As fantásticas novidades do HTTP 2.0 e do SPDY
A nova versão do protocolo HTTP e seu irmão SPDY trazem mudanças fundamentais para a Web. Recursos fantásticos que vão melhorar muito a performance da Web além de simplificar a vida dos desenvolvedores.
No post anterior do Luiz Corte Real aqui no blog, apresentamos o SPDY e o HTTP 2.0, o que eles são e porque são importantes. Desde então, eu e ele apresentamos uma palestra com as novidades dos protocolos no QCon SP 2014. Vamos às novidades.
Compressão automática
No HTTP 1.1, para melhorar a performance, habilitamos o GZIP no servidor para comprimir os dados das respostas. É uma excelente prática, mas que precisa ser habilitada explicitamente. No HTTP 2.0, o GZIP é padrão e obrigatório.

Mas, se você já olhou como funciona uma requisição HTTP, vai notar que só GZIPar as respostas resolve só metade do problema. Tanto o request quanto o response levam vários cabeçalhos (headers) que não são comprimidos no HTTP 1.1 e ainda viajam em texto puro.
No HTTP 2.0, os headers são binários e comprimidos usando um algoritmo chamado HPACK. Isso diminui bastante o volume de dados trafegados nos headers.
Criptografia e segurança
O SPDY obriga o uso de HTTPS e conexões seguras. O HTTP 2.0 até pensa em permitir uso sem SSL, mas na prática todo mundo vai suportar apenas conexões seguras HTTPS. O resultado é que ganhamos segurança e privacidade automaticamente no protocolo, uma boa coisa nos dias de hoje. Claro, limita um pouco mais porque todos vão precisar usar SSL e conseguir um certificado, mas esse já um movimento natural da Web mesmo sem os protocolos novos.
Essa obrigatoriedade do SSL na verdade tem origem prática, na forma como a Web vai evoluir. É que tanto o SPDY quanto o HTTP 2.0 mudam radicalmente a forma como os dados são trafegados e isso tem potencial pra quebrar muita coisa na Web. Quer dizer, se simplesmente os servidores passassem a suportar HTTP 2.0 da noite pro dia, navegadores velhos seriam incompatíveis e intermediários (como proxies, CDNs etc) ficariam perdidos. Até que toda a Web seja migrada pra HTTP 2.0, não podemos trafegar o protocolo novo abertamente, senão quebramos compatibilidade.
A solução? Usar SSL. Com ele, o servidor consegue negociar com o browser o uso do novo protocolo sem quebrar browsers antigos. E, por ser tudo criptografado, os intermediários não serão afetados. Ou seja, SSL veio para resolver o problema de deploy do HTTP 2.0 e do SPDY e acabou trazendo a segurança de brinde.
Paralelização de requests com multiplexing
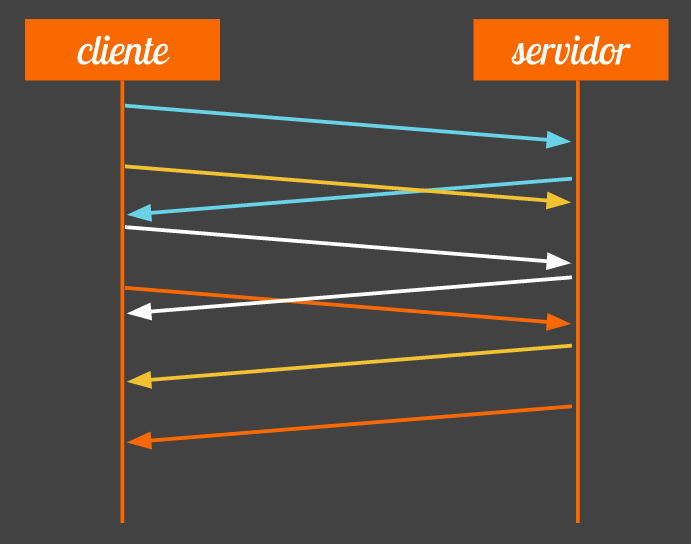
Uma página Web comum hoje inclui dezenas de recursos - imagens, arquivos CSS, JS etc. Cada recurso é um request feito e, para que a página carregue rapidamente, precisamos paralelizar essas requisições, baixar mais de uma coisa por vez. O problema é que o HTTP 1.1 é um protocolo sequencial. Isso quer dizer que, quando abrimos a conexão, podemos fazer 1 request por vez. Vai 1 request, esperamos, chega a resposta; só aí podemos disparar outro request.
Para tentar diminuir o impacto negativo desse comportamento, os navegadores com HTTP 1.1 abrem mais de uma conexão ao mesmo tempo. Hoje em dia esse número costuma ser de 4 a 8 conexões simultâneas por hostname. Isso quer dizer paralelizar os requests em 4 a 8 requests. Já ajuda mas, se sua página tem 80 requests, o carregamento ainda vai ser bastante sequencial. Ainda no HTTP 1.1, uma gambiarra comum é usar vários hostnames na página (site.com e img.site.com por exemplo), assim ganhamos mais conexões paralelas.
No HTTP 2.0 e no SPDY, as requisições e respostas são paralelas automaticamente em uma única conexão. É o chamado multiplexing que deixa que façamos vários requests ao mesmo tempo e recebamos as respostas de volta conforme forem ficando prontas, tudo paralelo e assíncrono. Com isso, 1 conexão só já basta e não precisamos de vários hostnames. Fica tudo mais fácil e mais leve, por exigir menos conexões na rede.
Só cabeçalhos que mudam
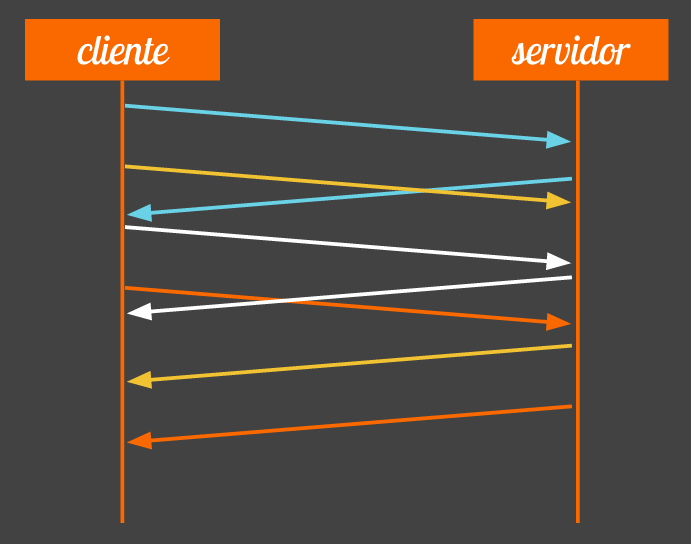
Cada request e cada response no HTTP manda vários cabeçalhos no topo da requisição. Um famoso que vai a cada request é o User-Agent, que identifica o browser com uma string gigante. (o meu aqui hoje é Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/36.0.1933.0 Safari/537.36).
Agora imagine esse e outros headers sendo enviados o tempo todo, a cada requisição, em uma página com centenas de requisições. Perda de tempo. No HTTP 2.0 e no SPDY, o protocolo mudou isso. Mandamos apenas os cabeçalhos que mudarem entre requisições.
O caso o User-Agent é ótimo. O primeiro request manda esse cabeçalho gigante pro servidor mas todo request seguinte já assume esse valor e o header não precisa ser repetido. Muito útil se pensar que há vários outros headers que não costumam mudar entre requests.
Priorização de requests
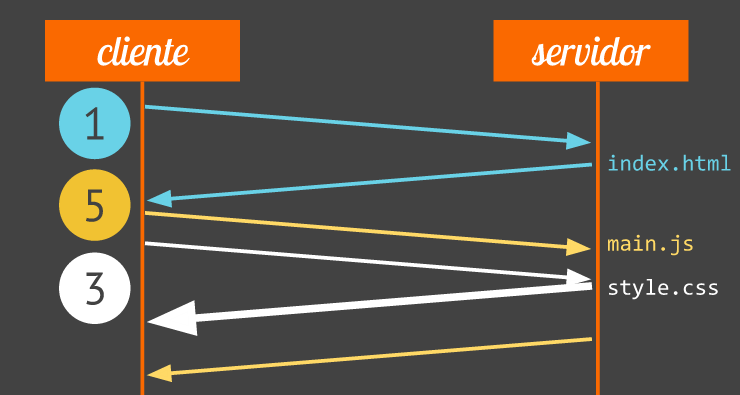
Uma otimização muito importante nas páginas é a de facilitar a renderização inicial. Isso significa priorizar os recursos necessários para o usuário começar a ver a página e interagir e deixar coisas secundárias pra depois.
No HTTP 2.0 e no SPDY, o navegador pode indicar nos requests quais deles são mais importantes. Ele prioriza numericamente as requisições para indicar pro servidor quais respostas ele deve mandar antes, se puder. O browser pode, por exemplo, dar prioridade máxima a um arquivo CSS no head que bloqueia a renderização, enquanto deixa prioridade mais baixa para um JS assíncrono no fim da página.
Server-Push
Ainda nessa ideia de priorizar os elementos necessários para a renderização inicial da página, é muito comum no HTTP 1.1 as pessoas fazerem inline de recursos. É, por exemplo, pegar o conteúdo CSS necessário para o início da página e embutir direto no HTML com uma tag