

Em um mundo onde as informações estão crescendo exponencialmente, a velocidade de resposta de um banco de dados pode ser a diferença entre um negócio de sucesso e uma operação falha.
Imagine uma situação em que, durante um evento de vendas de alto volume, como uma Black Friday, o sistema de uma empresa se torna extremamente lento ou até mesmo indisponível devido ao aumento nas consultas ao banco de dados.
Clientes frustrados não conseguem finalizar suas compras e acabam buscando alternativas na concorrência. O prejuízo financeiro e de reputação pode ser imenso.
Essa realidade não está distante para muitas empresas que trabalham com grandes volumes de dados, e é nesse contexto que entra a importância da otimização das consultas em bancos de dados.
Mais do que apenas uma melhoria técnica, otimizar consultas pode ser a chave para manter um negócio competitivo, garantindo que seus usuários tenham uma experiência satisfatória e que os processos internos fluam de maneira eficiente.
Neste artigo vamos explorar algumas estratégias para otimizar consultas complexas, ajudando você a extrair o máximo de desempenho dos seus sistemas.
Venha conferir e descubra como transformar seus dados em vantagem competitiva!
Índices
Um índice em um banco de dados é muito parecido com o índice de um livro. Quando você procura um tópico específico em um livro, em vez de folhear página por página, vai até o índice, encontra o tópico desejado e, a partir dele, localiza rapidamente a página que contém a informação.
Esse é exatamente o conceito aplicado aos índices em bancos de dados.
Tecnicamente, um índice é uma estrutura que armazena a localização dos dados em uma tabela de forma organizada, permitindo que o banco de dados encontre rapidamente os registros desejados.
No PostgreSQL, um índice atua como uma tabela auxiliar, contendo uma cópia ordenada dos valores da coluna (ou colunas) que está indexando, junto com um ponteiro para o local físico do registro na tabela.

Por que utilizar índices?
Em sistemas de grande porte, o tempo necessário para encontrar um dado específico pode se tornar um gargalo significativo.
Sem um índice, uma consulta que precise localizar uma informação específica pode ter que percorrer toda a tabela — um processo chamado de "varredura completa de tabela" (full table scan). Esse processo pode ser muito demorado, principalmente em tabelas com milhões de registros.
Os índices resolvem esse problema, proporcionando um caminho otimizado para encontrar dados específicos sem precisar ler todos os registros.
Dessa forma, o uso de índices reduz drasticamente o tempo de execução de consultas, garantindo uma performance muito superior.
Como os índices reduzem o tempo de execução?
Quando uma consulta é realizada, o PostgreSQL utiliza um índice, se disponível, para buscar as informações de forma eficiente.
Em vez de percorrer linha a linha de uma tabela, o índice permite que o banco vá diretamente ao ponto desejado.
Por exemplo, imagine uma tabela chamada clientes com 1 milhão de registros, e precisamos buscar um cliente específico pelo número de CPF.
Sem um índice, a consulta teria que percorrer os 1 milhão de registros até encontrar o CPF correspondente.
Com um índice criado na coluna de CPF, o PostgreSQL consegue encontrar o registro em um tempo muito menor, utilizando uma pesquisa mais eficiente (como uma pesquisa binária).
Tipos de Índices no PostgreSQL
Vamos explorar os principais tipos de índices disponíveis no PostgreSQL, explicando suas características, funcionamento e as situações nas quais cada um é mais adequado. Isso ajudará você a compreender como escolher o índice correto para cada tipo de consulta.
B-Tree
O índice do tipo B-tree é o padrão no PostgreSQL e é, de longe, o tipo mais comum e amplamente utilizado.
A principal característica do B-tree é a sua capacidade de manter os valores em ordem, facilitando buscas que envolvem tanto igualdade quanto intervalos.
Quando utilizamos um índice B-tree, o PostgreSQL consegue fazer buscas binárias nos dados indexados, o que é extremamente eficiente para encontrar valores exatos ou para consultas que filtram por um intervalo (por exemplo, todos os valores entre X e Y).
Casos de Uso
- Consultas de Igualdade: Quando precisamos buscar registros que tenham um valor específico em uma coluna, como buscar por um cliente específico usando o CPF.
- Consultas por Intervalo: Quando precisamos de todos os registros em um intervalo específico, como buscar todas as vendas feitas entre duas datas.
Exemplo de Criação
CREATE INDEX idx_nome_cliente ON clientes(nome);Esse índice torna muito mais rápida uma consulta como:
SELECT * FROM clientes WHERE nome = 'Maria';ou
SELECT * FROM vendas WHERE data_venda BETWEEN '2023-01-01' AND '2023-12-31';Hash
O índice do tipo Hash é utilizado especificamente para buscas de igualdade. Este índice calcula um valor de hash para os dados, tornando a pesquisa por valores exatos muito eficiente.
No entanto, ele não é eficaz para buscas por intervalos, e, por isso, tem um uso mais limitado em comparação com o B-tree.
Além disso, o índice Hash tem algumas limitações em termos de manutenção e não oferece suporte nativo para recuperação em algumas operações como os índices B-tree.
Até algumas versões passadas do PostgreSQL, os índices do tipo Hash não eram transacionais, mas isso foi aprimorado nas versões mais recentes.
Casos de Uso
- Busca de Igualdade Simples: Ideal para situações onde sempre se faz uma consulta por igualdade, como verificar se um número de identificação específico está presente.
Exemplo de Criação
CREATE INDEX idx_cliente_cpf_hash ON clientes USING hash(cpf);Este índice pode acelerar consultas do tipo:
SELECT * FROM clientes WHERE cpf = '123.456.789-00';GIN (Generalized Inverted Index)
O GIN (Generalized Inverted Index) é um tipo de índice extremamente útil para colunas que armazenam coleções de valores, como arrays, ou para realizar pesquisas textuais completas (full-text search).
Ele cria uma lista invertida, o que significa que mantém um mapeamento dos valores armazenados em uma coluna para os registros que contêm esses valores. Isso torna o GIN muito eficiente para consultas que envolvem múltiplos valores.
Casos de Uso
- Full-Text Search: Utilizado para acelerar buscas em textos longos, como artigos ou descrições.
- Arrays: Muito útil quando uma coluna armazena um array de valores e precisamos realizar consultas que envolvam um dos elementos do array.
Exemplo de Criação
CREATE INDEX idx_documento_texto ON documentos USING gin(to_tsvector('portuguese', conteudo));Este índice acelera consultas como:
SELECT * FROM documentos WHERE to_tsvector('portuguese', conteudo) @@ to_tsquery('portuguese', 'análise & performance');GiST (Generalized Search Tree)
O GiST (Generalized Search Tree) é um índice mais flexível, que permite implementar estruturas personalizadas de indexação.
Ele é ideal para buscas que envolvem dados não triviais, como dados espaciais, e suporta operações complexas, como pesquisa por proximidade.
Ele é frequentemente utilizado com dados geoespaciais, pois permite fazer consultas que buscam registros dentro de uma determinada área ou proximidade, algo essencial para sistemas de geolocalização e mapas.
Casos de Uso
- Dados Espaciais: Quando lidamos com coordenadas geográficas e precisamos buscar dados dentro de uma determinada área.
- Dados Multidimensionais: Utilizado em tabelas com dados que não são puramente textuais ou numéricos, mas que representam formas ou outras dimensões.
Exemplo de Criação
CREATE INDEX idx_localizacao ON pontos_interesse USING gist(geolocalizacao);Este índice é útil para acelerar consultas como:
SELECT * FROM pontos_interesse WHERE geolocalizacao && ST_MakeEnvelope(-46.7, -23.5, -46.6, -23.4, 4326);Aqui, a consulta busca todos os pontos de interesse dentro de uma determinada área geográfica.
Cada tipo de índice tem suas vantagens e limitações, e a escolha do índice adequado depende do tipo de consulta que se pretende otimizar.
O uso apropriado dos índices pode trazer uma grande melhoria no desempenho das consultas, especialmente em sistemas com grandes volumes de dados e necessidades complexas de filtragem.
Prós e contras no uso dos índices
Os índices são estruturas de dados que, com o tempo, podem se tornar ineficientes ou crescer excessivamente, afetando o desempenho em vez de otimizá-lo.
Vamos detalhar melhor o quadro a seguir. Para isso, observe as colunas:
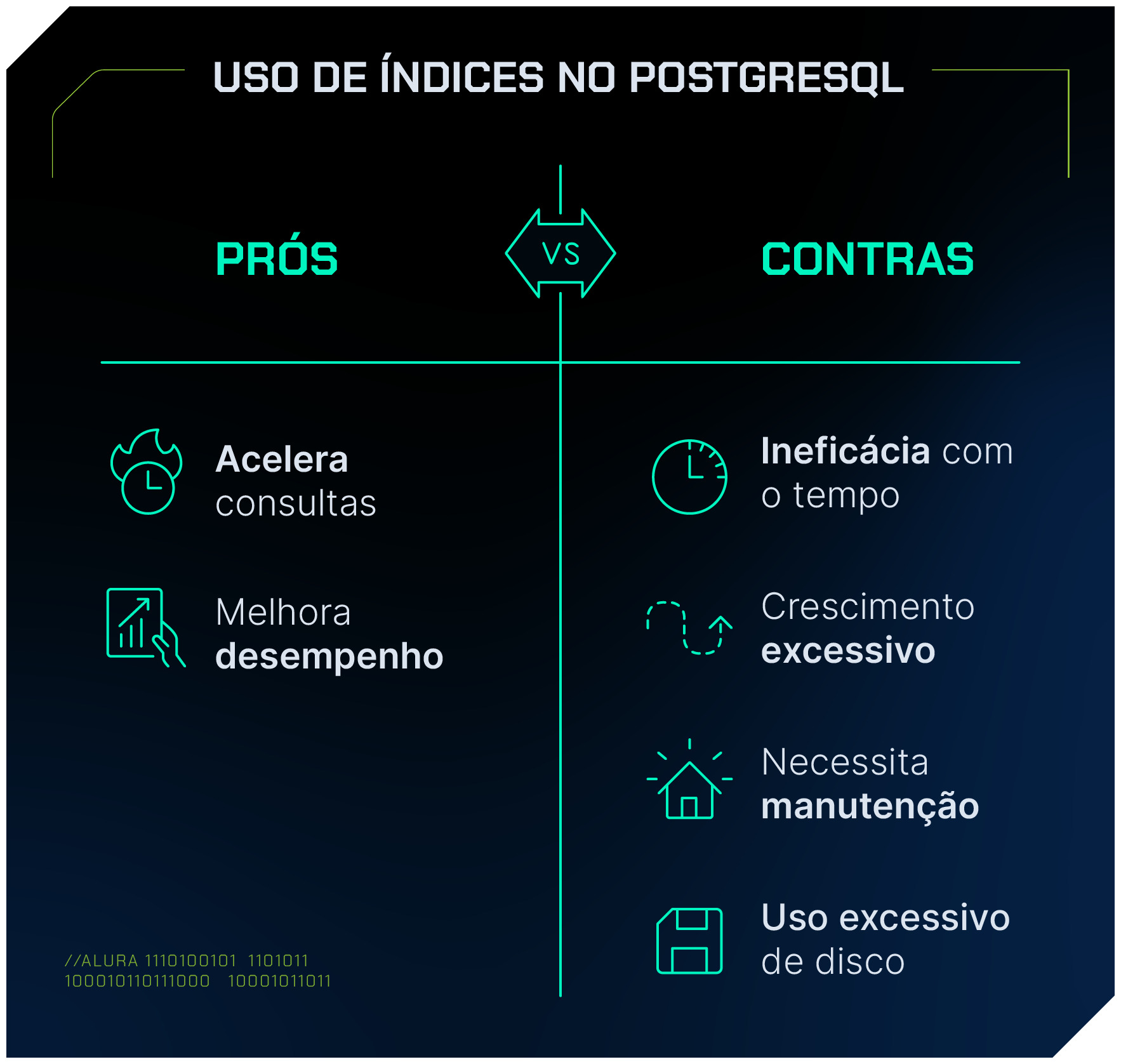
Prós do uso de índices no PostgreSQL
- Acelera consultas:
Índices são projetados para melhorar a velocidade das operações de busca. Quando você precisa consultar grandes volumes de dados, a utilização de índices pode reduzir significativamente o tempo de execução da consulta, especialmente em colunas frequentemente usadas para filtros, junções ou ordenações.
Isso acontece porque o índice atua como um “atalho” para localizar os registros relevantes sem precisar varrer todas as linhas de uma tabela.
- Melhora o desempenho geral:
Além de acelerar consultas específicas, índices também ajudam a melhorar o desempenho geral do banco de dados.
Em sistemas que demandam consultas complexas, como sistemas de análise de dados ou ambientes transacionais, o uso adequado de índices pode otimizar a execução dessas operações, resultando em um uso mais eficiente dos recursos do servidor e um melhor tempo de resposta para os usuários.
Contras do uso de índices no PostgreSQL
Ineficácia com o tempo:
Índices tendem a se tornar menos eficazes à medida que os dados no banco crescem e mudam.
A inserção, atualização e exclusão de registros podem deteriorar a estrutura do índice, tornando-o mais fragmentado e menos eficiente ao longo do tempo. Isso exige manutenções periódicas, como reindexações, para garantir que eles continuem proporcionando o desempenho desejado.
- Crescimento excessivo:
Conforme o banco de dados cresce, os índices também podem crescer em tamanho. Embora eles otimizem consultas, o espaço adicional necessário no disco pode se tornar considerável em grandes bancos de dados.
Além disso, múltiplos índices em uma única tabela podem aumentar significativamente o tamanho total do armazenamento.
- Necessidade de manutenção:
Índices não são "mágicos"; eles requerem manutenção. Para que permaneçam eficazes, é necessário realizar operações como VACUUM e REINDEX regularmente, especialmente em bancos de dados altamente transacionais.
Sem essa manutenção, os índices podem se tornar um fardo e, eventualmente, até prejudicar o desempenho ao invés de melhorá-lo.
- Uso Excessivo de Disco:
Índices ocupam espaço no disco, o que pode ser uma preocupação, especialmente em ambientes onde o armazenamento é limitado ou onde há muitas tabelas grandes.
O uso de vários índices aumenta ainda mais o uso de disco, o que pode impactar os custos de armazenamento e gerenciamento de recursos.
Além disso, quanto mais índices uma tabela possui, mais tempo levará para operações de escrita, como inserções e atualizações, pois todos os índices relevantes precisam ser atualizados junto com os dados.
Embora os índices no PostgreSQL tragam grandes benefícios, especialmente em termos de desempenho e eficiência nas consultas, é importante gerenciá-los com cuidado.
O uso excessivo ou indevido de índices pode resultar em sobrecarga de manutenção e consumo desnecessário de recursos.
Assim, é crucial equilibrar a criação de índices com a necessidade real das consultas, levando em conta o impacto no armazenamento e a necessidade de manutenção ao longo do tempo.
Identificação de gargalos em consultas
Antes de criar um índice, é fundamental entender onde estão os gargalos no desempenho das consultas.
Nem toda consulta lenta é solucionada com um índice, e o uso inadequado de índices pode, inclusive, prejudicar a performance de operações de escrita.
Portanto, saber como identificar os problemas é o primeiro passo para aplicar soluções eficazes.
Uma das principais ferramentas do PostgreSQL para analisar o desempenho de consultas é o comando EXPLAIN.
Esse comando mostra como o PostgreSQL pretende executar a consulta, fornecendo informações sobre os planos de execução que ele utiliza.
A versão EXPLAIN ANALYZE vai além, executando a consulta e fornecendo detalhes sobre o tempo gasto em cada etapa.
- EXPLAIN: Mostra o plano de execução sem executar a consulta.
- EXPLAIN ANALYZE: Executa a consulta e mostra o plano de execução juntamente com o tempo gasto.
Por exemplo:
EXPLAIN ANALYZE SELECT * FROM vendas WHERE data_venda BETWEEN '2023-01-01' AND '2023-12-31';Com o resultado deste comando, podemos verificar se a consulta está realizando uma varredura completa de tabela (full table scan), o que pode ser um forte indicativo de que um índice deve ser criado para melhorar o desempenho.
Interpretando o Plano de Execução
O plano de execução gerado pelo EXPLAIN fornece informações como:
- Seq Scan (Varredura Sequencial): Indica que todos os registros da tabela estão sendo percorridos, o que pode ser um problema em tabelas grandes.
- Index Scan: Mostra que o PostgreSQL está utilizando um índice para buscar os dados.
- Custo Estimado: O PostgreSQL apresenta um custo estimado para cada operação, permitindo comparar diferentes planos e identificar qual operação está tornando a consulta lenta.
Após identificar onde está o gargalo, o próximo passo é escolher qual índice criar para resolver o problema de forma eficaz.
A escolha do índice depende do tipo de consulta que está causando problemas e do tipo de dados envolvidos.
Existem algumas boas práticas ao utilizar os índices:
- Evitar Índices Redundantes: Índices ocupam espaço em disco e precisam ser mantidos, o que aumenta o custo de operações de escrita. Portanto, crie apenas índices que realmente tragam benefícios significativos.
- Índices Compostos: Quando consultas frequentemente filtram por múltiplas colunas, um índice composto pode ser útil. Por exemplo:
CREATE INDEX idx_cliente_data ON vendas(cliente_id, data_venda);Isso otimiza consultas que buscam todas as vendas de um cliente em um determinado período.
- Manutenção de Índices: O PostgreSQL atualiza os índices automaticamente, mas é importante monitorar seu uso. Índices não utilizados podem ser removidos para melhorar o desempenho geral do banco de dados.
O PostgreSQL decide usar ou não um índice com base no custo estimado da operação. Isso significa que, dependendo das estatísticas da tabela (mantidas por meio de operações como ANALYZE), ele pode optar por não usar um índice se determinar que uma varredura completa de tabela seria mais eficiente. Portanto, é essencial entender o comportamento do plano de execução e garantir que as estatísticas estejam atualizadas para obter os melhores resultados.
Índices Compostos
Os índices compostos são índices criados em mais de uma coluna. Eles são úteis para otimizar consultas que frequentemente filtram por múltiplas colunas, permitindo ao PostgreSQL usar um único índice para satisfazer a consulta inteira em vez de acessar vários índices.
Os índices compostos são extremamente úteis quando:
- A consulta utiliza filtros em múltiplas colunas de maneira recorrente.
- A ordem das colunas no filtro corresponde à ordem em que elas estão no índice composto.
Por exemplo, imagine que temos uma tabela vendas e frequentemente precisamos buscar por registros de vendas por cliente_id e data_venda. Podemos criar um índice composto para otimizar essa consulta.
Exemplo Prático
CREATE INDEX idx_cliente_data ON vendas(cliente_id, data_venda);Este índice composto otimiza consultas como:
SELECT * FROM vendas WHERE cliente_id = 123 AND data_venda BETWEEN '2023-01-01' AND '2023-12-31';No exemplo acima, ao utilizar um índice que considera ambas as colunas, o PostgreSQL consegue acelerar a busca significativamente.
A ordem das colunas em um índice composto é importante. O PostgreSQL utiliza os índices da esquerda para a direita, ou seja, se criarmos um índice com (cliente_id, data_venda), ele será mais eficiente para consultas que filtram primeiro pelo cliente_id. Consultas que filtram apenas por data_venda não se beneficiarão desse índice da mesma forma.
Particionamento de Tabelas
O particionamento de tabelas é uma técnica de dividir uma tabela grande em partes menores e mais manejáveis, chamadas de partições.
Cada partição contém um subconjunto dos dados da tabela original, e isso torna as consultas mais rápidas porque cada consulta pode acessar apenas a partição relevante, ao invés de percorrer a tabela inteira.
No PostgreSQL, o particionamento pode ser feito com base em colunas como data, região, ou qualquer outra coluna que faça sentido dividir os dados. Observe, a seguir, os tipos de particionamentos:
- Particionamento por Intervalo (Range Partitioning): Divide a tabela com base em um intervalo, como uma coluna de datas.
- Particionamento por Lista (List Partitioning): Cada partição armazena uma lista de valores específicos.
- Particionamento por Hash (Hash Partitioning): Usado para distribuir registros uniformemente, baseado no valor de uma coluna.
Cada partição pode ter seus próprios índices, permitindo que consultas específicas sejam executadas de forma mais eficiente, pois o PostgreSQL acessará apenas as partições e índices relevantes para aquela consulta.
Exemplo Prático
Imagine que temos uma tabela de vendas muito grande, com registros de vários anos. Podemos particioná-la por ano para melhorar o desempenho das consultas:
CREATE TABLE vendas (
id SERIAL PRIMARY KEY,
cliente_id INTEGER,
data_venda DATE,
valor NUMERIC
) PARTITION BY RANGE (data_venda);E, em seguida, criamos partições para cada ano:
CREATE TABLE vendas_2023 PARTITION OF vendas
FOR VALUES FROM ('2023-01-01') TO ('2023-12-31');
CREATE TABLE vendas_2024 PARTITION OF vendas
FOR VALUES FROM ('2024-01-01') TO ('2024-12-31');Neste cenário, uma consulta que busca registros de vendas de 2023 só precisará acessar a partição vendas_2023, melhorando consideravelmente o desempenho.
Considerações de custo e estatísticas
O PostgreSQL decide se deve ou não usar um índice com base no custo estimado das operações, conforme determinado pelo otimizador do banco de dados.
O otimizador leva em consideração as estatísticas coletadas por meio da operação ANALYZE, que mantém o banco de dados informado sobre a distribuição dos dados. Essas estatísticas ajudam a determinar a eficácia de um índice para uma determinada consulta.
Manter as estatísticas das tabelas e dos índices atualizados é essencial para que o PostgreSQL possa tomar boas decisões. Isso pode ser feito utilizando:
ANALYZE nome_da_tabela;Dessa forma, garantimos que o otimizador tenha informações precisas sobre o tamanho das tabelas e a distribuição dos dados.
Conclusão
O entendimento profundo sobre índices e sua aplicação prática é indispensável para qualquer profissional que deseje otimizar a performance de sistemas de banco de dados PostgreSQL.
Conhecer os diferentes tipos de índices, como B-tree, Hash, GIN, e GiST, e saber quando e como utilizá-los, não só garante a eficiência dos sistemas, mas também diferencia o profissional no mercado.
Essas habilidades técnicas são o alicerce para proporcionar uma experiência fluida e de alto desempenho aos usuários, além de manter a competitividade da organização em um ambiente onde o volume de dados não para de crescer.
Mais do que um conjunto de técnicas, dominar a utilização de índices é uma competência estratégica que impacta diretamente o sucesso dos negócios.
Empresas que dependem de bancos de dados volumosos e complexos precisam de profissionais capazes de identificar gargalos de desempenho e implementar soluções eficazes e proativas.
Portanto, o conhecimento adquirido sobre índices e sua manutenção é crucial para assegurar a disponibilidade e o funcionamento adequado das operações empresariais.
Além disso, a busca pela melhoria contínua é parte integral do trabalho de otimização de bancos de dados.
A implementação de índices é apenas o começo de um processo dinâmico e constante de análise e aprimoramento, utilizando ferramentas como o EXPLAIN ANALYZE e revisando regularmente os índices existentes.
Isso demonstra a importância de se manter atualizado sobre novas técnicas, como o particionamento de tabelas e o estudo detalhado dos planos de execução.
Dominar a otimização de consultas transforma a performance dos sistemas e agrega valor ao negócio.
A eficiência nesse processo reduz custos, melhora a experiência do usuário e destaca o profissional no mercado.
O conhecimento sobre índices é um diferencial competitivo essencial para o seu crescimento e o sucesso das empresas.
Quer continuar evoluindo e se destacando na sua carreira? Na Alura, você encontra os cursos e recursos que precisa para aprimorar suas habilidades e avançar ainda mais. Comece agora e alcance novos horizontes!
Créditos
- Conteúdo: Victorino Vila
- Produção técnica: Rodrigo Dias
- Produção didática: Cláudia Machado
- Designer gráfico: Alysson Manso
