

Um problema comum quando estamos desenvolvendo uma aplicação é ficar empolgado(a) quando ela está funcionando bem no nosso ambiente. Mas, quando a utilizamos em outro computador ou subimos para produção, a aplicação não executa da forma como queríamos. Se estava funcionando perfeitamente, não deveria acontecer o mesmo em outros ambientes?

Quando isso acontece, as pessoas costumam falar “Na minha máquina roda”. Devido a esse problema de ambiente, surgiu a necessidade de criar os containers (ou contêineres, em português). Mesmo assim, quando temos algum problema complexo, um único container pode não ser suficiente, havendo a necessidade de utilizar dois ou mais. Para isso, precisamos saber gerenciar todos eles.
Existem algumas ferramentas que conseguem lidar com essas situações, sendo interessante que a integração entre elas seja da melhor forma possível. No mercado, temos o:
- Docker como uma das melhores ferramentas para criar containers; e
- Kubernetes também muito utilizado na orquestração que é processo de automação de grande parte do esforço para executar os serviços e fluxos de trabalho organizados em containers.
Vamos conhecer mais sobre eles?
O que é Docker?
Docker é uma plataforma de código aberto criada em 2013 e que pode armazenar, construir, distribuir e rodar containers, sendo uma das plataformas mais utilizadas para se trabalhar com containers, tanto em desktop quanto em cloud.
Com o Docker é possível encapsular todas as dependências que um container precisa para funcionar como código da aplicação, o runtime e as bibliotecas necessárias. Isso tudo unificado em um container que podemos versionar e facilmente distribuir.
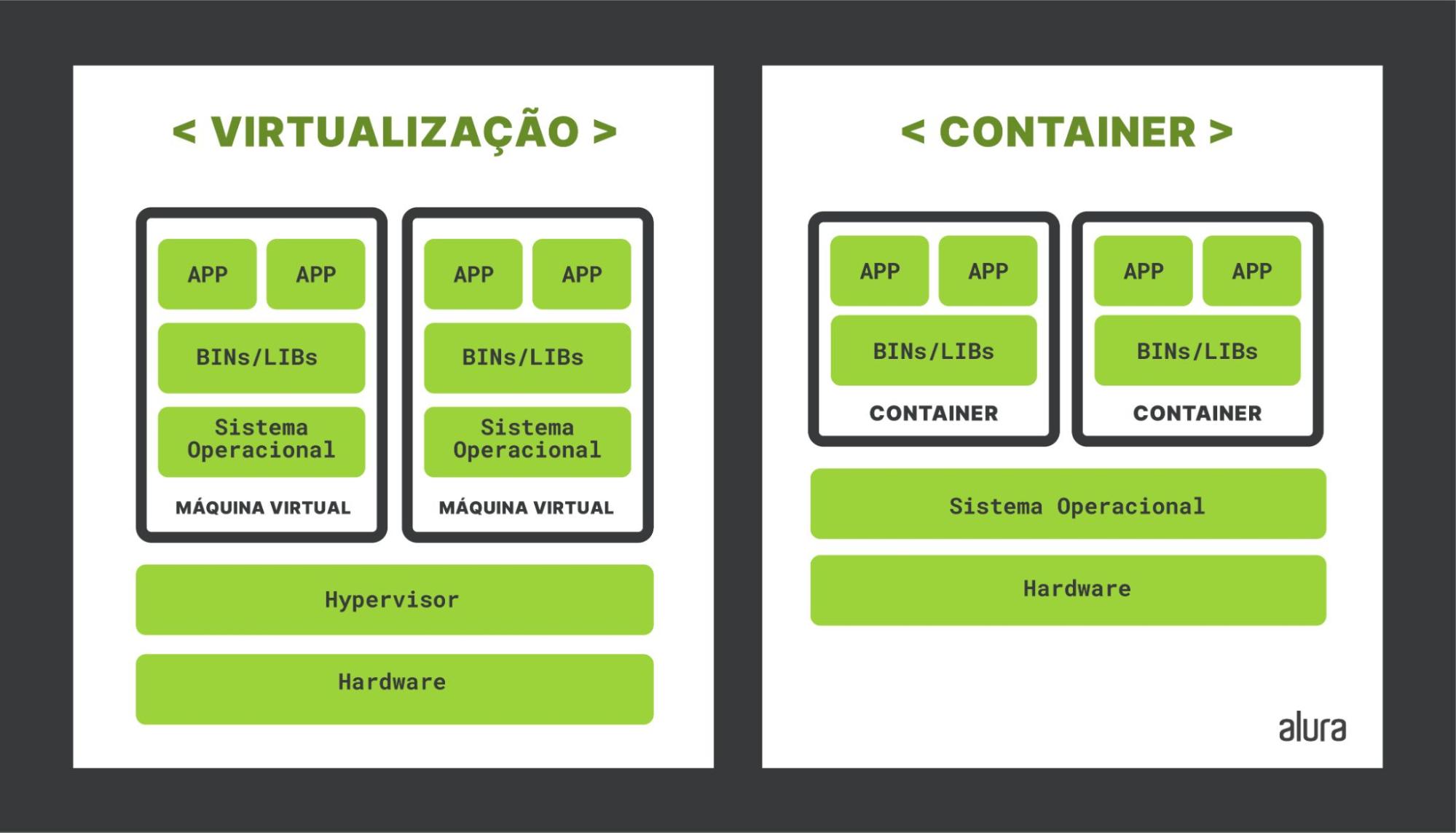
O container é um sistema de virtualização não convencional. E o que isso significa? Em virtualizações convencionais, como a criação de uma máquina virtual completa, temos um software que é instalado na máquina de origem (por exemplo, o seu computador) que irá fazer o gerenciamento dessas máquinas.
Isso não acontece na virtualização utilizando container, pois ele não virtualiza todo o ambiente. Ele cria uma virtualização a nível do sistema e não de toda máquina, deixando somente o necessário para a aplicação. Portanto, oferece algumas vantagens como ser bem mais leve e consumir menos recursos que uma virtualização convencional.

Entendendo Kubernetes
Kubernetes, em grego, significa timoneiro ou piloto de navio. Logo, faz jus ao nome e é perfeito para navegar com nossos containers para qualquer ambiente que precisarmos. Porém, construir um conjunto de containers pode não ser uma tarefa fácil se não tivermos a ferramenta adequada.
Quando necessitamos ter o controle de um conjunto de containers, utilizamos orquestradores. O Kubernetes é um orquestrador de containers que facilita bastante nessas tarefas, pois ele consegue gerenciar um cluster com várias máquinas e, por conta da sua arquitetura, se torna uma ferramenta muito interessante.
O Kubernetes gerencia um cluster basicamente dividido por: um master que gerencia o cluster e mantém tudo no estado desejado; e os nodes(ou nós), que costumamos chamar de workers (ou trabalhadores), que são responsáveis pela execução da aplicação.
Dentro do master podemos destacar alguns componentes, como:
- API: responsável por receber e executar comandos;
- Scheduler: responsável por definir o local onde os Pod s, que representam uma cápsula de containers, serão executados no cluster; e
- Controller Manager: mantém o estado do cluster conforme desejado.
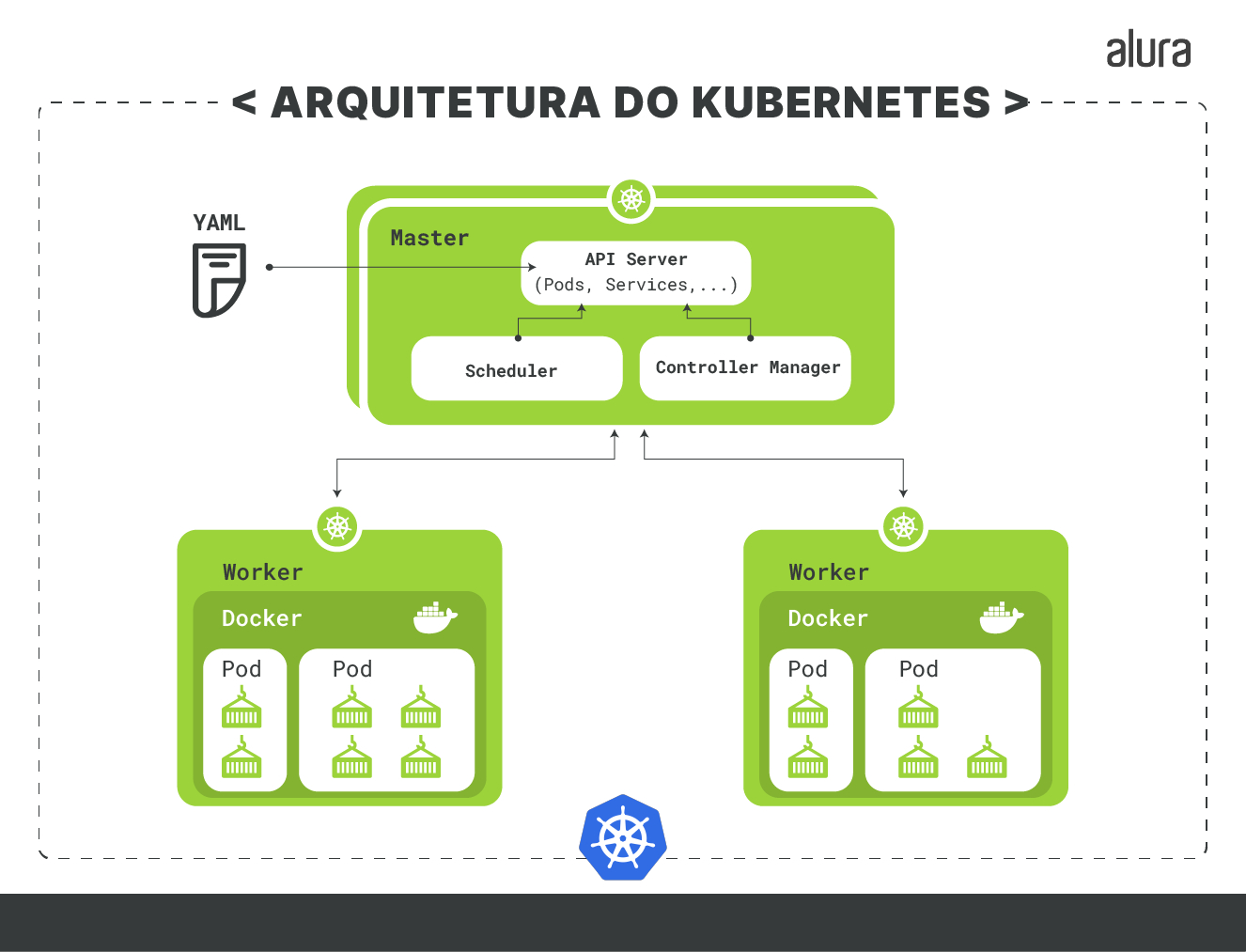
Criamos e fazemos tudo isso utilizando uma ferramenta do Kubernetes chamada kubectl, que nos permite comunicar com a API do Kubernetes e fazer requisições dentro do nosso cluster. Para que o kubectl possa enviar as definições que queremos e a API do Kubernetes consiga interpretar, utilizamos os arquivos json ou YAML, sendo este o mais comum e simples de se trabalhar e que pode ser estruturado como no exemplo abaixo:
apiVersion: v1
kind: Pod
metadata:
name: pod-1
spec:
containers:
- name: nginx-container
image: nginx:latestNesse exemplo de arquivo, que chamamos de pod.yaml, estamos definindo:
- apiVersion: especificando a versão da API utilizada;
- kind: o que está sendo criado, no nosso exemplo um Pod;
- metadata: definindo o metadados desse pod, no exemplo o nome é
pod-1; - spec: contém as especificações do Pod, como o nome desse container e o tipo de imagem que será carregada.
Você pode conferir no episódio Containers, Docker e Kubernetes do Hipster Ponto Tube, no qual o Paulo Silveira e o Giovanni Bassi conversam sobre esse assunto.

É claro que para gerenciar esses containers precisamos definir uma certa organização. Ao lidar com vários containers ao mesmo tempo, surge a necessidade de criar um ambiente onde podemos organizá-los e para isso utilizamos os Pods.
Entendendo Pods
O Pod é responsável pelo encapsulamento de containers. Ele é uma abstração do Kubernetes que representa um grupo ou mais de containers, como o Docker. Quando o Pod contém mais de um container, podemos compartilhar, desde armazenamento, redes e de ambiente dentro do mesmo Pod, facilitando a comunicação entre eles.
Por serem muito úteis para que a aplicação seja escalável, podemos utilizar o controlador de replicação do Kubernetes para garantir a escalabilidade horizontal de nossa aplicação, conforme seja necessário. Isso significa que o Kubernetes pode replicar um Pod sobrecarregado para manter o funcionamento da aplicação, sendo uma grande utilidade para criar um sistema resistente e mais robusto.
Possuir um controlador de replicação do Kubernetes é uma grande vantagem. Além de ser usada para escalabilidade, o controlador consegue dimensionar automaticamente a quantidade de Pods, ou seja, se estamos com mais do que precisamos, o controlador irá reduzir a quantidade de Pods desnecessários ou até mesmo substituir os Pods, caso falhem. Dessa forma, funcionam como um supervisor para não desperdiçar recursos.
O que é o Minikube?
Podemos fazer ambientes complexos com Kubernetes e criar uma aplicação bem robusta capaz de dar conta de muitos problemas. Mas não é sempre que precisamos de tudo isso. Se temos a necessidade de um ambiente para teste, por exemplo, precisamos criar uma arquitetura complexa?
Para esses casos, costumamos utilizar o Minikube, uma implementação mais leve e simples do Kubernetes que contém apenas um nó. Essa versão já é capaz de oferecer operações básicas para trabalhar com um cluster, sendo super eficiente quando se trata de ambientes de testes e desenvolvimento.
Volumes persistentes
Costumamos dizer que o armazenamento de dados dentro de um container é efêmero. Isso significa que, após excluir o container, perdemos os dados que estão dentro dele. Conseguimos resolver isso quando temos um cluster no Kubernetes e podemos utilizar o Persistent Volume (PV) também chamado de volumes persistentes. Mas você pode se perguntar: qual é a vantagem disso?
Um Persistent Volume consegue garantir que os dados fiquem intactos, caso os containers que estão conectados a ele sejam excluídos ou encerrados. Quando é necessário ter um armazenamento persistente, podemos criar um Persistent Volume Claim (PVC), ou uma reivindicação de um volume persistente, gerando um volume dentro do Pod.
Assim, dentro do Kubernetes temos o Persistent Volume (que representa tipo de volume) que, por sua vez, tem duas componentes: uma também chamada Persistent Volume e a outra Persistent Volume Claim.
Kubernetes na Engenharia de Dados
Sabemos que o Kubernetes é um ótimo serviço de gerenciamento de containers. Por isso, essa ferramenta se torna útil em diferentes aplicações. Na Engenharia de Dados, área que trabalha com problemas complexos em que muitas das vezes precisamos ter uma alta escalabilidade e gerenciamento, o Kubernetes se torna uma excelente opção.
Na Engenharia de Dados temos o Apache Airflow que é uma ferramenta muito útil para orquestração de fluxos de dados. Podemos utilizar o Airflow de uma maneira bastante manual, mas com o Kubernetes facilitamos muitos dos processos utilizando recursos que diminuem grande parte da carga de trabalho.
Se estamos trabalhando com Apache Airflow, por exemplo, podemos executá-lo dentro de um cluster e utilizar os recursos de escalabilidade que o Kubernetes fornece. Podemos utilizar recursos como:
- Kubernetes Executor: para executar todas as tarefas do Airflow no Kubernetes em Pods separados; e
- KubernetesPodOperator: para criar Pods no Kubernetes.
Por essas razões, ter o Kubernetes como aliado pode evitar grandes dores de cabeça, facilitando a maneira que fazemos o gerenciamento de containers para as nossas aplicações.
Conclusão
Neste artigo conhecemos várias funcionalidades do Kubernetes e como os recursos desse orquestrador podem nos ajudar a cuidar de containers, sendo uma excelente ferramenta em áreas como a Engenharia de Dados quando estamos utilizando Airflow.
Se você tem interesse em aprender mais sobre o Kubernetes e deseja mergulhar mais nesse conteúdo, acesse a formação Orquestração de containers com Kubernetes. E para entender na prática sobre Apache Airflow, você pode conferir o conteúdo no curso Apache Airflow: orquestrando seu primeiro pipeline de dados
Créditos
- Conteúdo: Paulo Calanca
- Produção técnica:
- Produção didática: Morgana Gomes
- Designer gráfico: Alysson Manso
