Formações Data Science AWS Data Lake: construindo pipelines na AWS
Formação AWS Data Lake: construindo pipelines na AWS
* Esta formação faz parte dos nossos cursos de Data Science
Quero Estudar na AluraPara conclusão


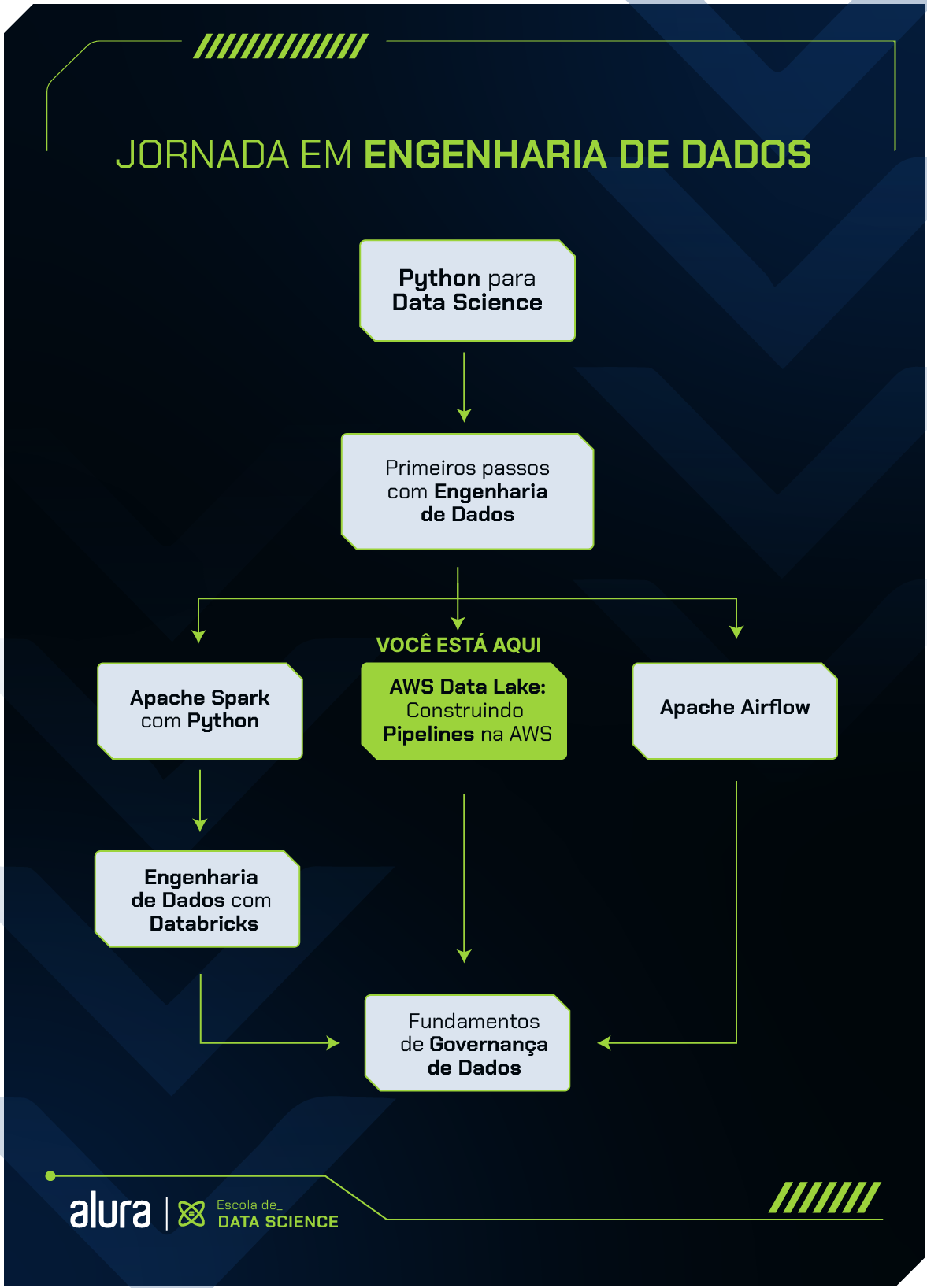
A formação AWS Data Lake da Alura tem como objetivo preparar a pessoa aluna para trabalhar com Engenharia de Dados utilizando serviços da AWS, Apache Spark e Python.
Funciona como um guia de aprendizado para auxiliar pessoas interessadas em entrar no mercado de trabalho e também como mecanismo de consulta para profissionais experientes.
A AWS (Amazon Web Services) é uma plataforma de serviços em nuvem oferecida pela Amazon. No contexto de Engenharia de Dados, a AWS desempenha um papel significativo ao fornecer uma variedade de serviços e ferramentas que facilitam a coleta, processamento, armazenamento e análise de grandes volumes de dados.
Nesta formação, vamos aprender a construir um Data Lake na AWS com uma pipeline completa desde a ingestão de dados externos, processamento e ETL, até análise de dados, construção de dashboard e construção de IaaC (Infraestrutura como Código).
Você vai manipular dados utilizando Apache Spark, Python e diferentes bibliotecas como urllib, boto3, BytesIO, entre outras. Além disso, vai aprender sobre boas práticas na manipulação de grande volume de dados, como salvar os arquivos em Parquet, aumentar o número de workers no AWS Glue e fazer processamento distribuído com AWS EMR.
Você também irá aprender sobre a criação de dashboards no Quicksight, boas práticas de DataViz, GenAI na visualização de dados, etc. Outro tópico bastante importante no dia a dia de um Engenheiro de Dados é a Infraestrutura como código, que possibilita que infraestruturas sejam rapidamente criadas e configuradas, além de permitir que códigos sejam reutilizados.
Para melhor aproveitamento do conteúdo, recomendamos que você já saiba programar em Python, tenha algum conhecimento em Spark e Cloud Computing.
Conteúdos pensados para facilitar seu estudo
Formação completa para o mercado
Do zero ao sonhado emprego em sua área de interesse
Comece essa formação agora mesmo e capacite-se para seu próximo projeto!
Conheça os planos
Ana é Administradora, Especialista em Ciência de Dados e Big Data e possui certificações AWS e Scrum. Atualmente é Coordenadora de Engenharia de Dados no Itaú Unibanco, Instrutora de Engenharia de Dados na Alura e Mentora de Carreira. Além disso, em seu tempo livre, gosta de viajar e assistir séries.
Ana é Administradora, Especialista em Ciência de Dados e Big Data e possui certificações AWS e Scrum. Atualmente é Coordenadora de Engenharia de Dados no Itaú Unibanco, Instrutora de Engenharia de Dados na Alura e Mentora de Carreira. Além disso, em seu tempo livre, gosta de viajar e assistir séries.
Neste passo inicial, preparamos um conteúdo para ajudar você a conhecer melhor a AWS, como navegar no console e manipular dados utilizando Python e algumas bibliotecas.
Na primeira etapa dessa jornada, você vai aprender a criar sua conta AWS, criar alerta de gastos, fazer ingestão de dados externos no bucket S3 com código Python e em formato Parquet, além de configurar seu Data Lake na AWS.

Artigo Data Lake: conceitos, vantagens e desafios | Alura
Artigo Data lake: On premises versus Nuvem | Alura

Curso AWS Data Lake: criando uma pipeline para ingestão de dados
08hArtigo Ingestão de dados em tempo real no Data Lake com AWS Kinesis | Alura
Artigo SoR, SoT e Spec no contexto de Engenharia de Dados | Alura
Nesta fase da formação, vamos mergulhar em outras ferramentas da AWS, conhecendo o AWS Glue e seus recursos, como Glue Crawler, Glue Catalog, Glue Studio, Glue Data Quality e Glue Brew. Com todos estes recursos, faremos o processamento ETL dos dados ingeridos no passo anterior e criaremos a camada silver no bucket S3.
Aprenderemos sobre o Catálogo de Dados na AWS, qualidade das informações obtidas e como otimizar o processamento destas informações.
Além disso, vamos explorar o processamento distribuído com o AWS EMR, conhecendo suas funcionalidades e recursos para construir a camada gold no bucket S3.
Vamos trabalhar o processamento ETL dos dados ingeridos no primeiro passo e utilizaremos todo o poder das estruturas distribuídas presentes no AWS EMR, como Apache Hadoop e Apache Spark, para otimizar o processamento do grande volume de dados que possuímos.
Artigo Arquitetura Serverless: explorando seu funcionamento, aplicações e vantagens | Alura

Curso AWS Data Lake: processando dados com AWS Glue
10hArtigo Importância e os desafios na manutenção da qualidade de dados na Cloud | Alura

Curso AWS Data Lake: processando dados com AWS EMR
08hArtigo Governança de dados em um Data Lake | Alura
Artigo Processamento de dados na AWS: Glue x EMR | Alura
Com foco na obtenção de insights, esta etapa mostrará como analisar os dados e construir dashboards com o AWS Quicksight. Você vai aprender as funcionalidades deste poderoso serviço da AWS, boas práticas de visualização de dados e construção de dashboards.

Curso AWS Data Lake: análise de dados com Athena e Quicksight
08hArtigo Storytelling com dados: transforme seus dados em narrativas envolventes | Alura
Artigo AWS QuickSight: desvendando essa ferramenta | Alura
Escola
Além dessa, a categoria Data Science conta com cursos de Ciência de dados, BI, SQL e Banco de Dados, Excel, Machine Learning, NoSQL, Estatística,e mais...
Conheça a EscolaImpulsione a sua carreira com os melhores cursos e faça parte da maior comunidade tech.
1 ano de Alura
Assine o PLUS e garanta:
Formações com mais de 1500 cursos atualizados e novos lançamentos semanais, em Programação, Inteligência Artificial, Front-end, UX & Design, Data Science, Mobile, DevOps e Inovação & Gestão.
A cada curso ou formação concluído, um novo certificado para turbinar seu currículo e LinkedIn.
No Discord, você tem acesso a eventos exclusivos, grupos de estudos e mentorias com especialistas de diferentes áreas.
Faça parte da maior comunidade Dev do país e crie conexões com mais de 120 mil pessoas no Discord.
Acesso ilimitado ao catálogo de Imersões da Alura para praticar conhecimentos em diferentes áreas.
Explore um universo de possibilidades na palma da sua mão. Baixe as aulas para assistir offline, onde e quando quiser.
Acelere o seu aprendizado com a IA da Alura e prepare-se para o mercado internacional.
1 ano de Alura
Todos os benefícios do PLUS e mais vantagens exclusivas:
Luri é nossa inteligência artificial que tira dúvidas, dá exemplos práticos, corrige exercícios e ajuda a mergulhar ainda mais durante as aulas. Você pode conversar com a Luri até 100 mensagens por semana.
Aprenda um novo idioma e expanda seus horizontes profissionais. Cursos de Inglês, Espanhol e Inglês para Devs, 100% focado em tecnologia.
Transforme a sua jornada com benefícios exclusivos e evolua ainda mais na sua carreira.
1 ano de Alura
Todos os benefícios do PRO e mais vantagens exclusivas:
Mensagens ilimitadas para estudar com a Luri, a IA da Alura, disponível 24hs para tirar suas dúvidas, dar exemplos práticos, corrigir exercícios e impulsionar seus estudos.
Envie imagens para a Luri e ela te ajuda a solucionar problemas, identificar erros, esclarecer gráficos, analisar design e muito mais.
Escolha os ebooks da Casa do Código, a editora da Alura, que apoiarão a sua jornada de aprendizado para sempre.