
Introdução
Já pensou em conseguir tornar seu projeto de dados uma aplicação web apenas utilizando a linguagem Python? O Streamlit é um framework de código aberto, criado justamente para ajudar cientistas de dados a colocarem em produção seus projetos sem a necessidade de conhecer ferramentas de front-end ou de deploy de aplicações.
Por meio desse framework é possível transformar um projeto de ciência de dados e machine learning em uma aplicação interativa. Para essa aplicação é gerada uma URL pública que, ao ser compartilhada, permite que qualquer pessoa consiga acessar e usufruir sem necessariamente ter que conhecer o código que está por trás.
Considerando todas essas características do Streamlit, essa ferramenta se torna uma excelente maneira de apresentar projetos técnicos para pessoas que são leigas na área. Além de deixar a apresentação com uma aparência muito profissional.
Para o desenvolvimento do projeto a seguir, será utilizado o editor de código Visual Studio Code.

Configurando o ambiente
Para começar, vamos criar um ambiente virtual onde iremos instalar as bibliotecas que serão utilizadas no desenvolvimento do projeto. Podemos criar uma pasta onde ficarão os arquivos do nosso projeto, nomeá-la como "Artigo_Streamlit", por exemplo, e em seguida, acessá-la por meio do editor de código.
Na pasta podemos criar um arquivo chamado requirements.txt para colocar as bibliotecas que queremos instalar no nosso ambiente virtual:
pandas
seaborn
matplotlib
streamlitDepois disso, para criar, ativar e instalar os pacotes no ambiente virtual , podemos abrir o terminal do próprio editor de texto utilizando o atalho Ctrl + J e executar os seguintes comandos:
Criando o ambiente:
python -m venv venvAtivando o ambiente:
No Windows:
venv\Scripts\activateNo Linux ou Mac:
source venv/bin/activateInstalando os pacotes do requirements.txt:
pip install -r requirements.txtCom o ambiente configurado, podemos começar a desenvolver nosso projeto!
Criando o primeiro app utilizando Streamlit
Dentro da pasta do projeto, vamos criar um script chamado app.py onde iremos digitar o nosso código python. Nesse script faremos um primeiro teste com o Streamlit com o seguinte código:
import streamlit as st
# escrevendo um título na página
st.title('Minha primeira aplicação :sunglasses:')Para conseguirmos visualizar esse código em ação, podemos abrir o terminal e digitar o seguinte comando:
streamlit run app.pyApós alguns segundos, uma página deve abrir apresentando o texto que escrevemos, juntamente com um emoji:

Assim, temos nossa primeira aplicação rodando! No entanto, observe que nesse link está escrito localhost:8501, o que indica que nossa aplicação está rodando apenas localmente, ou seja, ela ainda não está disponível na web para outras pessoas acessarem.
Se voltarmos ao código e fizermos alguma alteração como, por exemplo, apagar o emoji :sunglasses: do comando st.title, vai aparecer o seguinte alerta no canto superior direito da página:
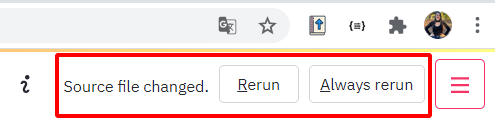
Esse alerta está indicando que foram realizadas alterações no arquivo fonte desta página. Ao lado do alerta, são indicadas duas opções: Rerun (Rodar novamente) e Always rerun (Sempre rodar novamente). Quando selecionamos a opção "Rerun" nossa página será recarregada e as alterações feitas no arquivo serão aplicadas. Se optarmos por "Always Rerun" esse processo de recarregar a página toda vez que for realizada uma alteração passará a ser automático.
Agora que entendemos um pouco sobre o funcionamento do Streamlit, podemos começar a desenvolver algo um pouco mais elaborado.
Criando sua primeira aplicação de dados
Como o intuito deste artigo é explorar algumas das funcionalidades do Streamlit, não iremos nos aprofundar nos conceitos de ciência de dados utilizados no projeto. Vamos fazer uma aplicação na qual será apresentada uma tabela e um gráfico, de forma que existirão alguns filtros.
Para desenvolver o projeto a seguir, foi utilizada uma base de dados de produtos de supermercado. Você pode acessá-la clicando no repositório. Com o arquivo baixado, podemos salvá-lo na pasta do nosso projeto.
No arquivo app.py podemos apagar o trecho de código escrito anteriormente e fazer as seguintes importações:
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import streamlit as stApós isso, vamos digitar o seguinte código:
# importando os dados
dados = pd.read_csv('estoque.csv')
st.title('Análise de estoque\n')
st.write('Nesse projeto vamos analisar a quantidade de produtos em estoque, por categoria, de uma base de dados de produtos de supermercado')Nessa primeira parte estamos apresentando um título e um pequeno texto logo abaixo dele. À medida que vamos desenvolvendo nosso projeto, é interessante ir acompanhando o progresso também por meio da visualização da página.
Agora, vamos começar com a criação dos filtros para apresentar o dataframe na nossa aplicação:
# filtros para a tabela
checkbox_mostrar_tabela = st.sidebar.checkbox('Mostrar tabela')
if checkbox_mostrar_tabela:
st.sidebar.markdown('## Filtro para a tabela')
categorias = list(dados['Categoria'].unique())
categorias.append('Todas')
categoria = st.sidebar.selectbox('Selecione a categoria para apresentar na tabela', options = categorias)
if categoria != 'Todas':
df_categoria = dados.query('Categoria == @categoria')
mostra_qntd_linhas(df_categoria)
else:
mostra_qntd_linhas(dados)A primeira etapa que estamos realizando nesse código é a criação de uma barra lateral por meio do método sidebar na nossa página. Nessa barra, ficarão localizados nossos filtros, de forma que os componentes fiquem dispostos de um modo mais organizado. Portanto, toda vez que visualizarmos o comando st.sidebar antecedendo algum componente, significa que aquele componente estará localizado na barra lateral esquerda.
Nessa barra lateral, estamos adicionando primeiramente um checkbox "Mostrar tabela". Quando o(a) usuário(a) selecionar essa opção, aparecerão algumas alternativas de filtros e o dataframe será apresentado no meio da página.
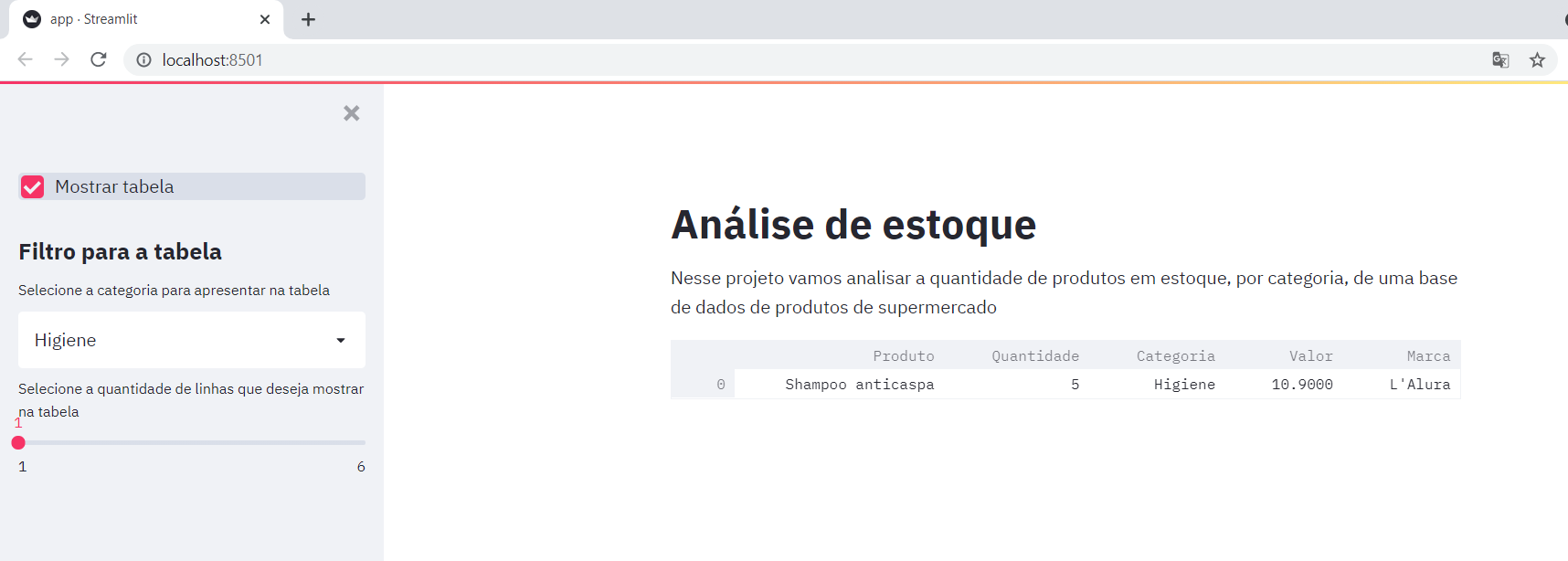
Para filtrar a categoria, utilizamos uma selectbox, onde colocamos como opções cada uma das categorias e também a opção "Todas" para mostrar todas as categorias. Abaixo dessa selectbox, temos um segundo filtro que permite escolher a quantidade de linhas do dataframe que queremos apresentar. Esse filtro, é definido na função mostra_qntd_linhas() que deve ser adicionada no início do nosso código, logo após as importações das bibliotecas:
# função para selecionar a quantidade de linhas do dataframe
def mostra_qntd_linhas(dataframe):
qntd_linhas = st.sidebar.slider('Selecione a quantidade de linhas que deseja mostrar na tabela', min_value = 1, max_value = len(dataframe), step = 1)
st.write(dataframe.head(qntd_linhas).style.format(subset = ['Valor'], formatter="{:.2f}"))Essa função apresenta um elemento chamado slider que é a barra de valores que permite escolher a quantidade de linhas desejadas para a visualização do dataframe, sendo o valor mínimo igual a 1 e o máximo igual a quantidade máxima de linhas de acordo com a categoria previamente escolhida.
O st.write, nesse caso, é responsável por apresentar o dataframe de acordo com a quantidade de linhas escolhida. O método style.format que encontra-se dentro do write, está sendo utilizado para especificar que os valores da coluna "Valor" devem apresentar apenas duas casas decimais após a vírgula.
Para finalizar nosso script, vamos criar um filtro para apresentar nosso gráfico de acordo com a categoria:
# filtro para o gráfico
st.sidebar.markdown('## Filtro para o gráfico')
categoria_grafico = st.sidebar.selectbox('Selecione a categoria para apresentar no gráfico', options = dados['Categoria'].unique())
figura = plot_estoque(dados, categoria_grafico)
st.pyplot(figura)Com esse código estamos criando um "subtítulo" por meio do st.markdown e criando mais uma selectbox onde a pessoa pode selecionar a categoria que deseja visualizar no gráfico. A opção selecionada é armazenada na variável categoria_grafico e em seguida esse gráfico é criado através da função plot_estoque(). Essa função utiliza as bibliotecas seaborn e matplotlib para criar o gráfico e retornar uma figura, que é apresentada na nossa página por meio do st.pyplot.
A função plot_estoque deve ser criada no início do nosso script, logo após a função mostra_qntd_linhas. Você pode acessar o código dessa função clicando aqui.
Feito isso, vamos ter na nossa página um filtro para selecionar a categoria que desejamos visualizar no gráfico:
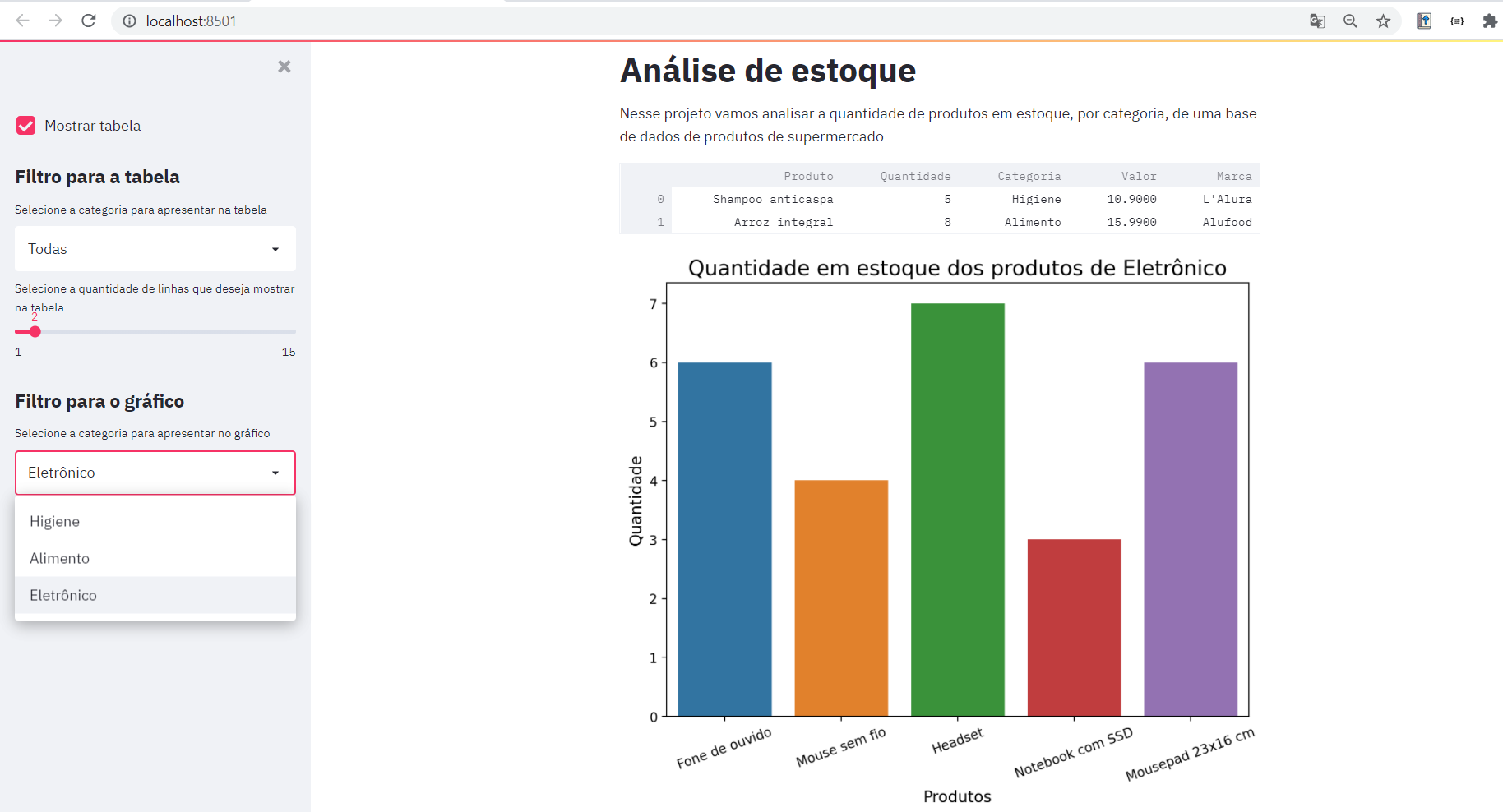
Assim, finalizamos nosso projeto. Mas, antes de colocá-lo no ar, precisamos criar um repositório e adicioná-lo ao GitHub. Bora fazer isso?
Criando um repositório para nosso projeto
Para criarmos um repositório é necessário ter uma conta no GitHub.
Existem diferentes formas de subir um projeto para o GitHub. Todavia, como nosso foco principal é o Streamlit, iremos optar por fazer upload do nosso projeto para o Github da forma mais simples, que é diretamente pela própria interface desse site, sem nos aprofundarmos muito nesse quesito.
Após entrar na nossa conta do GitHub, podemos acessar a parte de repositórios e clicarmos para criar um novo repositório. Nessa tela devemos dar um nome e selecionar o checkbox "Add a README file" para que seja criado um arquivo README. O nome do repositório vai ser "Artigo_Streamlit_Alura".
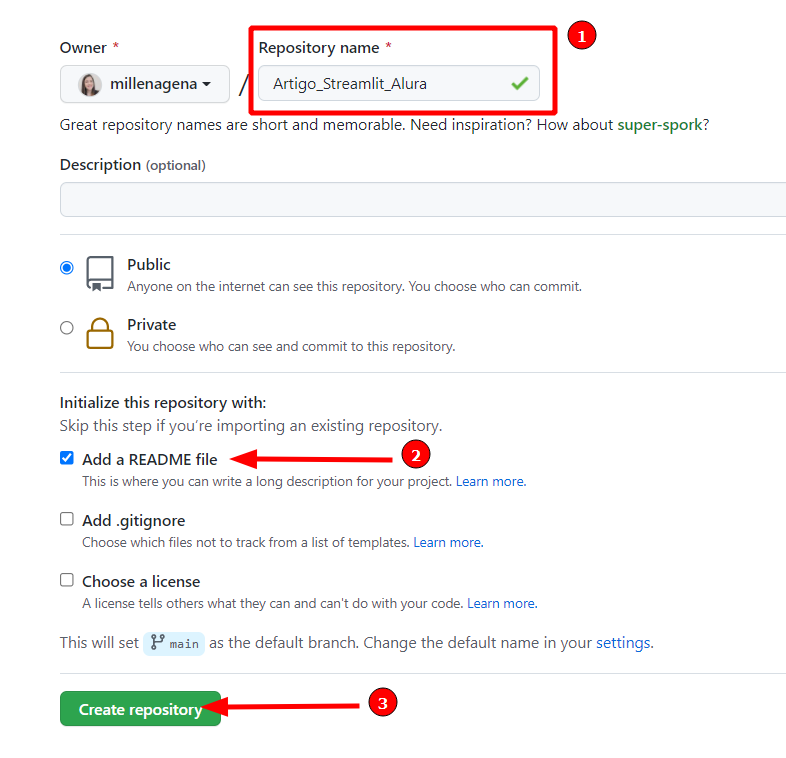
Para finalizar a criação desse repositório, podemos clicar na opção "Create repository". Com o repositório criado, podemos adicionar nossos arquivos nele. Para fazer isso, vamos selecionar a opção Add file > Upload files.
Na tela que aparecer, clicamos em "choose your files", acessamos a pasta que possui os arquivos do nosso projeto e selecionamos aqueles que queremos fazer upload para o repositório. Vamos selecionar apenas os arquivos: app.py, estoque.csv e requirements.txt e clicar em "Commit changes" para salvar as alterações.
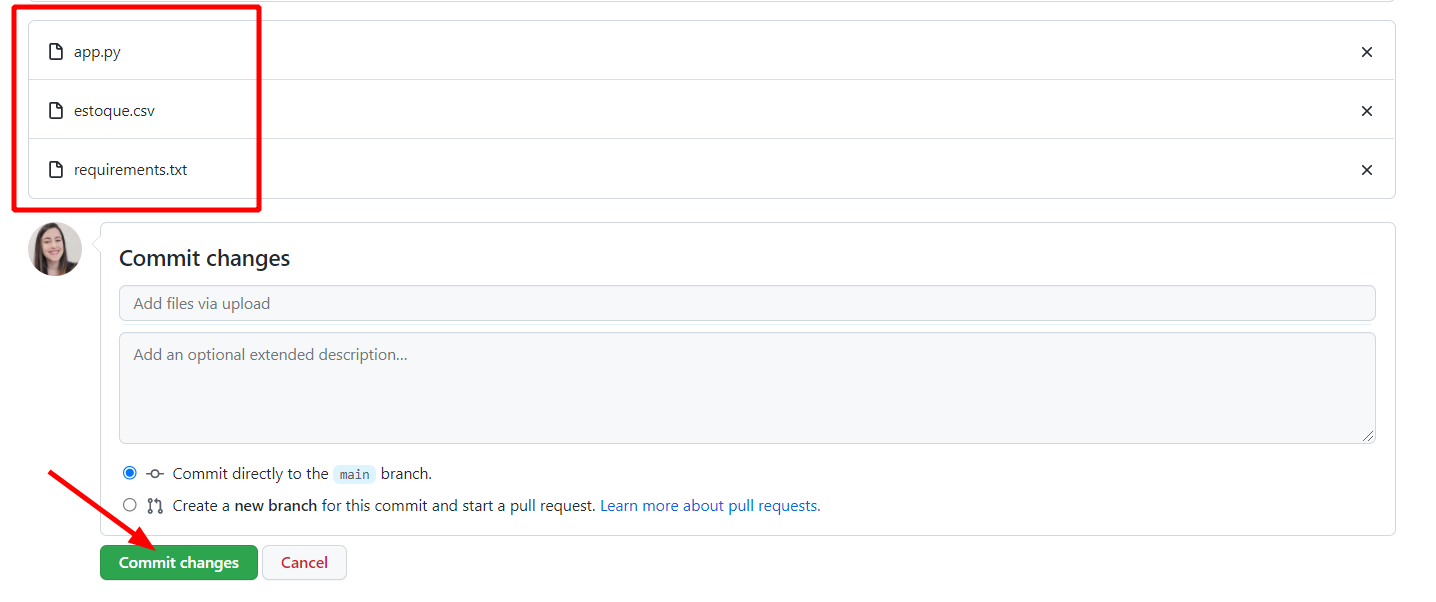
Agora nosso projeto está pronto para fazermos o deploy. Vamos para a parte final?
Solicitando acesso à nuvem do Streamlit
Para conseguirmos fazer o deploy, precisamos solicitar acesso às máquinas virtuais da nuvem do Streamlit. Essa solicitação é realizada diretamente pela documentação.
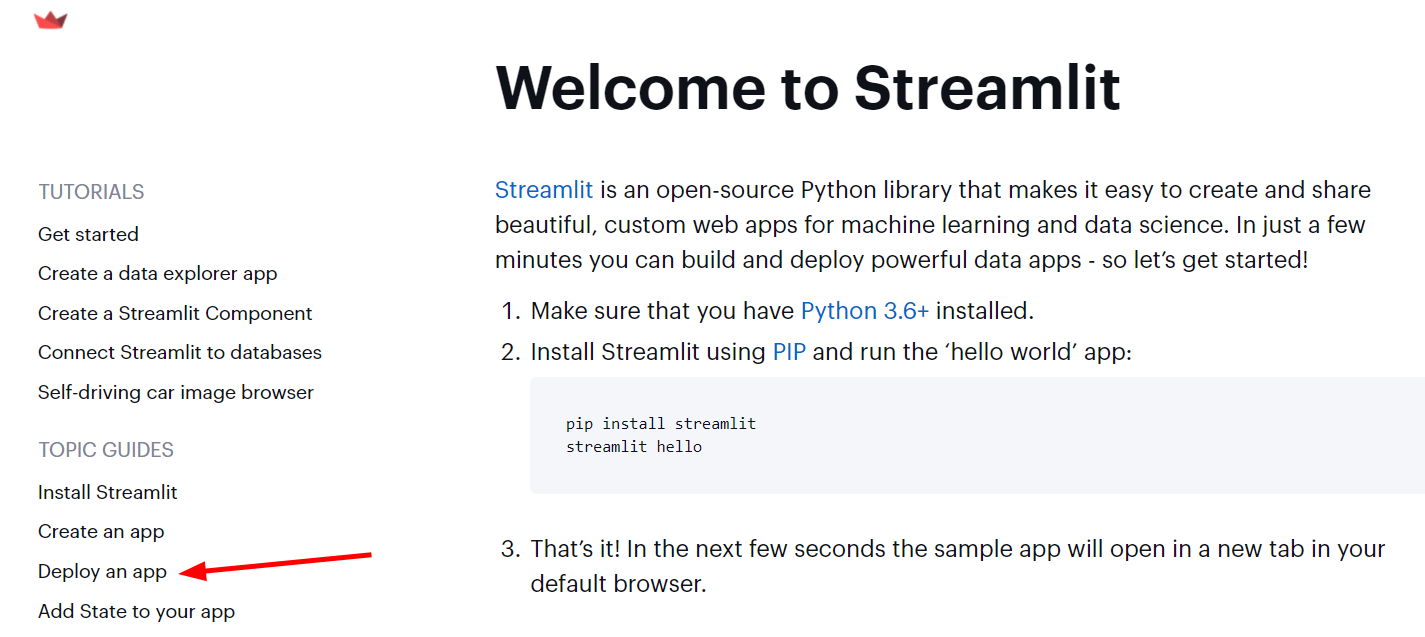
Após clicar em "Deploy an app", no texto logo abaixo o título "Sign up for Streamlit Cloud", vamos encontrar um link de cadastro para conseguirmos solicitar o acesso às máquinas virtuais dessa ferramenta. Você também pode acessar esse link clicando aqui.
Nesse link há um formulário de cadastro onde devemos preencher com nosso primeiro nome, último nome e e-mail que utilizamos no GitHub. O último campo não é necessário preencher. Com os campos de nome e e-mail preenchidos, podemos clicar em "Sign Up Now".
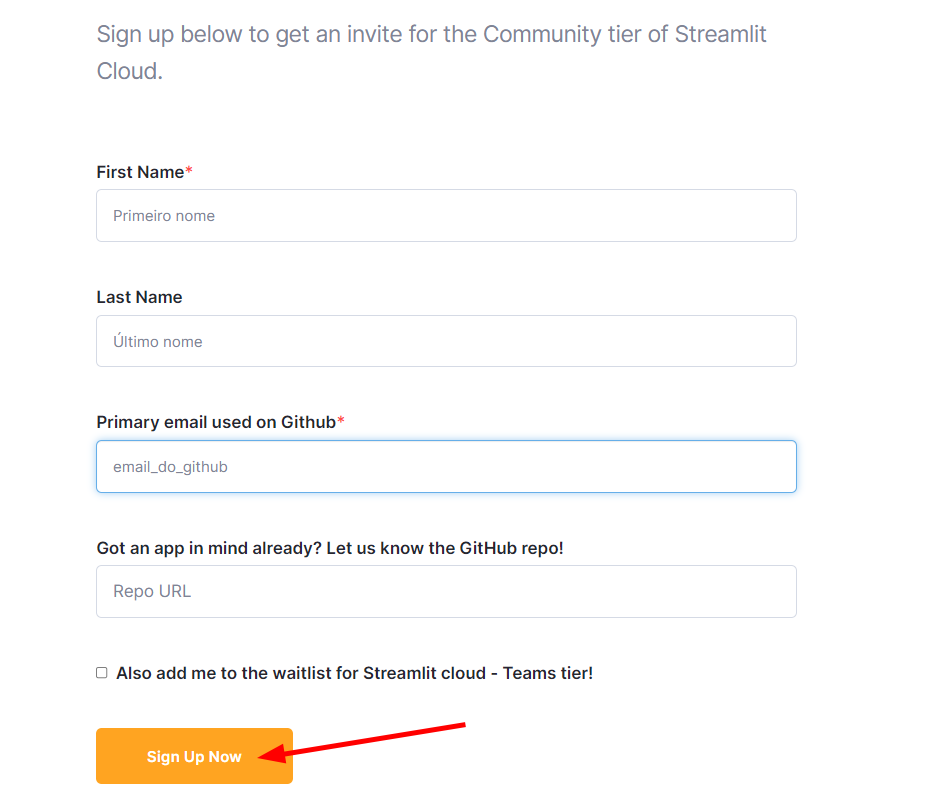
Feito o cadastro, pode ser que o Streamlit demore de 1 a 2 dias úteis para liberar o acesso. Nesse meio tempo, é importante ficarmos atentos ao nosso e-mail, pois assim que for liberado é enviado uma confirmação.
Realizando o deploy da nossa aplicação
Depois de recebermos o e-mail confirmando nosso cadastro, podemos fazer o login no site do Streamlit clicando aqui. Nessa tela, existem algumas opções para fazer o login, podemos escolher a primeira "Continue with GitHub".
A próxima tela que aparecer possui o título Your apps. Nela existe uma opção destacada em azul na parte superior direita da tela, essa opção é chamada "New app". Para adicionar uma nova aplicação clicamos nela.
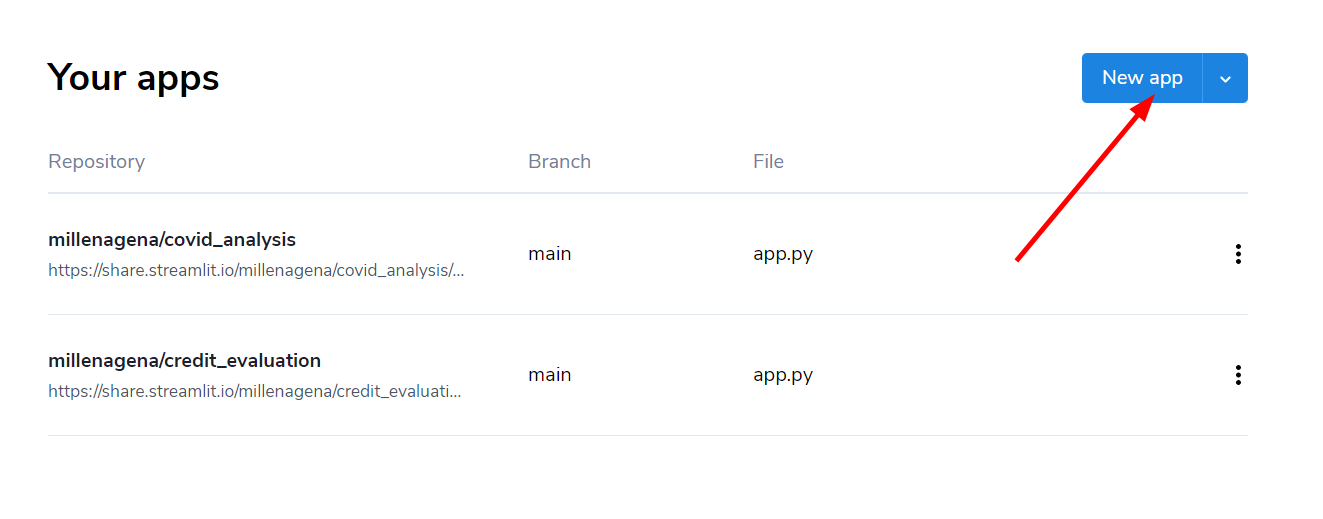
Informaremos os dados do nosso projeto no GitHub na página "Deploy an app". Na primeira parte do formulário, devemos colocar o repositório onde está nosso projeto. Você pode fazer isso colocando seu nome de usuário do GitHub, uma barra e o nome do repositório: nome_de_usuario_github/Artigo_Streamlit_alura, ou ainda pode copiar o link do repositório e colar.
Na segunda parte do formulário, a Branch, não é necessário fazer nenhuma alteração agora. Em "Main file path" devemos colocar o nome do arquivo que está no GitHub com o código principal da nossa aplicação. No nosso caso, esse é o app.py.
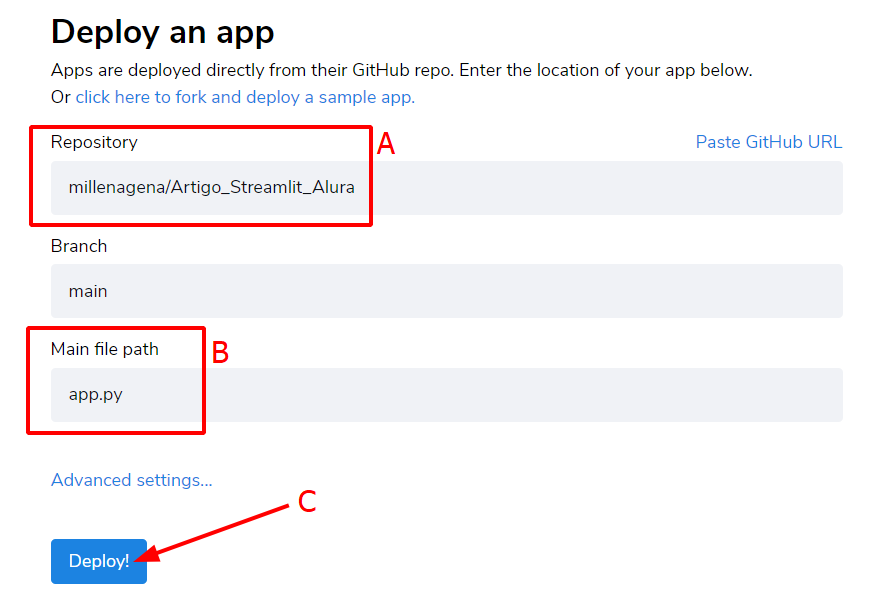
Feito o preenchimento do formulário, podemos clicar em "Deploy!" para começar a realizar o deploy da nossa aplicação. Esse processo pode demorar alguns minutos para carregar.
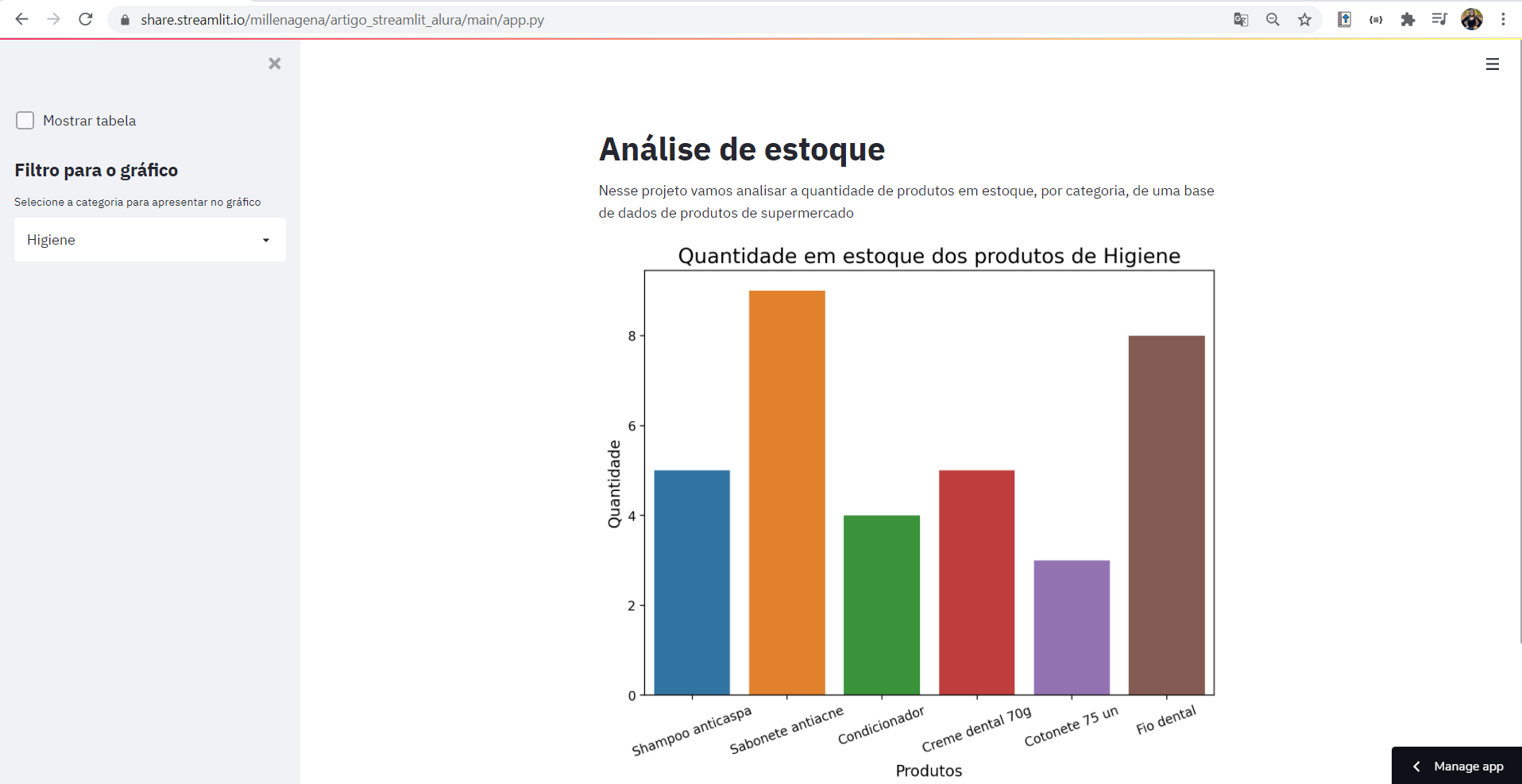
Agora a aplicação está finalizada e pronta para ser compartilhada!
Observe que não temos mais aquela url com "localhost" escrita. Isso indica que a aplicação não está rodando apenas localmente na nossa máquina, mas em uma máquina virtual permitindo que qualquer pessoa consiga acessá-la.
Você pode acessar a aplicação criada neste artigo, clicando nesse link.
Gostou do conteúdo e quer mergulhar ainda mais nesse mundo da ciência de dados? Não deixe de conferir nossa Formação Python para Data Science, o curso Data Visualization: criação de gráficos com o Matplotlib e o artigo VisualStudio Code: instalação, teclas de atalho, plugins e integrações.
