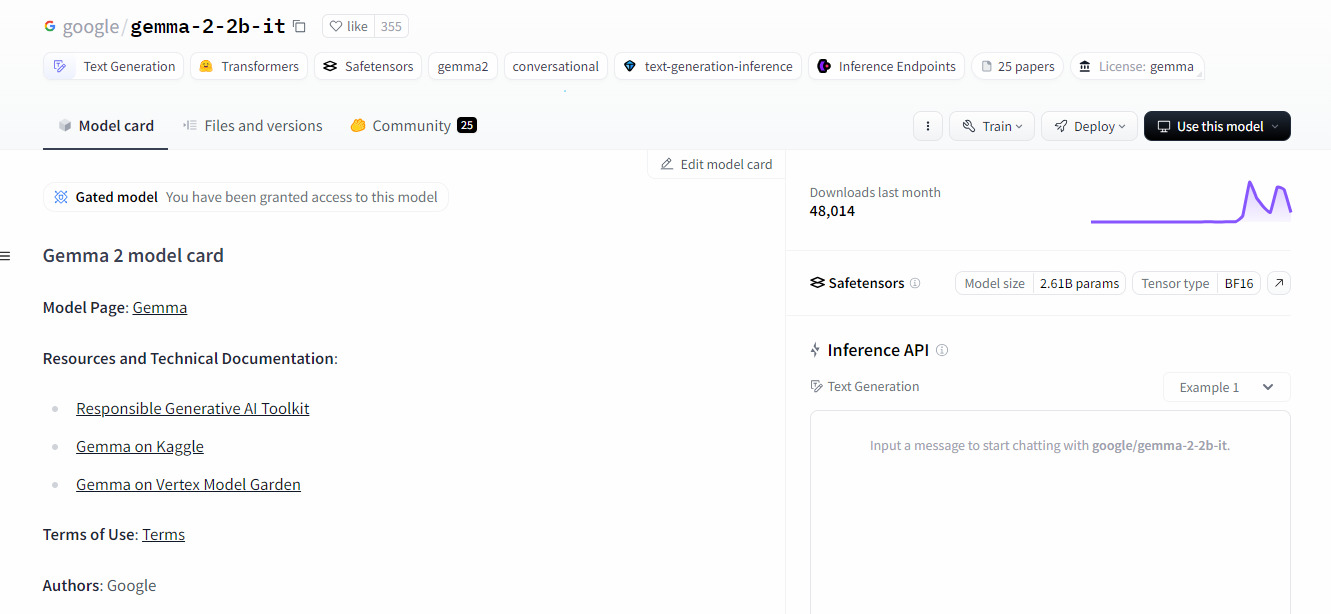
Além disso, é pela página do modelo que é possível fazer o download. No botão “Use this model”, estão disponíveis as linhas de código de acordo com a biblioteca integrada no projeto.
Dica: o nome dos modelos costuma ter valores como
124M,2B,70B. Esses valores são referentes à quantidade de parâmetros com que o modelo foi treinado.
A letra M é para milhões, e B para bilhões. Modelos com menos parâmetros são mais leves e mais rápidos, enquanto modelos com mais parâmetros performam melhor em tarefas mais complexas.
Datasets
São os conjuntos de dados já ideais para a utilização em projetos de ML. Assim como na aba de modelos, há diversas opções de filtros que podem ser aplicados.
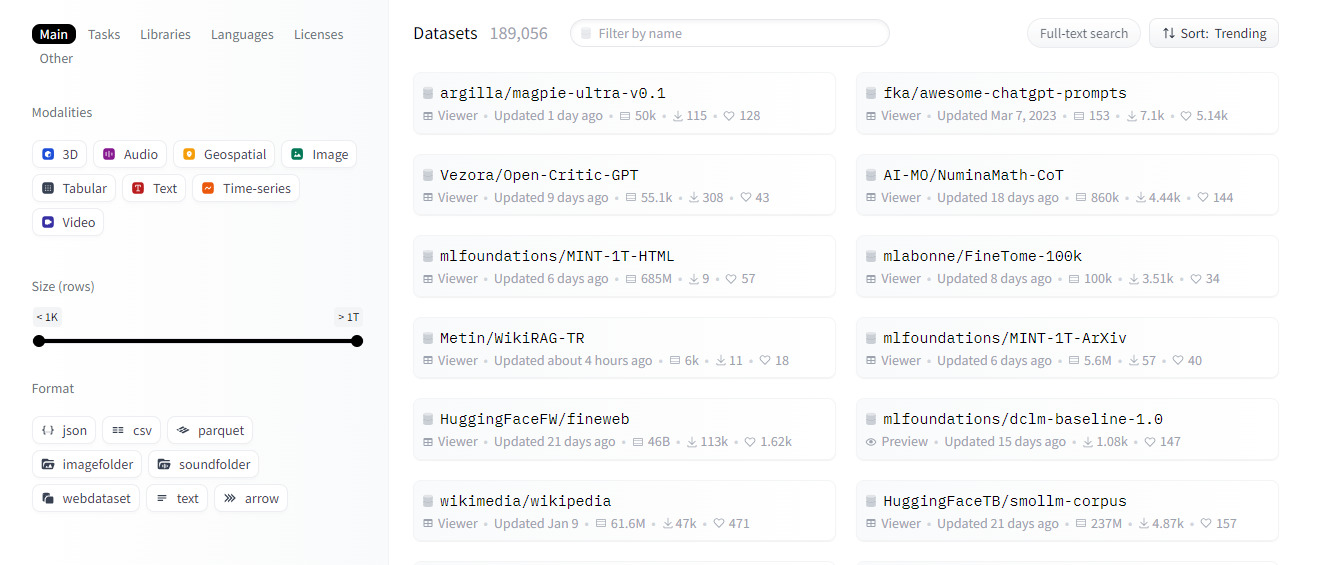
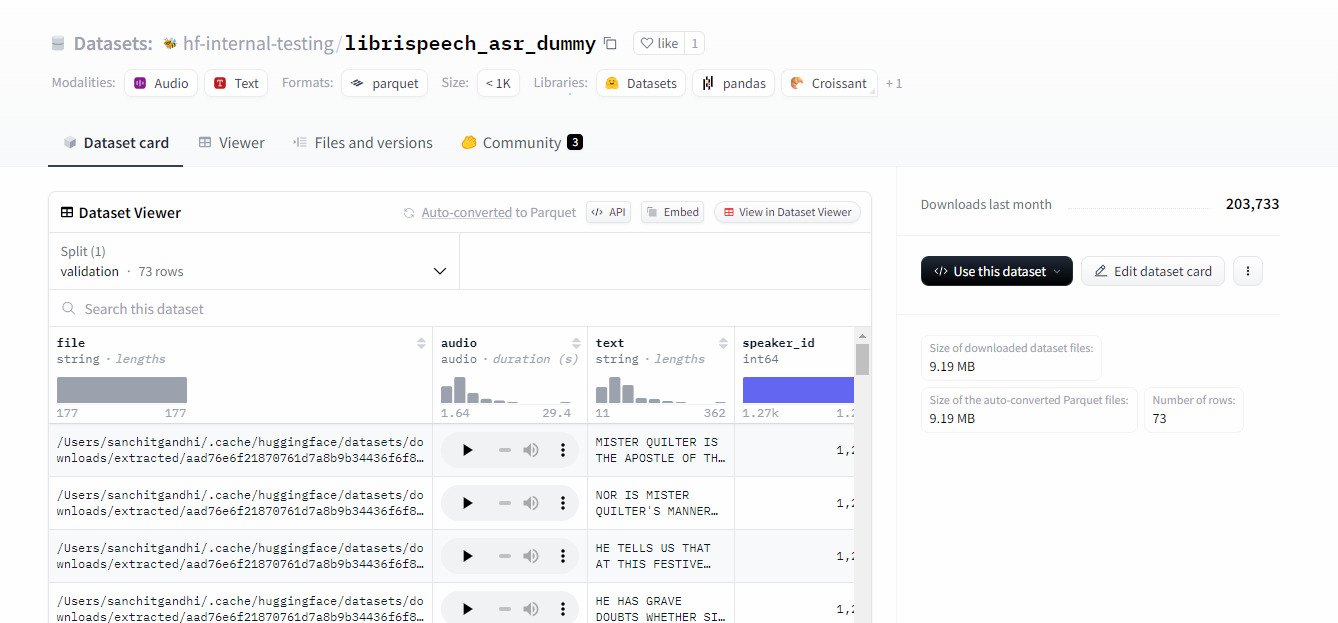
Esses conjuntos de dados podem ser utilizados, inclusive, para aplicar o fine-tuning no modelo escolhido - isso é, treiná-lo de forma personalizada para que os resultados obtidos posteriormente fiquem mais próximos do que é o desejado.
Ao clicar em um dataset, podemos pré-visualizar a base de dados, seu repositório git, comentários da comunidade, bem como obter o código para importar o dataset para um projeto.
Spaces
Essa parte é a mais divertida! Aqui estão hospedados trabalhos de ML feitos por membros da comunidade utilizando os modelos.
Esses trabalhos são chamados de apps quando estão hospedados, e muitos apps conterão informações interessantes sobre o modelo utilizado, link para os arquivos no Github e, algumas vezes, até referências acadêmicas da pesquisa.
Executar apps é uma forma interessante de ver os modelos em ação!
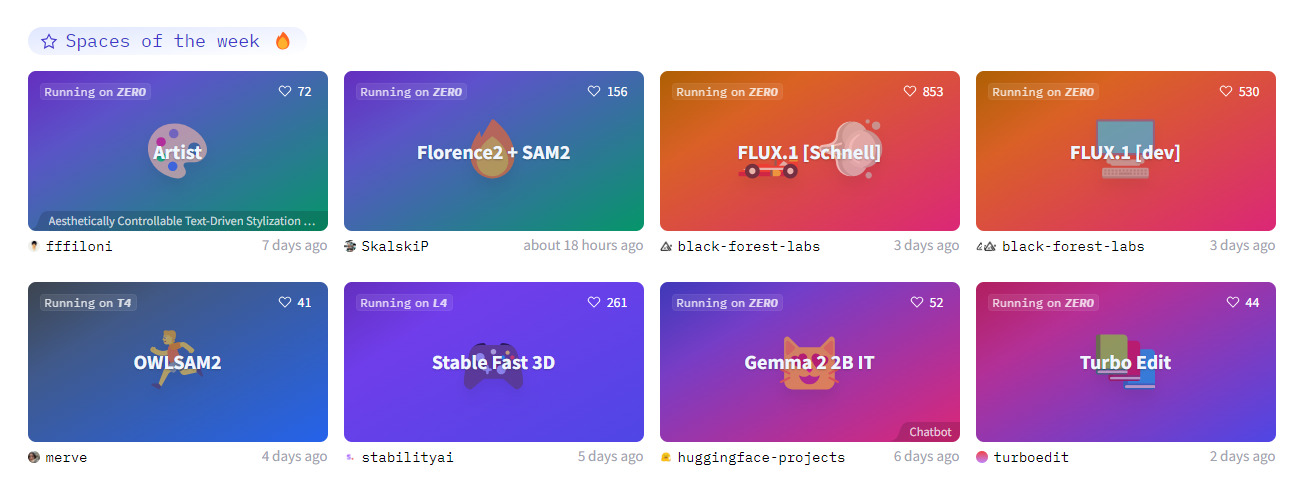
Criar um app no Hugging Face é simples: é possível escolher o SDK (kit de desenvolvimento de software) de Gradio ou Streamlit, ou ainda criar um espaço estático com HTML e CSS.
Então, basta adicionar o código. O app pode ser compartilhado por meio da URL e até ser fixado em uma página web! É uma ótima estratégia para enriquecer o portfólio.
Os espaços são gratuitos até 16GB de memória, 2 CPUs e 50GB de espaço em disco. Após esse limite, é possível fazer upgrades para diversas outras opções com mais recursos disponíveis.
Posts
Essa área é a parte social do Hugging Face, onde as pessoas usuárias postam suas explorações, reflexões, dúvidas e descobertas sobre a área de ML e IA.
É possível interagir com os posts e seguir as pessoas, assim como em uma rede social.
Docs
Nessa aba, está o acesso a uma extensa e detalhada documentação sobre cada um dos componentes do Hugging Face.
A documentação é a melhor amiga de uma pessoa desenvolvedora, e o Hugging Face valoriza isso. É uma documentação clara e de alto nível, que auxilia o uso da plataforma mesmo para pessoas que não tem ampla experiência na área.
O hub conta com uma interface bastante amigável para navegação. Mas pode surgir o desejo de interagir com o hub sem sair do ambiente de desenvolvimento, e isso é possível através da biblioteca Python huggingface-hub ou, para devJavascript, a huggingface.js.
O que é o Transformers do Hugging Face
Transformers é uma biblioteca desenvolvida pelo Hugging Face que permite a utilização de vários dos modelos pré-treinados disponíveis no hub.
A biblioteca é uma aplicação prática do modelo Transformers, uma arquitetura de aprendizado de máquina focada em paralelização e mecanismos de atenção que capturam relacionamentos complexos em textos. Porém, temos também modelos não-transformers na biblioteca.
Com Transformers, temos integração com Pytorch e Tensorflow, frameworks amplamente utilizados no treinamento de modelos de aprendizado profundo.
Uma das funções mais úteis da Transformers é a pipeline, um objeto que encapsula todas as outras pipelines presentes no modelo. São algumas delas:
- Classificação de texto
- Reconhecimento de fala
- Geração de texto
- Segmentação de imagens
- Imagem para texto
- Texto para imagem
Para conferir todos os pipelines disponíveis, confira na documentação.
Com pouquíssimas linhas de código, é possível executar tarefas como as citadas acima e escolher entre os diversos modelos disponíveis no hub.
Nesse contexto, pipeline pode ser traduzido como fluxo de trabalho. São etapas encadeadas que resultam na realização de uma tarefa. As etapas são:
- Pré-processamento: o input é convertido em tokens, que são pedacinhos de palavras que mantêm seu significado original.
- Uso do modelo: o modelo entra em ação. Os tokens são convertidos em embeddings, uma representação matemática dos tokens, que permite que a tarefa seja executada de acordo com a arquitetura e treinamento do modelo.
- Pós-processamento: acontece a decodificação e a saída do modelo é transformada em uma resposta compreensível.
Vamos experimentar?
Aplicando um modelo
Vamos testar a importação de um modelo do Hugging Face com a biblioteca Transformers, utilizando Python!
Recomendo testar os modelos em notebooks do Google Colab, afinal, muitos dos modelos exigem bastante poder de computação e podem ser custosos dependendo das configurações e recursos de hardware que você tem disponíveis.
Ainda assim, a memória disponibilizada pelo Colab também pode não ser suficiente para modelos muito grandes.
Caso prefira rodar o código localmente, é super importante criar um ambiente virtual. Você pode seguir os passos do artigo Ambientes virtuais em Python.
Com o ambiente criado e ativado, instale o Transformers:
pip install transformersÉ recomendado, também, fazer a instalação do back-end que será utilizado no projeto, seja o PyTorch, o Tensorflow ou ambos. Porém, o Transformers não exige que esses pacotes estejam instalados durante a execução de alguns modelos no pipeline - nesse caso, o framework utilizado na base do modelo escolhido será instalado automaticamente no momento da execução.
Mão na massa!
Inicie um novo notebook no Colab. Para utilizar essa ferramenta, basta estar logado em uma conta Google.
Então, na primeira célula, insira o seguinte código. Execute.
from transformers import pipelineO objeto pipeline, como vimos, oferece diversas opções de fluxo de trabalho. Basta importá-lo para começarmos a experimentar o poder dos Transformers.
Análise de sentimento
Uma das tarefas performadas é a análise de sentimentos. Observe o código:
classificador = pipeline("sentiment-analysis")
classificador(['O Hugging Face é incrível!', 'Tenho muito a aprender, preciso me organizar'])Criamos um objeto “classificador” contendo o fluxo de trabalho sentiment-analysis. Então, passamos uma lista de frases para esse objeto classificador.
O retorno é uma lista de dicionários. Cada dicionário é referente à frase correspondente enviada no classificador, e contém o label para o sentimento (positivo ou negativo) e um score, que é o nível de confiança da label. Quanto mais próximo de 1, mais chance de a classificação ser verdadeira.
[{'label': 'POSITIVE', 'score': 0.9751573801040649},
{'label': 'NEGATIVE', 'score': 0.9701449871063232}]Gerador de texto
Com o pipeline text-generation podemos gerar textos!
Se copiarmos a mesma estrutura utilizada no exemplo anterior, temos algo assim:
gerador_de_texto = pipeline('text-generation')
gerador_de_texto('Tenho pimentões e berinjelas na geladeira. Vou')Ao executar essa célula, esperava que o resultado fosse o nome de alguma receita mediterrânea ou turca, mas o retorno foi o seguinte:
[{'generated_text': 'Tenho pimentões e berinjelas na geladeira. Vou darás na hacia tambiarjema!\n\nHacerla toluas ajús haberinjedos'}]Opa! Parece que o modelo default da geração de texto não tem suporte para o português.
E se o input for em inglês?
gerador_de_texto = pipeline('text-generation')
gerador_de_texto('I might bake a chocolate')Temos um retorno que é coerente. O texto gerado é um diálogo que permanece na mesma língua e cria um contexto razoável.
[{'generated_text': 'I might bake a chocolate cake!"\n\nHanna: "My goodness, honey. That\'ll be delicious! I want to make something special for my family..."\n\nBetsy: "Well what do you think?"\n\nHanna:'}]Felizmente, como vimos anteriormente, é possível filtrar os modelos no hub por língua. Encontrei o Aira-2-portuguese-124M, um modelo criado por um brasileiro, o Nicholas Kluge Corrêa. Vamos testar!
gerador_de_texto = pipeline('text-generation', model="nicholasKluge/Aira-2-portuguese-124M")
gerador_de_texto('Tenho pimentões e berinjelas na geladeira. Vou')A resposta foi:
[{'generated_text': 'Tenho pimentões e berinjelas na geladeira. Vou me ajudar a encontrar um bom restaurante perto de mim.Claro! Ficarei feliz em ajudá-lo a encontrar um bom restaurante perto de você. Para melhor atendê-los, precisarei saber sua localização atual ou o nome da cidade onde você está localizado. Você poderia me fornecer essa informação?'}]Legal! Pela forma como passamos o input, o modelo funcionou como um autocomplete, e parece ter sido treinado como um assistente pessoal.
É importante ter em mente que cada modelo terá suas particularidades e pode ter sido desenvolvido para objetivos específicos.
É interessante investigar a página dos modelos para descobrir qual se encaixa com seus objetivos e conhecer seus próprios métodos.
Criando um token
Quando o modelo escolhido é trancado, é preciso gerar um token de acesso e fazer a autenticação no ambiente de desenvolvimento.
Com login feito, na página do Hugging Face, clique no ícone do perfil no canto superior direito da tela e clique em settings.
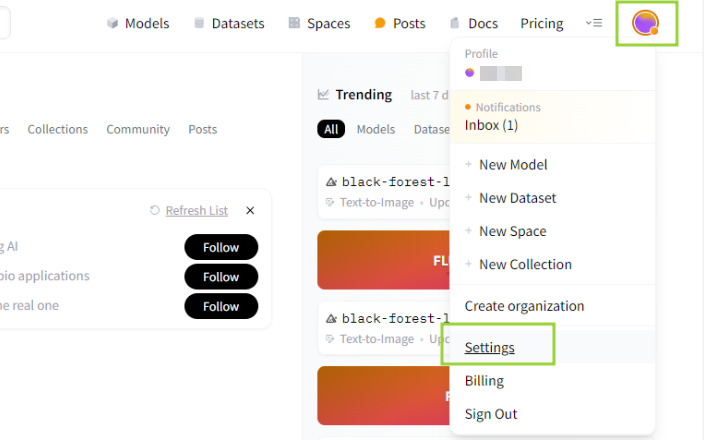
Então, na página de perfil, clique em Access Tokens no menu esquerdo. O tipo read é o ideal para o nível mais básico de uso, quando não serão feitas alterações no modelo em si.
Dê um nome ao token e crie. Copie o código e guarde em um lugar seguro - esse é o único momento em que esse código poderá ser copiado.
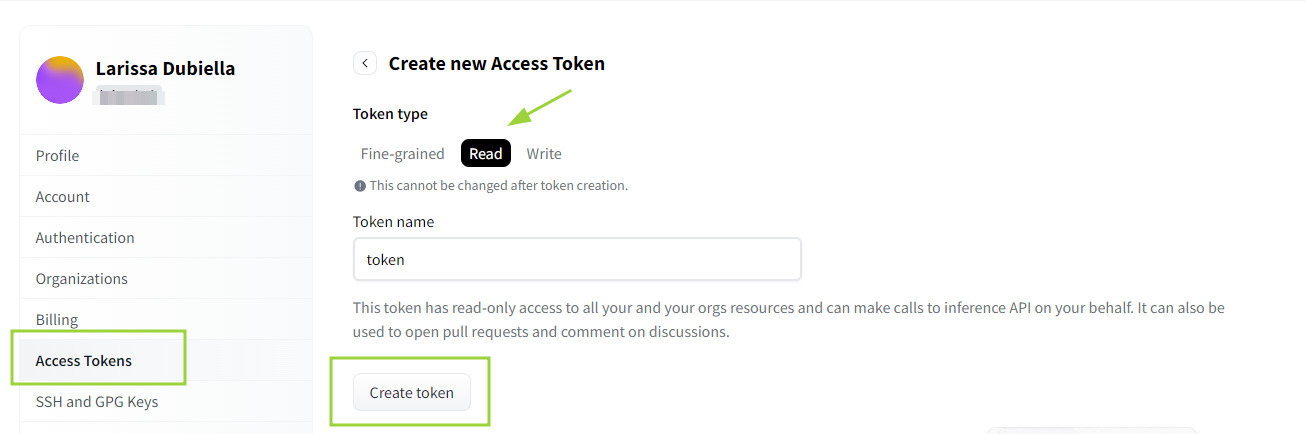
Então, no seu ambiente de desenvolvimento, execute:
from huggingface_hub import login
login()Preencha o campo com seu token. Pronto, o ambiente estará autenticado e os modelos que forem liberados para sua conta estarão disponíveis para uso.
Como aprender mais sobre Hugging Face
A própria plataforma oferece cursos gratuitos de alta qualidade, vale a pena conferir!
Os cursos focam em diferentes tópicos da área de ML e IA e, apesar de serem bastante interessantes, podem ser desafiadores para quem está começando na área. Além disso, os vídeos são todos em inglês.
Aqui na Alura, temos uma formação inteirinha dedicada ao Hugging Face, além de formações que ensinam os conceitos de Machine Learning e a trabalhar com os frameworks citados ao longo do artigo.
- Hugging Face
- Machine Learning
- Machine Learning avançado
- Deep Learning com Tensorflow Keras
- Deep Learning com Pytorch
É altamente recomendado ter um conhecimento prévio de programação para trabalhar com o Hugging Face e com a biblioteca Transformers.
Se você está começando agora, dê seus primeiros passos com a formação Python para Data Science.
Nesse artigo, conhecemos o que é o Hugging Face e experimentamos um pouco da biblioteca Transformers. Ficou com gostinho de quero mais? Vem estudar com a gente!
Forte abraço e até breve.