

Introdução
Em aplicações científicas, de engenharia e principalmente de ciência de dados existe a necessidade de realizar cálculos numéricos especializados.
Quando você faz a soma de todos os valores de uma coluna em um software de planilhas ou mesmo operações matemáticas entre as diferentes colunas, existe um código implementado para tornar essas operações possíveis. Da mesma forma, se você já usou uma função de uma biblioteca Python que faz regressão linear ou um algoritmo de machine learning qualquer, saiba que esses códigos são a tradução de um conjunto de equações matemáticas para código. Essas implementações precisam ser eficientes e fáceis de compreender. Quanto mais próximo o código escrito estiver da escrita da matemática, melhor.
Nesse contexto, em Python, surge a NumPy. Essa é uma biblioteca poderosa e amplamente utilizada que revolucionou o segmento de computação científica. Isso, principalmente, pelo caráter aberto da linguagem Python. Com a NumPy, é possível realizar operações matemáticas complexas com objetos do tipo array de forma eficiente e otimizada. Mas o que exatamente é e como funciona a Numpy?

O que é o NumPy?

NumPy, uma abreviação de Numerical Python, é uma biblioteca de código aberto do Python para computação científica, campo de estudo que utiliza recursos computacionais para entender e resolver problemas. Essa biblioteca permite trabalhar com a manipulação de objetos array multidimensionais, além de seus objetos derivados, como matrizes, sequências, e outros. Além disso, também possui uma grande variedade de operações rápidas com os arrays, incluindo operações matemáticas e lógicas, manipulações de formato, ordenação e seleção, ferramentas de estatística e cálculo, e muito mais.
A biblioteca NumPy foi lançada em 2005, pelo cientista de dados Travis Oliphant, com a proposta de ser uma ferramenta rápida, eficiente e fácil de usar, permitindo assim a realização de cálculos numéricos e matemáticos em larga escala, por meio da funcionalidade chamada vetorização. Por isso, tornou-se uma das bases fundamentais para análise de dados, aprendizado de máquina (machine learning) e computação científica em geral, estando presente também na construção de várias bibliotecas de ciência de dados, incluindo: Pandas, Matplotlib, Scikit-learn, SciPy, e muitas outras.
Uma curiosidade sobre essa biblioteca é que ela também esteve presente nos trabalhos de descobertas científicas recentes importantes, como a detecção da primeira imagem de um buraco negro, e também a detecção de ondas gravitacionais.
Mas como exatamente funciona o NumPy?
Estruturas básicas do NumPy
A Numpy funciona por meio de estruturas chamadas arrays, que são estruturas de dados homogêneas, isto é, onde os elementos possuem o mesmo tipo. Essas estruturas podem ter vários formatos e dimensões, que variam com a necessidade de cada tipo de projeto. De maneira geral, para vários tipos de aplicações, trabalhamos até a terceira dimensão, mas existem casos onde podemos necessitar de mais.
O conceito de dimensão pode ser aplicado no Python a partir do conceito das listas aninhadas (nested lists). Para isso, vamos usar as seguintes estruturas:

Escalar: um elemento único, adimensional. Pode ser um inteiro, float, hexadecimal, caractere, e vários outros tipos de dado.
No Python, após importar a biblioteca, nós definimos um escalar como:
import numpy as np
np.array(42)Array unidimensional: uma lista de escalares onde podemos identificar cada um deles pela sua posição, ou índice, na lista. É preciso ressaltar que todos os elementos escalares aqui possuem o mesmo tipo, e que se não for especificado durante a definição do array, o Numpy trabalhará uma rotina para determinar o tipo que garanta a característica homogênea.
np.array([4, 5, 22, 20])Array bidimensional: uma lista de arrays unidimensionais, com o formato de uma matriz (tabela), onde precisamos especificar uma posição de linha e uma posição de coluna para localizar um elemento escalar.
np.array([[3, 2, 7],
[4, 9, 1],
[5, 6, 8]])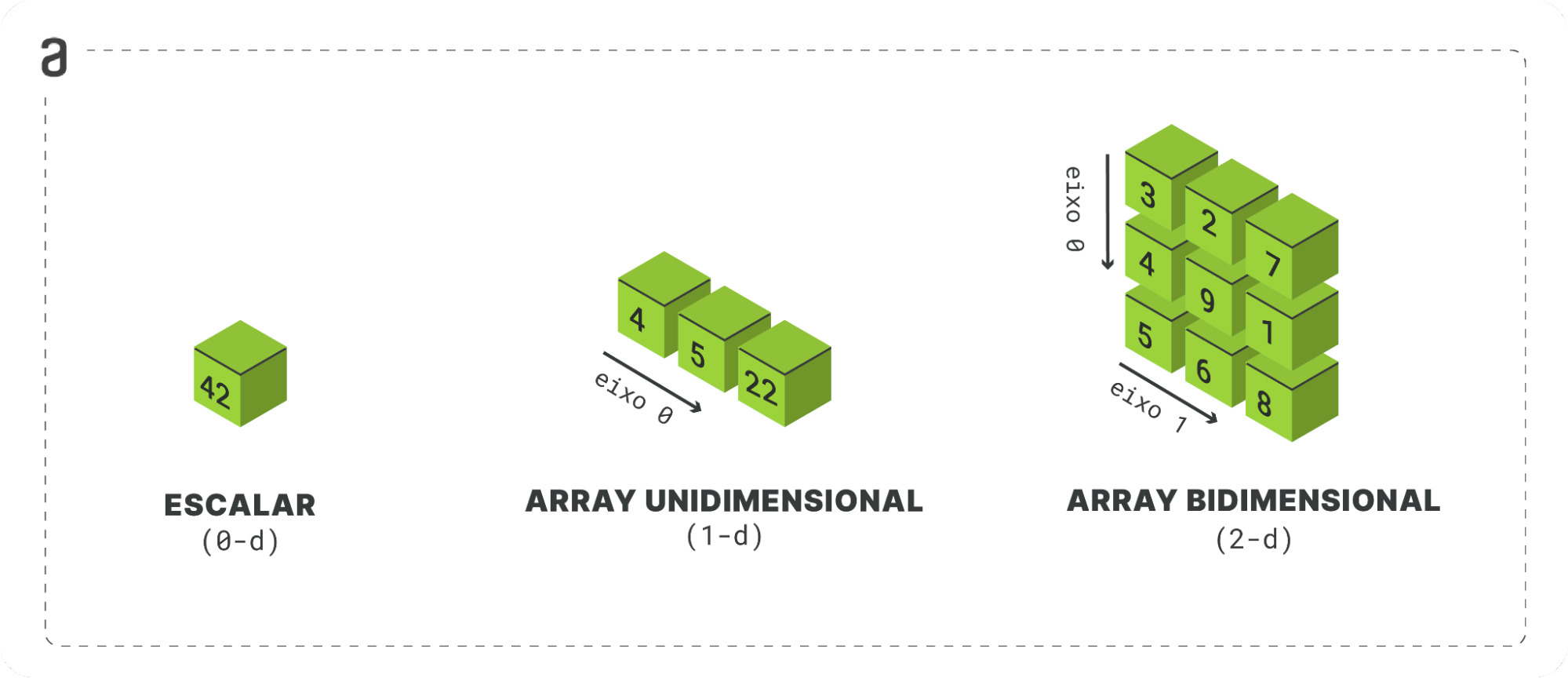
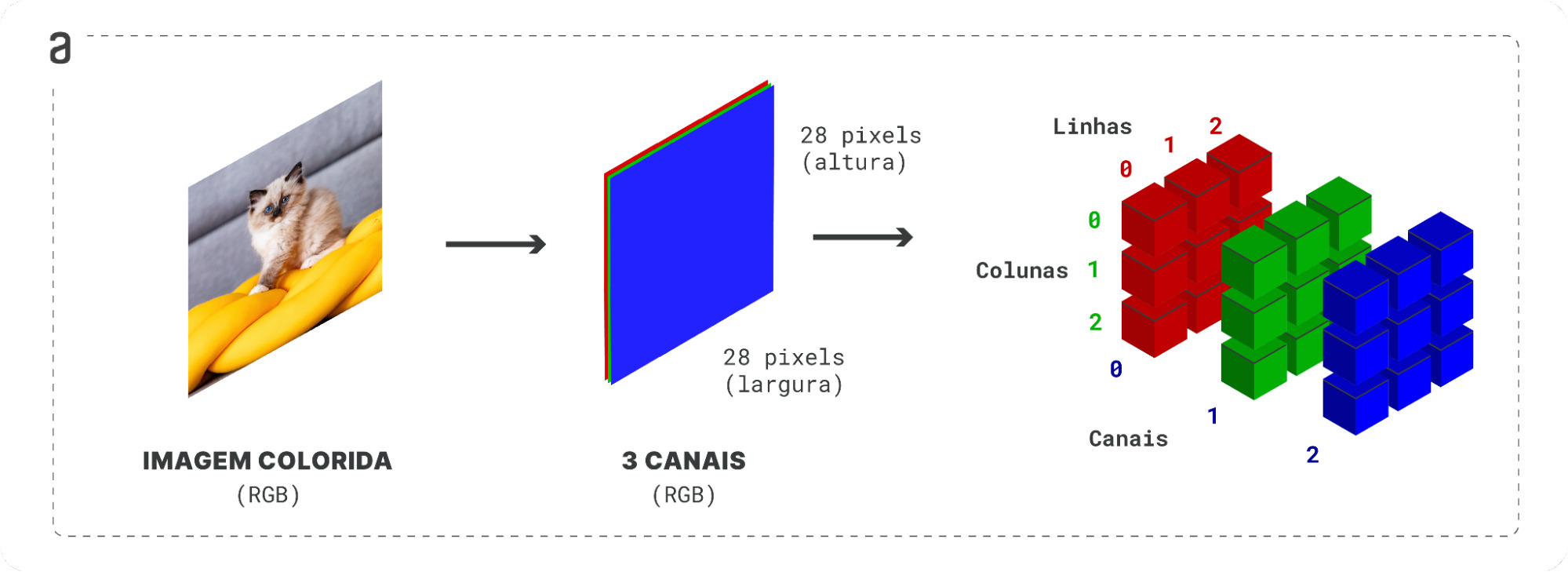
Array tridimensional: uma lista de arrays bidimensionais. Um exemplo de aplicação de array tridimensional é a matriz de imagem RGB, possível de se observar no funcionamento de uma televisão. Nesse caso, nós temos uma estrutura bidimensional (o formato da tela), em que podemos localizar uma unidade de pixel com uma referência na vertical, e outra na horizontal. Para cada unidade de pixel, também temos uma representação de um array de 3 elementos, que é a junção de três leds de cores vermelha, verde e azul. Então, a nível fundamental, podemos interpretar uma imagem como:
Array multidimensional (n-dimensional): as operações de criação de arrays no Numpy não estão limitadas apenas às dimensões anteriores: é possível construir estruturas de quantias maiores, tanto quanto mais forem necessárias, desde que o critério dos objetos de mesmo nível possuam o mesmo formato. Uma maneira de ilustrar esses novos níveis é através do seguinte esquema:
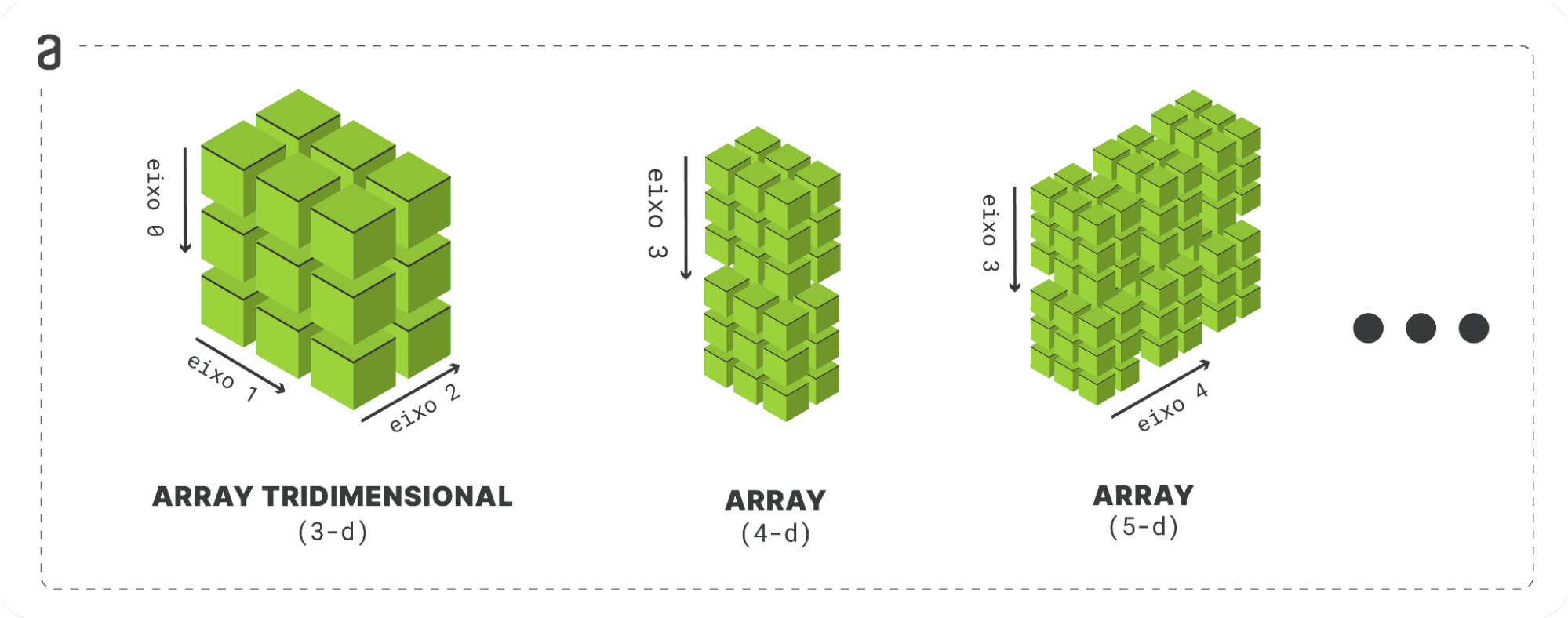
Nesse esquema, quando chegamos à quarta dimensão e além, é mais difícil visualizar a matriz como um objeto geométrico. Em vez disso, podemos interpretar uma matriz de ordem superior como um objeto matemático que contém informações sobre outros objetos matemáticos.
Por exemplo, uma matriz de quarta ordem pode ser vista como uma matriz de matrizes de matrizes, ou seja, cada elemento da matriz é uma matriz de matrizes. Podemos interpretar essa matriz como um objeto matemático que contém informações sobre vários objetos matemáticos mais simples.
Broadcasting
O broadcasting é uma funcionalidade do Numpy que permite trabalhar com operações em arrays de formas e tamanhos diferentes, sem que seja necessário criar cópias dos dados. Por esse motivo, é uma técnica que economiza tempo e memória. Em muitos casos, o broadcasting pode reduzir o número de linhas de código necessárias para realizar uma determinada operação.
Por exemplo, na operação abaixo:
import numpy as np
a = np.array([[1, 2], [3, 4]])
b = np.array([10, 20])
a + bNo exemplo acima, trabalhamos com a soma de dois arrays com dimensões diferentes, no caso, um array unidimensional e uma matriz. No entanto, o Numpy consegue analisar as dimensões, através de regras pré-estabelecidas, e executar a operação, retornando:
array([[11, 22],
[13, 24]])NumPy na computação científica
Por ser uma biblioteca do Python, uma grande vantagem de trabalhar com o NumPy é a possibilidade de integração com outras bibliotecas do grande ecossistema do Python. Isso abre espaço para trabalhar com soluções end-to-end, que atendem desde o início, com coletas de dados, processamento, até a entrega do produto final, por exemplo, uma dashboard ou sistema com uma análise detalhada de modelos de aprendizado de máquina.
Essas características, somadas ao fato da biblioteca ser de código aberto e livre, tornam o NumPy um grande concorrente de outras soluções presentes no mercado e meio acadêmico, tais como o MATLAB, Octave, Scilab, entre outros.
Instalação do NumPy
Assim como em algumas outras bibliotecas importantes na Ciência de Dados, como o Pandas, a instalação sugerida como sendo a mais simples na documentação do NumPy é através da instalação do Anaconda.

O Anaconda é um ambiente de desenvolvimento voltado para Ciência de Dados com Python e R, que trás instaladas várias bibliotecas e softwares de uso popular no ramo. Dentre as bibliotecas instaladas, temos também o NumPy. Você pode aprender como instalar o Anaconda no Windows através da documentação oficial do Anaconda.
Uma outra maneira de instalar a biblioteca NumPy é utilizando o gerenciador de pacotes do Python, o PIP.
Desde que você tenha feito o download do Python a partir do site oficial, podemos utilizar o seguinte procedimento:
Atenção: Caso você tenha mais de um disco rígido na sua máquina, é preciso garantir que a instalação está sendo feita no mesmo disco onde o Python foi instalado.
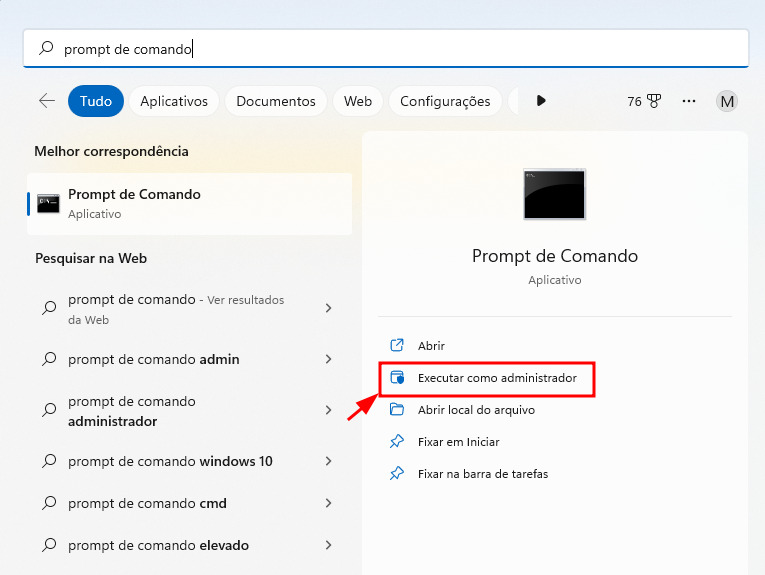
1) Para começar, devemos abrir o Prompt de Comando do seu sistema operacional. No Windows, pressione as teclas de atalho Windows + R, digite “Prompt de Comando”, e clique na opção “Executar como administrador”:
2) O Prompt de Comando será aberto e surgirá a tela preta do terminal. Nesse momento, podemos verificar a versão do Python instalada na máquina com o comando python --version e garantir que podemos continuar:
python --versionPython 3.9.73) Caso você ainda não tenha o PIP instalado na máquina, pode instalá-lo utilizando um módulo nativo do Python para isso, com o comando:
python -m ensurepip --upgrade4) E, agora que já temos o PIP instalado na máquina, podemos utilizá-lo para instalar o NumPy, com o comando:
pip install numpy5) Pronto, agora nós já temos o NumPy instalado na máquina.
Indo além
Se você deseja mergulhar ainda mais nos conteúdos de Pandas e Ciência de Dados, aqui na Alura nós temos a Formação Python para Data Science. A formação aborda as principais ferramentas utilizadas em Ciência de Dados com Python, tais como Pandas, Numpy, Matplotlib, Seaborn, e muito mais. Nela, construímos vários projetos práticos para compor o seu portfólio como profissional de dados.
E se você já deu seus primeiros passos nessa ferramenta, te convidamos a participar dos Challenges de Data Science. Neles, você pode trabalhar na construção de um portfólio de projetos, desenvolvendo habilidades em limpeza, tratamento e visualização de dados, e também competências em Machine Learning.
Links úteis:
- Computação Evolucionária: Aplique os algoritmos genéticos com Python e Numpy
- Numpy Guide (livro do autor)
- Livro Python for Data Analysis 3rd online version
Créditos
Conteúdo:
Produção técnica:
Produção didática:
Designer gráfico:
