
Autores: Ana Clara de Andrade Mioto, João Vitor de Miranda e Sthefanie Monica Premebida
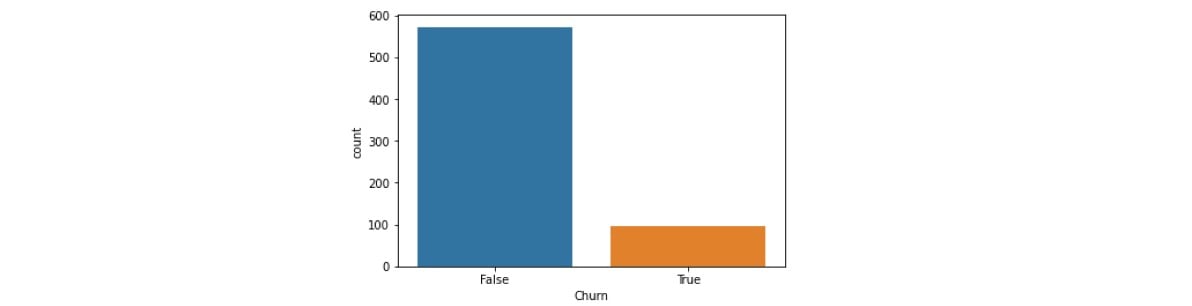
Em problemas de modelagem supervisionada focada em classificação, podemos nos deparar com bases de dados em que a variável alvo contenha classes muito desbalanceadas, isto é, contendo categorias com frequências muito diferentes.
Ao treinar um modelo de classificação com a variável desbalanceada, encontraremos alguns problemas. Isso acontece porque o padrão dos dados para a classe dominante vai se sobressair em relação aos da classe com menor frequência. Geralmente, nas bases de dados que possuem a variável alvo desbalanceada, a classe com menor frequência é justamente a que temos interesse em prever, o que torna os problemas ainda maiores.
Como uma das classes tem frequência muito grande, o modelo construído utilizando dados desbalanceados pode apresentar acurácia bem elevada e ainda assim não prever corretamente nenhuma observação para a classe com menor frequência. Isso pode deixar a falsa impressão de que o modelo está com boa performance quando na verdade não está.
Para contornar esses problemas gerados pela base de dados desbalanceada, podemos recorrer a duas soluções que consistem em equilibrar os dados da variável alvo: undersampling e oversampling.
Undersampling
É uma técnica que consiste em manter todos os dados da classe com menor frequência e diminuir a quantidade dos que estão na classe de maior frequência, fazendo com que as observações no conjunto possuam dados com a variável alvo equilibrada.
Pode ser uma vantagem utilizar o undersampling para reduzir o armazenamento dos dados e o tempo de execução de códigos, uma vez que a quantidade de dados será bem menor. Uma das técnicas mais utilizadas é o Near Miss que diminui aleatoriamente a quantidade de valores da classe majoritária.
Algo muito interessante do Near Miss é que ele utiliza a menor distância média dos K-vizinhos mais próximos, ou seja, seleciona os valores baseando-se no método KNN (K-nearest neighbors) para reduzir a perda de informação.
Caso queira saber mais sobre como funciona a técnica Near Miss, você pode checar o artigo KNN approach to unbalanced data distributions: a case study involving information extraction.

Oversampling
É uma técnica que consiste em aumentar a quantidade de registros da classe com menor frequência até que a base de dados possua uma quantidade equilibrada entre as classes da variável alvo. Para aumentar a quantidade de registros, podemos duplicar aleatoriamente os registros da classe com menor frequência. Porém, isso fará com que muitas informações fiquem idênticas, o que pode impactar no modelo.
Uma vantagem dessa técnica é que nenhuma informação dos registros que possuíam a classe com maior frequência é perdida. Isso faz com que o conjunto de dados possua muitos registros para alimentar os algoritmos de machine learning. Por sua vez, o armazenamento e o tempo de processamento crescem bastante e há a possibilidade de ocorrer um sobreajuste nos dados que foram duplicados. Este sobreajuste acontece quando o modelo se torna muito bom em prever os resultados para os dados de treinamento, mas não generaliza bem para novos dados.
Para evitar que existam muitos dados idênticos, pode ser utilizada a técnica SMOTE, que consiste em sintetizar novas informações com base nas já existentes. Esses dados “sintéticos” são relativamente próximos aos dados reais, mas não são idênticos. Para saber mais como funciona a técnica SMOTE, você pode ler o artigo SMOTE: Synthetic Minority Over-sampling Technique.
Como aplicá-las?
Ambas as técnicas de balanceamento podem ser aplicadas utilizando a biblioteca imbalanced-learn que é baseada na sklearn e fornece ferramentas para lidar com dados desbalanceados.
Na documentação, você pode encontrar vários exemplos de como aplicar oversampling e undersampling, inclusive fora dos exemplos trazidos anteriormente. Vale lembrar que ambas possuem vantagens e desvantagens e a aplicação de cada uma delas dependerá das particularidades do problema.
