

Hoje em dia, com a era digital e as aplicações exigindo mais em termos de disponibilidade e escalabilidade, os bancos de dados que suportam essas aplicações devem garantir sua acessibilidade a todo momento, bem como oferecer segurança na qualidade das informações disponíveis nos sistemas e relatórios que estão sendo suportados por esses mesmos bancos.
O MySQL, um dos bancos de dados mais utilizados no mundo, oferece recursos para configurar e gerenciar a replicação de dados, essencial para manter a integridade e a disponibilidade dos dados.
Mas por que a replicação de dados é tão importante? Para responder a essa pergunta, precisamos entender o que é uma replicação de banco de dados.
Neste artigo, vamos explorar essa questão e outras relacionadas à capacidade dos bancos de dados de garantir alta disponibilidade e integridade dos dados armazenados. Vamos nessa?
O que é replicação de banco de dados?
A replicação de banco de dados é a técnica que consiste em manter os mesmos dados em múltiplos servidores.
Esta prática garante que as mesmas informações estejam disponíveis em diferentes locais aumentando a redundância e a resiliência do sistema.
No contexto do MySQL, a replicação envolve a transferência de dados de um servidor principal (master) para um ou mais servidores secundários (slaves).
O servidor master é responsável por todas as operações de escrita e, ao mesmo tempo, envia atualizações aos servidores slaves, que são configurados para manter uma cópia precisa dos dados.
Esta técnica permite melhorar a disponibilidade dos dados, balancear a carga de leitura e facilitar a recuperação em caso de falhas.
Por exemplo, em um cenário onde a demanda por leitura de dados é alta, a replicação permite que múltiplos servidores atendam a essas requisições, distribuindo a carga e melhorando o desempenho geral do sistema.
Além disso, a replicação pode ser configurada de diferentes maneiras para atender a necessidades específicas.
Pode-se optar por uma replicação assíncrona, onde os slaves atualizam seus dados de tempos em tempos, ou síncrona, onde as atualizações são instantâneas, embora essa última opção possa introduzir alguma latência.

Qual é a importância da replicação em ambientes de produção
A replicação de banco de dados desempenha um papel crucial em ambientes de produção, onde a disponibilidade, a integridade e o desempenho dos dados são essenciais para as operações diárias das empresas.
Aqui estão alguns dos motivos principais pelos quais a replicação é vital nesses cenários:
Alta disponibilidade: Em ambientes de produção, a disponibilidade contínua dos dados é imprescindível. A replicação de banco de dados assegura que, mesmo em caso de falha de um servidor, outros servidores possam continuar a fornecer acesso aos dados. Essa redundância minimiza o tempo de inatividade e garante que as operações do negócio não sejam interrompidas.
Distribuição de carga: A replicação permite a distribuição de cargas de leitura entre vários servidores. Em um cenário de alto tráfego, essa distribuição melhora significativamente o desempenho do sistema, evitando gargalos e aumentando a capacidade de resposta das aplicações que dependem do banco de dados.
Recuperação de desastres: Em caso de desastres, como falhas de hardware, ataques cibernéticos ou erros humanos, a replicação oferece uma camada adicional de segurança. Os dados replicados em múltiplos servidores podem ser utilizados para restaurar rapidamente as operações normais, minimizando a perda de dados e o impacto nas operações.
Manutenção sem interrupções: A manutenção regular dos servidores de banco de dados é necessária para garantir seu bom funcionamento. A replicação permite que essas tarefas de manutenção sejam realizadas sem causar interrupções no acesso aos dados. Enquanto um servidor está em manutenção, os servidores replicados podem continuar a atender às solicitações de dados.
Geolocalização e latência reduzida: Em empresas globais, a replicação pode ser usada para manter cópias de bancos de dados em diferentes regiões geográficas. Isso reduz a latência para os usuários finais, pois eles podem acessar servidores mais próximos de suas localizações físicas, melhorando a experiência do usuário e a eficiência do sistema.
Segurança e conformidade: A replicação de dados também ajuda a garantir a conformidade com regulamentações que exigem redundância e backup de dados. Além disso, em caso de perda de dados ou corrupção no servidor principal, os servidores replicados oferecem uma fonte segura para recuperação.
Tipos de replicação
No MySQL podemos implementar a replicação dos dados de diversas maneiras. Iremos apresentar as três principais e mais utilizadas:
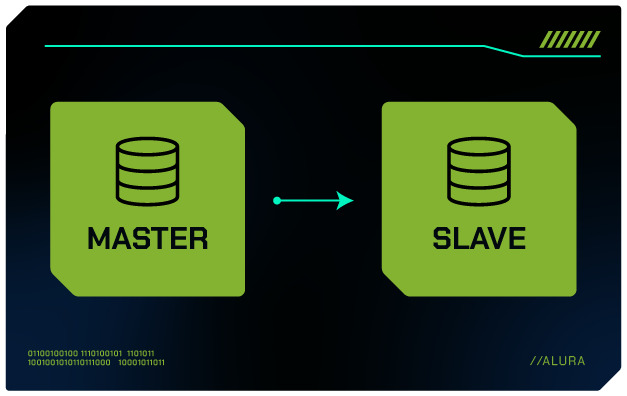
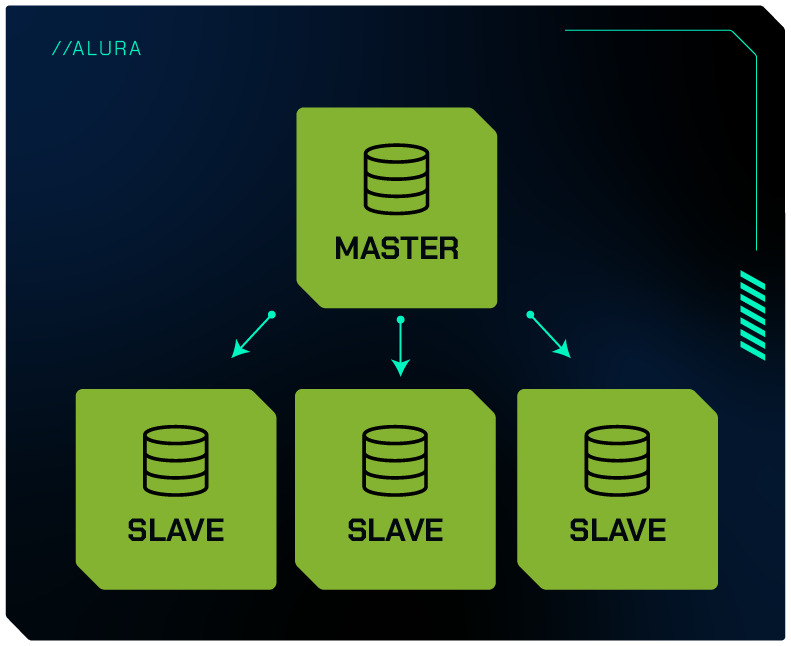
Replicação Master-Slave
A replicação Master-Slave é um dos métodos mais comuns e amplamente utilizados no MySQL. Nesse modelo, um servidor principal (Master) é responsável por todas as operações de escrita, enquanto um ou mais servidores secundários (Slaves) mantêm cópias dos dados do Master e são usados principalmente para operações de leitura. Esse arranjo oferece várias vantagens e é fundamental entender seu funcionamento e aplicação.
Vantagens
Este método de replicação apresenta algumas vantagens:
- Desempenho Aprimorado: A distribuição das operações de leitura entre múltiplos Slaves pode melhorar significativamente o desempenho do sistema, especialmente em ambientes de alta demanda.
- Alta Disponibilidade: Em caso de falha do Master, os Slaves podem ser promovidos a Master, garantindo a continuidade do serviço.
- Backups Sem Impacto: Os Slaves podem ser usados para realizar backups de dados sem afetar o desempenho do Master.
- Escalabilidade: Facilita a escalabilidade horizontal, permitindo a adição de mais Slaves conforme a necessidade.
Desafios
Apesar das vantagens, este método de replicação apresenta alguns desafios.
- Latência: Há um pequeno atraso entre o momento em que os dados são escritos no Master e quando aparecem no Slave, o que pode ser um problema para aplicações que exigem consistência imediata.
- Gestão de falhas: A promoção de um Slave a Master em caso de falha do Master requer intervenção manual ou a configuração de uma solução automatizada.
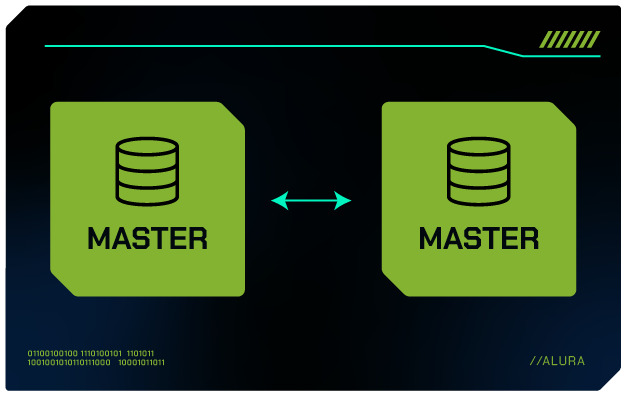
Replicação Master-Master
A replicação Master-Master é uma abordagem mais complexa e poderosa que a replicação Master-Slave, permitindo que dois ou mais servidores atuem simultaneamente como Master.
Cada Master pode processar operações de leitura e escrita, replicando as mudanças para os outros Masters.
Esse tipo de replicação é particularmente útil em cenários que exigem alta disponibilidade e onde as operações de escrita são distribuídas entre vários servidores.
Vantagens
Vamos para as vantagens que este método proporciona:
- Alta Disponibilidade e Redundância: Com ambos os servidores atuando como Master, qualquer um pode assumir imediatamente em caso de falha do outro, garantindo a continuidade do serviço.
- Balanceamento de Carga: Operações de escrita e leitura podem ser distribuídas entre os Masters, melhorando o desempenho e a eficiência.
- Flexibilidade Operacional: Facilita operações de manutenção, atualizações e backups, pois cada Master pode ser atualizado ou mantido sem causar downtime significativo.
Desafios
- Conflitos de Dados: Como ambos os servidores podem executar operações de escrita, existe o risco de conflitos de dados. Estratégias de resolução de conflitos e práticas de design de esquema cuidadosas são essenciais.
- Complexidade de Configuração: A configuração e manutenção de uma replicação Master-Master são mais complexas, exigindo monitoramento e ajustes constantes.
- Latência e Sincronização: A sincronização constante entre os Masters pode introduzir latência, especialmente em ambientes de alta transação.
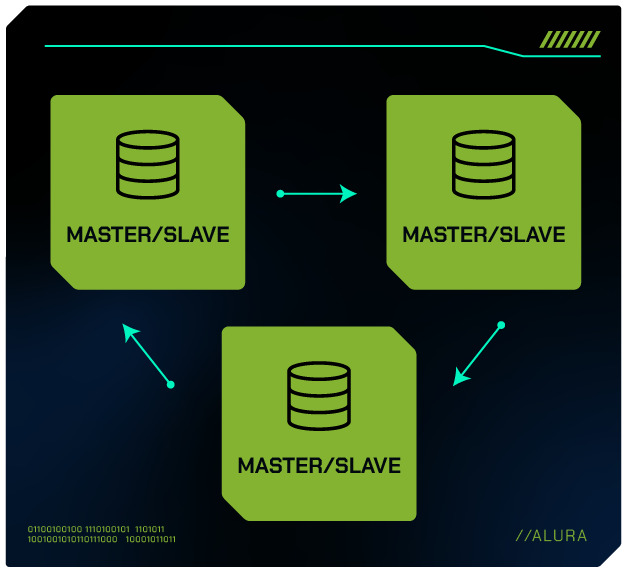
Replicação Circular
A replicação circular é uma variação avançada da replicação de banco de dados, onde vários servidores são configurados em um loop (círculo) de replicação.
Nesse arranjo, cada servidor atua como Master e Slave simultaneamente, recebendo e enviando dados ao próximo servidor na cadeia.
Esse modelo combina aspectos da replicação Master-Master e pode ser usado para melhorar a disponibilidade, a redundância e a distribuição de carga em ambientes complexos.
Vantagens
- Alta Disponibilidade e Redundância: Com múltiplos Masters e Slaves, a replicação circular oferece alta disponibilidade. Qualquer servidor no círculo pode assumir em caso de falha de outro.
- Distribuição de Carga: Permite distribuir a carga de leitura e escrita de maneira eficiente entre vários servidores, melhorando o desempenho geral do sistema.
- Flexibilidade Geográfica: Facilita a replicação de dados entre diferentes regiões geográficas, reduzindo a latência para usuários finais.
Desafios
- Complexidade de Configuração e Manutenção: A replicação circular é complexa de configurar e manter, exigindo monitoramento constante e ajuste fino.
- Conflitos de Dados: Como na replicação Master-Master, a replicação circular pode enfrentar problemas de conflitos de dados. Estratégias de resolução de conflitos são essenciais.
A latência pode ser introduzida devido à necessidade de cada servidor esperar pela atualização do próximo no círculo, especialmente em cenários de alta transação.
Benefícios da Replicação no MySQL
Já mencionamos que os benefícios da replicação são a alta disponibilidade, a escalabilidade, e recuperação dos dados. Mas vamos detalhar melhor essas vantagens?
Alta Disponibilidade
A alta disponibilidade é um dos principais benefícios da replicação de banco de dados no MySQL.
Em um mundo onde o acesso ininterrupto aos dados é crucial para o sucesso das operações empresariais, a replicação desempenha um papel fundamental em garantir que os sistemas permaneçam disponíveis mesmo diante de falhas ou manutenção programada.
A seguir, detalhamos como a replicação contribui para a alta disponibilidade:
Redundância de Dados
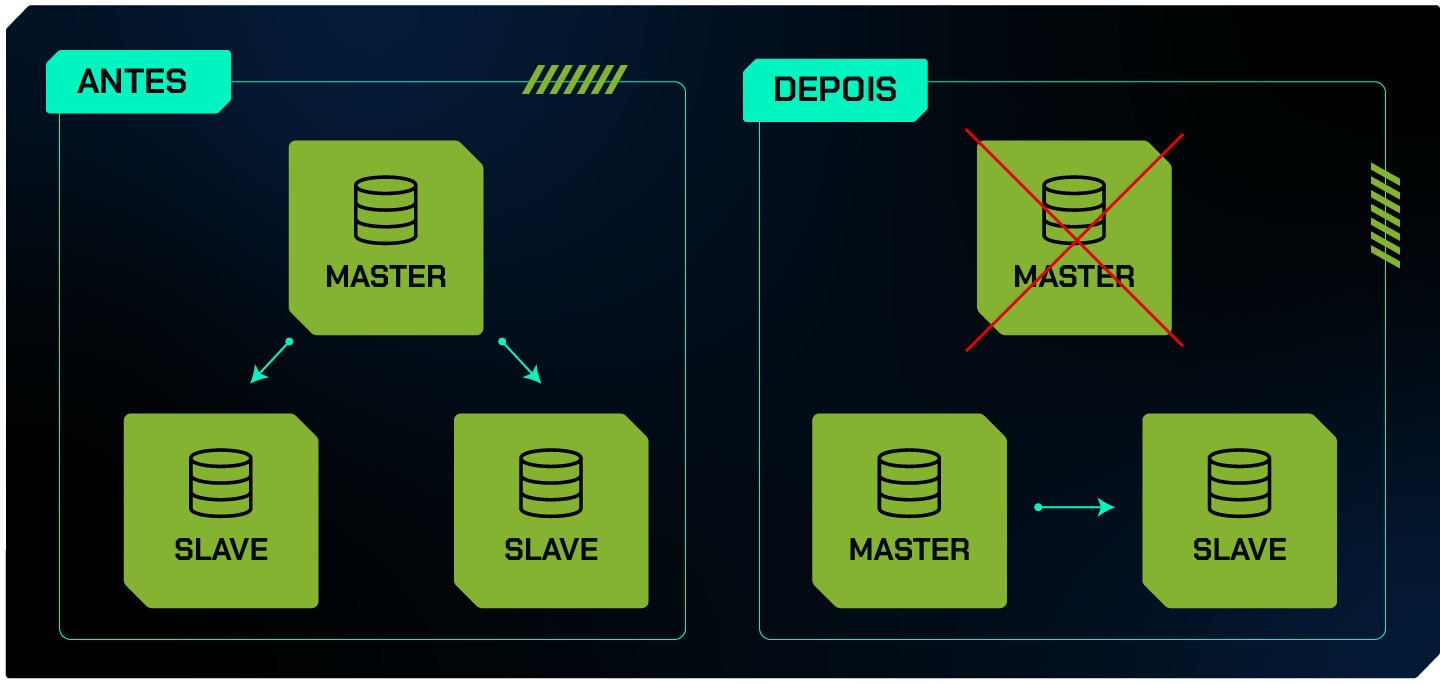
A replicação cria múltiplas cópias dos dados em diferentes servidores. Isso significa que, se o servidor principal (Master) falhar, um ou mais servidores secundários (Slaves) já possuem cópias atualizadas dos dados e podem assumir imediatamente, garantindo que o serviço continue sem interrupção significativa.
Failover Automático:
Em uma configuração avançada, a replicação de banco de dados pode ser combinada com mecanismos de failover automático. Isso permite que, no caso de uma falha do servidor Master, um dos servidores Slaves seja promovido automaticamente a Master, minimizando o tempo de inatividade e mantendo a continuidade das operações.
Manutenção Sem Downtime
A replicação permite que a manutenção de servidores de banco de dados seja realizada sem causar interrupções no serviço.
Enquanto um servidor está em manutenção, os outros servidores replicados continuam a atender as solicitações de dados, garantindo que os usuários finais não sejam afetados.
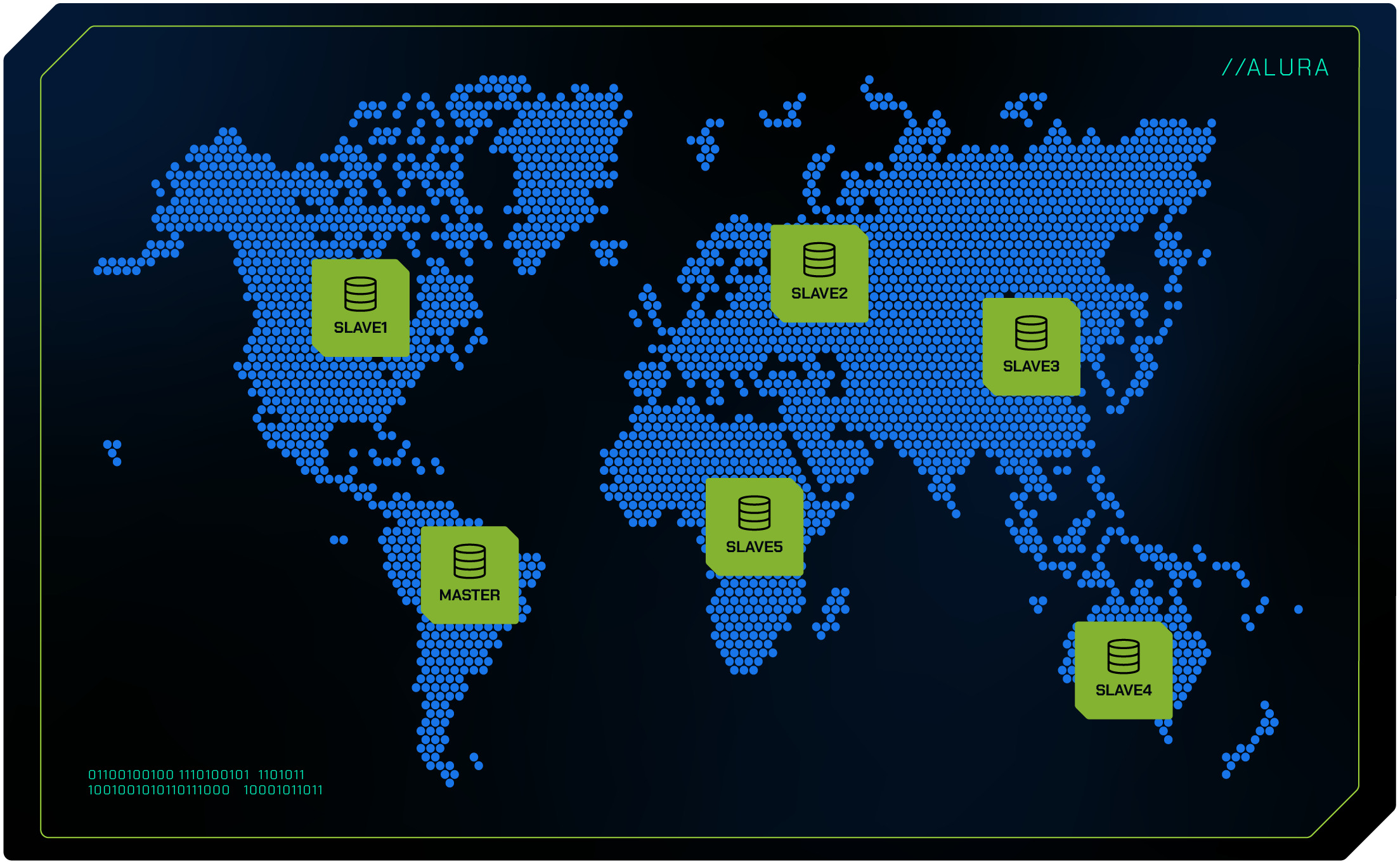
Distribuição Geográfica
Para empresas globais, a replicação de dados pode ser configurada em diferentes regiões geográficas.
Isso não só melhora a latência e a experiência do usuário final ao acessar dados mais próximos geograficamente, mas também oferece uma camada extra de disponibilidade em caso de desastres regionais.
Se uma região enfrentar problemas, outras regiões podem continuar a operar normalmente.
Equilíbrio de Carga
A replicação permite distribuir a carga de trabalho entre múltiplos servidores. Servidores Slaves podem ser usados para operações de leitura, enquanto o servidor Master pode focar nas operações de escrita.
Esse balanceamento melhora a capacidade de resposta do sistema e reduz o risco de sobrecarga em um único servidor.
Recuperação Rápida de Desastres
Em caso de desastres, como falhas de hardware, ataques cibernéticos ou erros humanos, a replicação de banco de dados facilita a recuperação rápida.
Como os dados estão replicados em múltiplos servidores, a recuperação pode ser realizada rapidamente, minimizando a perda de dados e o impacto nas operações.
Melhoria da Resiliência
A replicação aumenta a resiliência do sistema contra falhas imprevistas. Em vez de depender de um único ponto de falha, o sistema tem várias cópias dos dados disponíveis, tornando-o mais robusto e menos suscetível a interrupções.
Escalabilidade
A escalabilidade é uma característica essencial dos sistemas de banco de dados modernos, permitindo que eles cresçam e se adaptem às necessidades crescentes de uma aplicação ou organização.
A replicação no MySQL desempenha um papel crucial na melhoria da escalabilidade, principalmente por meio da distribuição de carga entre servidores.
Aqui, discutiremos como essa técnica pode ser implementada e os benefícios que ela traz.
Distribuição de Carga entre Servidores
A replicação permite que a carga de trabalho seja distribuída eficientemente entre múltiplos servidores, aliviando o servidor principal (Master) e garantindo um desempenho consistente.
Essa distribuição é particularmente importante em ambientes de alta demanda, onde o balanceamento de carga pode evitar gargalos e melhorar a capacidade de resposta do sistema.
Leitura e Escrita Separadas
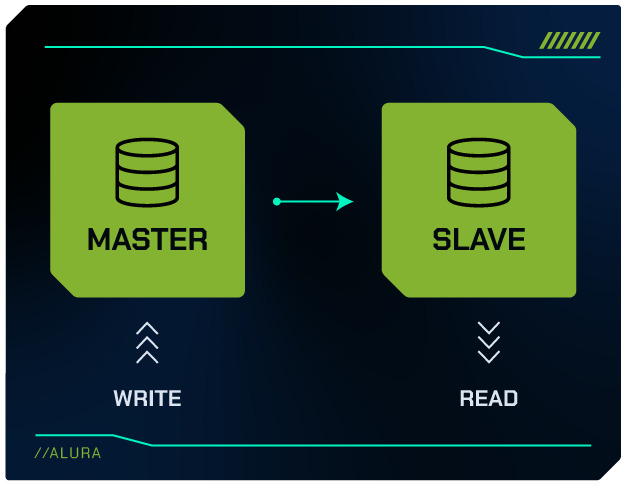
Uma das formas mais comuns de distribuir a carga é separar as operações de leitura e escrita entre diferentes servidores.
No modelo Master-Slave, o servidor Master lida com todas as operações de escrita e replicação de dados para os servidores Slaves, que são utilizados para operações de leitura.
Essa abordagem tem várias vantagens:
- Desempenho Aprimorado: Ao descarregar as operações de leitura para os servidores Slaves, o servidor Master fica menos sobrecarregado, podendo processar operações de escrita de forma mais eficiente.
- Escalabilidade Horizontal: Adicionar mais servidores Slaves para lidar com operações de leitura é uma maneira eficaz de escalar o sistema horizontalmente, permitindo que ele lide com um número crescente de consultas sem sacrificar o desempenho.
- Menor Latência: A replicação de dados em servidores localizados geograficamente próximos aos usuários pode reduzir a latência e melhorar a experiência do usuário final.
Balanceamento de Carga Dinâmico
Ferramentas e proxies de balanceamento de carga, como o MySQL Proxy ou o HAProxy, podem ser utilizados para gerenciar a distribuição de consultas de leitura entre os servidores Slaves de maneira dinâmica.
Esses proxies monitoram o estado dos servidores e direcionam as consultas de acordo com a carga atual, garantindo que nenhum servidor fique sobrecarregado.
Escalabilidade Linear
Em um ambiente de replicação, adicionar novos servidores Slaves pode resultar em um aumento linear na capacidade de leitura do sistema.
Isso significa que, teoricamente, duplicar o número de servidores Slaves pode duplicar a capacidade de leitura, desde que outros recursos (como rede e armazenamento) estejam adequadamente provisionados.
Capacidade de Crescimento
A escalabilidade proporcionada pela replicação não apenas melhora o desempenho atual, mas também prepara o sistema para o crescimento futuro.
Conforme a aplicação ou a base de usuários cresce, novos servidores podem ser adicionados ao pool de Slaves sem a necessidade de grandes reconfigurações ou interrupções.
Redução de Custos
Embora a escalabilidade vertical (melhorar o hardware de um único servidor) possa ser limitada e cara, a escalabilidade horizontal (adicionar mais servidores) é muitas vezes mais econômica e flexível.
A replicação no MySQL facilita essa escalabilidade horizontal, permitindo que as organizações cresçam de maneira eficiente e controlada.
Backup e Recuperação
A replicação de banco de dados no MySQL não apenas melhora a disponibilidade e escalabilidade, mas também simplifica significativamente os processos de backup e recuperação.
Manter backups consistentes e ter a capacidade de recuperar dados rapidamente são componentes críticos para a continuidade dos negócios e a integridade dos dados. Vamos ver como a replicação contribui para esses processos essenciais.
Backups Sem Impacto no Desempenho
Realizar backups completos de um banco de dados pode ser uma tarefa intensiva, especialmente em sistemas com grandes volumes de dados ou alta taxa de transações.
A replicação permite que os backups sejam realizados a partir dos servidores Slaves, em vez do servidor Master, minimizando o impacto no desempenho do sistema principal.
Isso significa que operações de backup podem ser agendadas durante horários de pico sem afetar negativamente a experiência do usuário ou a performance da aplicação.
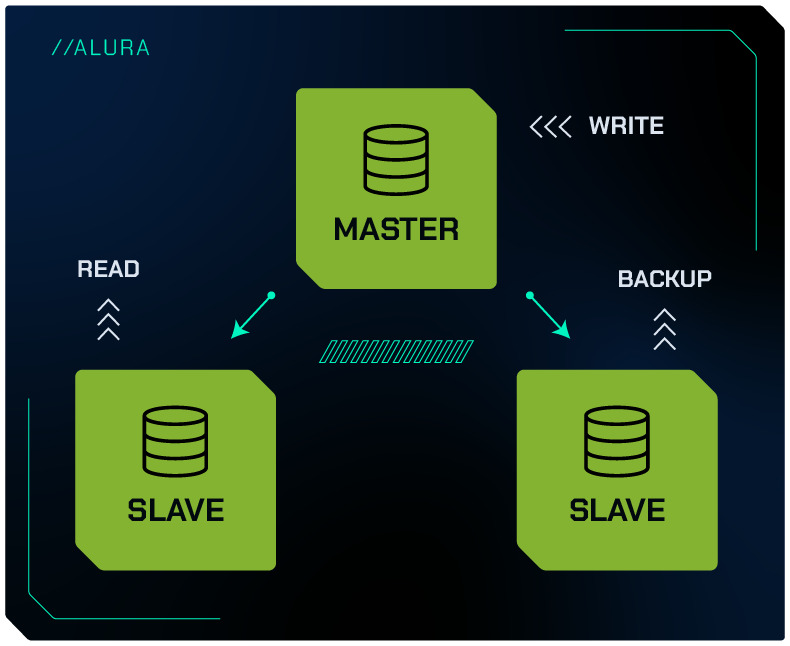
Consistência de Dados
A replicação garante que os servidores Slaves mantenham cópias atualizadas e consistentes dos dados do Master.
Isso é crucial para a integridade dos backups. Quando um backup é realizado a partir de um Slave, ele reflete um estado consistente do banco de dados, alinhado com o servidor Master, garantindo que os dados estejam completos e precisos.
Recuperação Rápida
Em caso de perda de dados ou corrupção no servidor Master, os servidores Slaves podem ser promovidos rapidamente a Master, reduzindo drasticamente o tempo de recuperação.
Esse failover rápido é possível porque os Slaves contêm cópias atualizadas dos dados, permitindo uma transição suave sem necessidade de restaurações complexas.
Redundância Geográfica
A replicação permite que cópias de backup sejam mantidas em diferentes locais geográficos.
Isso é particularmente útil para recuperação de desastres, garantindo que, mesmo em caso de falhas catastróficas em uma região (como incêndios, inundações ou ataques cibernéticos), os dados ainda estejam disponíveis em outros locais.
Essa redundância geográfica é um componente vital de uma estratégia robusta de recuperação de desastres.
Automatização de Backups
A configuração de replicação pode ser complementada com scripts e ferramentas que automatizam o processo de backup dos servidores Slaves.
Ferramentas como mysqldump, MySQL Enterprise Backup, ou soluções de terceiros podem ser integradas para criar backups regulares e consistentes, reduzindo a necessidade de intervenção manual e garantindo que os backups sejam realizados de forma periódica e confiável.
Verificação de Integridade dos Backups
A replicação também facilita a verificação regular dos backups. Com dados replicados em múltiplos servidores, é possível realizar verificações de integridade e consistência de maneira mais frequente e sem afetar o desempenho do servidor principal.
Isso assegura que os backups são válidos e podem ser usados em situações de emergência.
Capacidade de Recuperação Granular
Além de backups completos, a replicação permite a criação de backups incrementais ou diferenciais a partir dos servidores Slaves.
Isso oferece a capacidade de recuperação granular, onde apenas as mudanças ocorridas desde o último backup completo precisam ser restauradas, acelerando o processo de recuperação e minimizando a perda de dados.
Como configurar a Replicação no MySQL
Aqui está um passo a passo para configurar a replicação no MySQL:
Preparativos Iniciais
Para configurar a replicação no MySQL de maneira eficaz, é essencial preparar o ambiente adequadamente, atendendo a todos os requisitos do sistema.
Isso garante uma replicação suave e eficiente, minimizando problemas potenciais durante a operação.
Abaixo estão os principais requisitos e considerações para preparar o sistema para a replicação.
Requisitos do sistema
Para configurar a replicação no MySQL, é crucial garantir que todos os servidores, tanto Master quanto Slaves, estejam executando versões compatíveis do MySQL, preferencialmente a mesma versão, para evitar problemas de compatibilidade.
Os servidores devem estar conectados em uma rede confiável e rápida, utilizando endereços IP estáticos ou nomes de host fixos para assegurar uma comunicação estável e contínua.
É importante sincronizar os relógios dos servidores usando NTP para evitar problemas de consistência de dados.
Os servidores devem ter recursos de hardware adequados, incluindo CPU, memória e armazenamento, preferencialmente SSDs, para lidar com a carga adicional imposta pela replicação.
Implementar medidas de segurança como firewalls, regras de acesso e utilizar conexões seguras (SSL/TLS) é essencial para proteger os dados replicados durante a transferência.
Antes de configurar a replicação, é recomendável realizar backups completos dos dados existentes e testar a configuração em um ambiente de staging para validar a replicação.
Habilitar logs binários no Master é necessário, pois eles registram todas as alterações no banco de dados e são essenciais para a replicação.
Cada servidor deve ter um identificador único (server-id) para que o MySQL possa distingui-los corretamente na configuração de replicação.
Também é importante garantir que haja espaço em disco suficiente para armazenar os logs binários no Master e os logs de relay nos Slaves, especialmente em ambientes de alta transação onde esses logs podem crescer rapidamente.
Por fim, é necessário criar um usuário de replicação no Master com permissões adequadas para que os Slaves possam se conectar e replicar dados de maneira segura e eficiente.
Como configurar o Master
Configurar o servidor Master corretamente é um passo crucial para implementar a replicação no MySQL.
A seguir você confere um guia com todos os passos para configurar o servidor Master, incluindo os ajustes necessários no arquivo de configuração my.cnf.
Passos para configurar o Master
Para configurar o servidor Master para replicação no MySQL, siga os passos a seguir.
Primeiro, certifique-se de que o MySQL está instalado no servidor Master. Caso contrário, utilize o gerenciador de pacotes apropriado para realizar a instalação.
Em seguida, ajuste o arquivo de configuração my.cnf para habilitar a replicação. Isso envolve abrir o arquivo com um editor de texto e adicionar ou modificar configurações específicas, como server-id para um identificador único, log_bin para especificar o caminho do log binário, e binlog_format como ROW para garantir a consistência.
Se necessário, pode-se também especificar um banco de dados específico para replicação usando binlog_do_db.
Depois, crie um usuário dedicado para a replicação, que permitirá que os servidores Slaves se conectem ao Master.
Com as configurações ajustadas, reinicie o servidor MySQL para aplicar as mudanças.
Para configurar os Slaves, será necessário obter a posição atual do log binário do Master.
Isso pode ser feito utilizando o comando SHOW MASTER STATUS, que fornecerá o nome do arquivo de log e a posição atual. Anote essas informações para uso posterior.
Em seguida, faça um dump inicial do banco de dados para garantir que os Slaves comecem com uma cópia consistente dos dados do Master.
Utilize o comando mysqldump para criar o dump e transfira este arquivo para os servidores Slaves para inicialização.
Como configurar o Slave
Após configurar o servidor Master, o próximo passo é configurar os servidores Slaves para que eles possam se conectar ao Master e começar a replicar os dados.
Abaixo estão os passos detalhados para configurar o servidor Slave e realizar a sincronização inicial de dados.
Passos para configurar o Slave
Para configurar o servidor Slave para replicação no MySQL, siga os passos a seguir.
Primeiro, certifique-se de que o MySQL está instalado no servidor que será configurado como Slave. Se não estiver instalado, utilize o gerenciador de pacotes apropriado para realizar a instalação.
Em seguida, ajuste o arquivo de configuração my.cnf para habilitar a replicação. Isso envolve abrir o arquivo com um editor de texto e adicionar ou modificar configurações específicas, como server-id para um identificador único, relay_log para especificar o caminho do log de relay, e log_bin para habilitar o log binário no Slave, caso necessário.
Opcionalmente, pode-se especificar um banco de dados específico para replicação usando binlog_do_db, e a configuração read_only garante que o Slave seja somente leitura, prevenindo alterações diretas.
Depois de ajustar as configurações no my.cnf, reinicie o servidor MySQL para aplicar as mudanças.
Sincronização inicial de dados
Para garantir que o servidor Slave comece com uma cópia consistente dos dados do Master, é necessário sincronizar os dados inicialmente, o que envolve carregar um dump do banco de dados do Master no Slave.
Primeiro, transfira o arquivo de dump (masterdump.sql) criado no Master para o servidor Slave.
Use um comando seguro para copiar o arquivo, garantindo que ele seja transferido corretamente.
Depois de transferir o arquivo, carregue o dump no MySQL do servidor Slave para importar todos os dados necessários.
Em seguida, configure a conexão do Slave com o Master utilizando as informações do log binário obtidas anteriormente (File e Position).
No prompt MySQL do Slave, configure a replicação com os detalhes corretos do Master.
Após a configuração, inicie o processo de replicação no Slave para começar a replicar os dados do Master.
É importante verificar o status da replicação para garantir que está funcionando corretamente.
Execute o comando de status no MySQL do Slave e verifique os campos Slave_IO_Running e Slave_SQL_Running, que devem estar ambos como Yes. Certifique-se de que não há erros nos campos Last_IO_Error e Last_SQL_Error.
Por fim, mantenha o monitoramento contínuo do status da replicação para garantir que os Slaves estejam sempre atualizados e sincronizados com o Master.
Ferramentas como MySQL Enterprise Monitor ou outras ferramentas de monitoramento podem ajudar a automatizar esse processo e fornecer alertas em tempo real sobre o status da replicação.
Como gerenciar e monitorar a Replicação
Manter uma replicação saudável e eficiente no MySQL requer monitoramento contínuo e ferramentas eficazes para identificar e resolver problemas rapidamente.
Vamos explorar algumas das principais ferramentas de monitoramento disponíveis, incluindo o MySQL Enterprise Monitor e outras opções populares.
O MySQL Enterprise Monitor é uma ferramenta robusta oferecida pela Oracle, projetada especificamente para monitorar e gerenciar instâncias do MySQL.
Ele fornece o monitoramento em tempo real, que oferece uma visão imediata do estado dos servidores MySQL, incluindo detalhes específicos sobre a replicação.
Isso permite visualizar a performance do Master e dos Slaves, verificando métricas como latência de replicação, status de threads de replicação e taxa de transferência de dados.
Configurar alertas personalizados é essencial para detectar problemas como atrasos na replicação, falhas de conexão e erros de replicação, garantindo que os administradores sejam informados rapidamente sobre qualquer problema através de notificações por e-mail ou outros meios.
As ferramentas de análise de desempenho são fundamentais para identificar gargalos e otimizar a replicação.
Elas fornecem visualizações gráficas detalhadas do histórico de desempenho, facilitando a análise de tendências e a identificação de padrões problemáticos.
Além disso, a geração de relatórios detalhados sobre a saúde da replicação, uso de recursos e conformidade com políticas de segurança é crucial.
A auditoria completa das atividades de replicação ajuda na resolução de problemas e na manutenção da integridade dos dados.
Existem outras ferramentas pagas e open-source como o Percona Monitoring and Management (PMM), Zabbix, Nagios, Prometheus e Datadog.
Boas Práticas de Replicação
Para garantir que a replicação do MySQL opere de forma eficiente e confiável, é crucial adotar boas práticas de manutenção e atualização.
E como podemos manter o sistema atualizado com estratégias eficazes de manutenção preventiva?
Manutenção e Atualizações
Para manter o sistema MySQL atualizado, é essencial verificar regularmente a disponibilidade de novas versões, que frequentemente incluem correções de bugs, melhorias de desempenho e novas funcionalidades.
Antes de aplicar atualizações no ambiente de produção, teste-as em um ambiente de staging para evitar problemas de compatibilidade e garantir que a replicação não seja interrompida.
Planeje as atualizações para períodos de baixa atividade e notifique os usuários sobre possíveis interrupções.
Além disso, mantenha o sistema operacional compatível e atualizado com patches de segurança e monitore o desempenho do hardware, atualizando componentes como CPU, memória e armazenamento conforme necessário.
Estratégias de manutenção preventiva incluem monitoramento contínuo com ferramentas como MySQL Enterprise Monitor, PMM, Zabbix ou Nagios, e revisão regular de logs de erro e replicação para resolver problemas antes que afetem o sistema.
Realize backups regulares dos dados no Master e nos Slaves, utilize backups incrementais para minimizar o impacto no desempenho e teste regularmente a recuperação dos backups para garantir a integridade dos dados.
Verifique e corrija inconsistências de dados entre o Master e os Slaves usando ferramentas como pt-table-checksum e pt-table-sync, e programe auditorias regulares para garantir a consistência dos dados replicados.
Estabeleça janelas de manutenção regulares para realizar atualizações, aplicar patches de segurança e executar tarefas de otimização.
Tenha procedimentos documentados para promover um Slave a Master em caso de falha do Master, garantindo a continuidade do serviço. Além disso, revise e otimize regularmente os índices e as consultas SQL para melhorar o desempenho, ajustando as configurações do MySQL conforme necessário.
Por exemplo, realize verificações semanais de logs para identificar problemas emergentes, usando scripts automatizados para enviar resumos de logs por e-mail. Realize backups incrementais diários e um backup completo semanal, testando a restauração dos backups mensalmente.
Utilize pt-table-checksum trimestralmente para verificar a consistência dos dados entre o Master e os Slaves e corrigir quaisquer discrepâncias com pt-table-sync.
Segurança
Garantir a segurança dos dados replicados é essencial para proteger informações sensíveis e manter a integridade do banco de dados.
A seguir, você verá como proteger os dados replicados e as configurações de segurança no MySQL que podem ser implementadas para fortalecer a segurança do sistema.
Proteção dos Dados Replicados
Para proteger os dados replicados no MySQL, é essencial adotar medidas de segurança robustas.
Primeiramente, configure o MySQL para usar SSL/TLS para criptografar o tráfego entre o Master e os Slaves, impedindo que os dados sejam interceptados durante a transmissão. Isso envolve gerar certificados SSL para o Master e os Slaves, modificar o arquivo my.cnf para habilitar SSL, e configurar a replicação no Slave para usar SSL.
Além disso, restrinja o acesso aos servidores MySQL utilizando firewalls para permitir conexões apenas de endereços IP específicos que precisam se comunicar entre si.
Configure listas de controle de acesso (ACLs) para garantir que apenas usuários autorizados possam acessar e modificar os dados replicados.
Crie usuários dedicados para a replicação com permissões mínimas necessárias, evitando o uso de usuários com permissões de administrador.
Isso garante que os usuários de replicação tenham apenas os privilégios necessários para a replicação, aumentando a segurança.
Para monitoramento e auditoria, ative e revise regularmente os logs de auditoria para monitorar atividades suspeitas ou não autorizadas.
Utilize ferramentas de monitoramento para detectar e alertar sobre atividades anômalas na replicação, garantindo que qualquer problema seja identificado e resolvido rapidamente.
Configurações de Segurança no MySQL
Para garantir a segurança no MySQL, utilize métodos de autenticação fortes, como caching_sha2_password, em vez de métodos mais fracos.
Nas configurações de conexão segura, ajuste o arquivo de configuração do MySQL para desabilitar conexões remotas para o usuário root e habilitar o uso de senhas seguras.
Para proteger contra ataques de força bruta, configure o MySQL para limitar o número de tentativas de login falhas e considere usar ferramentas adicionais como Fail2ban para bloquear endereços IP após múltiplas tentativas de login falhas.
Mantenha o MySQL atualizado com os últimos patches de segurança para proteger contra vulnerabilidades conhecidas.
Monitore as notificações de segurança do MySQL e aplique patches imediatamente quando vulnerabilidades críticas forem anunciadas.
Por fim, sempre criptografe os backups de dados para proteger informações sensíveis em caso de acesso não autorizado e armazene os backups em locais seguros, preferencialmente com acesso restrito e auditado.
Conclusão
A replicação de banco de dados no MySQL é uma técnica poderosa para garantir a alta disponibilidade, escalabilidade e segurança dos dados.
Com a configuração correta e as práticas de gerenciamento adequadas, um MySQL Administrator pode assegurar que o sistema de banco de dados atenda às demandas modernas do ambiente de TI.
Esperamos que este artigo tenha fornecido uma visão abrangente sobre o tema, ajudando você a implementar e otimizar a replicação em suas operações.
