Arquiteturas de redes neurais: aplicações práticas na Inteligência Artificial


Você já se perguntou como seu smartphone reconhece seu rosto ou como os assistentes virtuais entendem o que você fala?
Tudo isso é graças às redes neurais! Inspiradas no funcionamento do nosso cérebro, elas estão revolucionando a Inteligência Artificial e permitindo avanços incríveis em áreas como reconhecimento de imagens, linguagem natural e robótica.
O mais fascinante é que elas aprendem padrões complexos a partir de dados brutos, como um quebra-cabeça sendo montado. Essa habilidade poderosa ajuda a resolver problemas que antes pareciam impossíveis.
Mas o que torna tudo isso possível? A variedade de arquiteturas de redes neurais!
Cada tipo tem suas próprias forças e fraquezas, sendo adaptado para diferentes tarefas e tipos de dados.
Conhecer essas diferentes estruturas é essencial para quem quer se aventurar no mundo do aprendizado profundo e aplicar essas tecnologias de forma eficaz.
Neste artigo, vamos explorar as principais arquiteturas de redes neurais. Começaremos pelas redes perceptron e iremos até as mais avançadas, como as redes convolucionais e recorrentes.
Vamos descobrir os princípios básicos de cada uma, onde elas são mais utilizadas e quais são suas vantagens e desvantagens.
Nosso objetivo é oferecer a você uma visão completa e acessível desse universo fascinante, ajudando na escolha da arquitetura mais adequada para cada desafio e permitindo que você desbloqueie todo o potencial das redes neurais.
Perceptron Multicamadas (MLP)
As diferentes arquiteturas de redes neurais podem ser adaptadas para uma variedade de problemas, dependendo das características dos dados e das tarefas a serem resolvidas.
A rede MLP (Multilayer Perceptron) é uma das formas mais simples e tradicionais de rede neural, composta por camadas densamente conectadas, também conhecidas como fully connected.
Ela é amplamente utilizada em tarefas de classificação e regressão, especialmente com dados tabulares.
Com uma MLP, é possível construir modelos que estimam valores contínuos, como o preço de casas, com base em variáveis geográficas e características dos imóveis da região.
Além disso, ela pode ser aplicada na classificação de problemas de saúde, como prever se uma pessoa tem diabetes a partir de resultados de exames médicos.
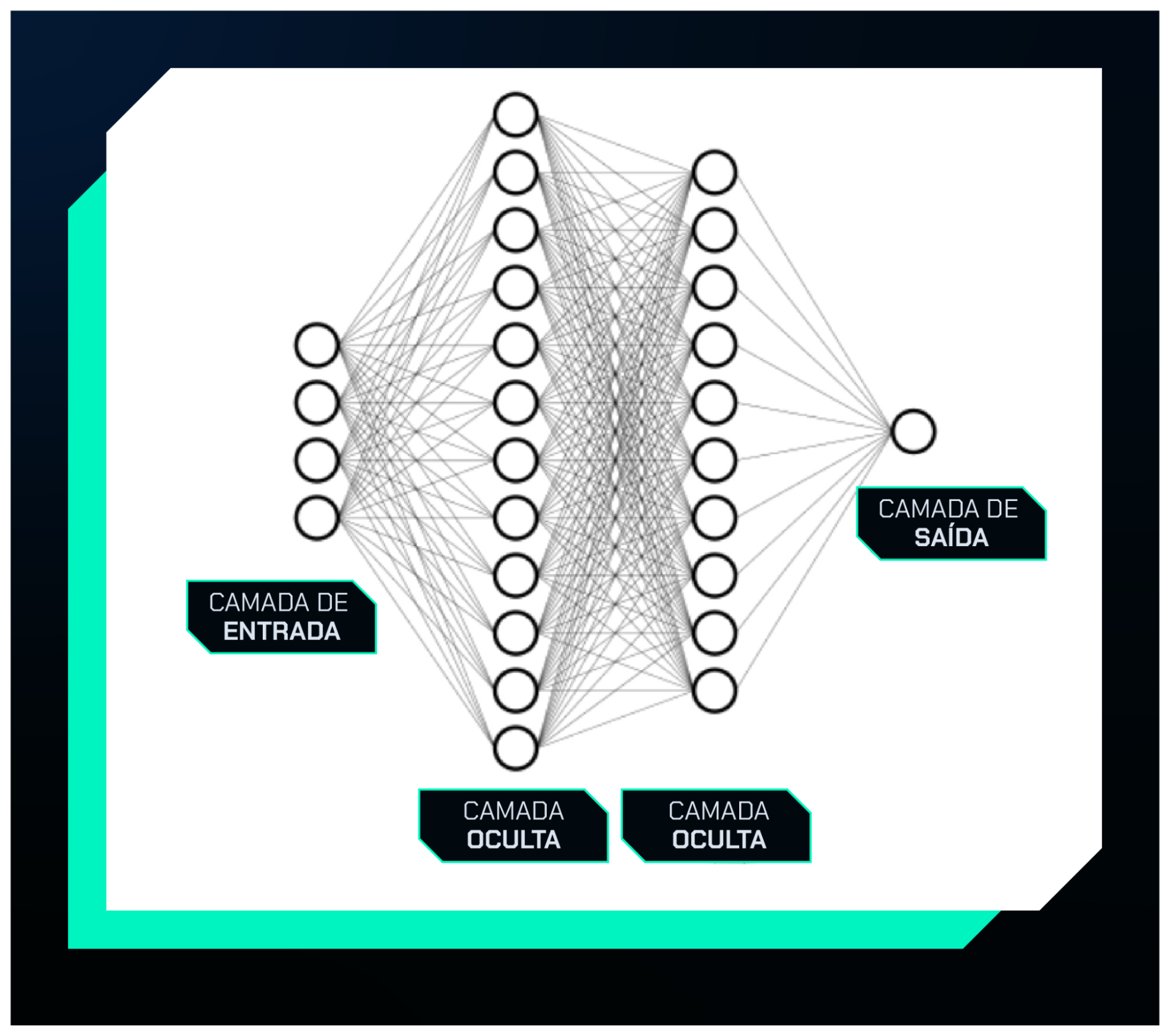
A seguir, Camila Laranjeira revela como esse tipo de rede neural tem o poder de aproximar qualquer função contínua, trazendo uma explicação clara e fascinante que vai mudar sua compreensão sobre o tema:


Redes Neurais Convolucionais (CNNs)
Embora a arquitetura MLP seja bastante poderosa, encontrar a configuração ideal de neurônios, camadas ou funções de ativação pode ser desafiador.
No entanto, ao utilizar camadas especializadas para o tipo de dado com o qual estamos lidando, mesmo configurações simples podem resultar em modelos de alta performance.
As Redes Neurais Convolucionais (CNNs) são projetadas exatamente com esse propósito. Elas introduzem camadas convolucionais que aplicam filtros sobre os dados durante o treinamento.
Esses filtros são aprendidos pela rede e permitem a identificação e o destaque de características importantes, melhorando a precisão em tarefas como classificação e regressão.
CNNs são amplamente utilizadas em visão computacional, como na classificação de imagens e detecção de objetos, pois as operações de convolução são altamente eficazes para capturar padrões espaciais e características dentro de uma imagem.
Observe e analise o diagrama a seguir.
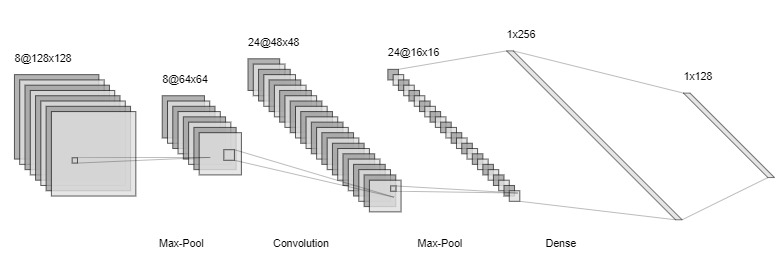
No exemplo apresentado, observamos uma rede onde as primeiras camadas são convolucionais, combinadas com camadas de max-pooling. O max-pooling realiza a redução dimensional, diminuindo a quantidade de parâmetros e a complexidade da rede.
Após essas camadas, temos camadas densas, semelhantes às usadas nas redes MLP, que finalizam o processo de aprendizado e classificação.
Redes Neurais Recorrentes (RNNs)
Alguns tipos de dados possuem um caráter sequencial, como as séries temporais. Por exemplo, o preço de ações de uma empresa de agronomia pode ser influenciado por fatores sazonais, como o clima, ou por eventos recentes, como um escândalo político ocorrido no dia anterior.
Nesse tipo de dado, é importante lembrar dos eventos passados e considerar que esses eventos podem se repetir sazonalmente ou não. Outro exemplo de dados sequenciais são os textos.
Ao ouvir a frase "Eu quero comer uma", é muito mais provável que a sequência seja completada com "pizza" do que com "britadeira".
Para lidar com essas características, as Redes Neurais Recorrentes (RNNs) possuem uma memória interna que permite capturar dependências ao longo de sequências temporais.
Na ilustração abaixo, podemos observar a arquitetura de uma RNN, onde parte da informação é retroalimentada para o mesmo neurônio, o que dá à rede sua capacidade de tratar dados sequenciais de forma eficaz.
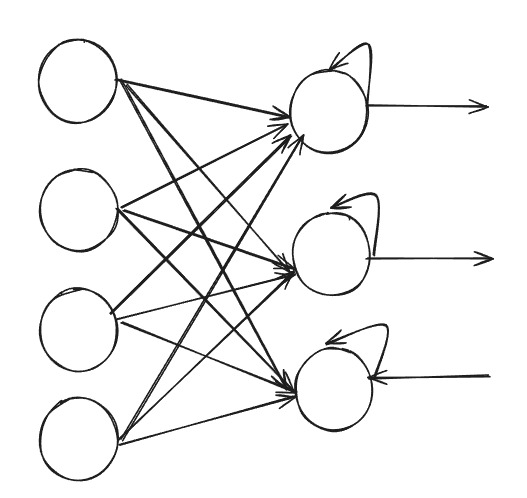
Existem variantes populares das RNNs, como as Long Short-Term Memory (LSTM) e as Gated Recurrent Units (GRUs).
As LSTMs são capazes de capturar dependências de longo prazo, lidando bem com sequências extensas, enquanto as GRUs, embora mais simples, também são altamente eficazes no processamento de sequências longas.
Redes Neurais Generativas Adversárias (GANs)
Ao invés de querer treinar uma rede que realiza uma tarefa como a de classificação que tenta realizar o discernimento entre uma informação e outra, você pode querer “ensinar” uma rede a gerar um determinado tipo de informação como uma imagem ou um texto. As GANs podem ser utilizadas na tarefa de geração de imagens.
Elas são compostas por duas redes diferentes, uma rede geradora e uma rede discriminadora. Durante o treinamento essas redes competem melhorando conjuntamente em suas tarefas.
Esse treinamento ocorre até que a rede geradora seja capaz de gerar uma imagem que seja o mais próxima possível de uma imagem real, parecida com a de um conjunto de imagens usado no treinamento da rede.

GANs têm sido responsáveis por avanços impressionantes em diversas áreas. Um exemplo clássico é o DeepFake, onde vídeos realistas de pessoas podem ser gerados com base em dados visuais e de áudio.
Além disso, GANs são usadas em arte, geração de imagens de alta resolução e até na criação de modelos 3D.
Transformers
As redes Transformers representam uma evolução significativa no campo do aprendizado de máquina, especialmente em tarefas relacionadas a processamento de linguagem natural (NLP).
Diferente das RNNs, que processam sequências de forma ordenada (passo a passo), os Transformers são capazes de lidar com sequências de forma paralela, o que os torna mais eficientes, especialmente para tarefas que envolvem grandes volumes de dados, como tradução automática, geração de texto e até processamento de imagens.
A chave para o sucesso dos Transformers está no mecanismo de atenção, mais especificamente na atenção denominada self-attention. Esse mecanismo permite que a rede atribua diferentes pesos para diferentes partes da sequência de entrada. Em termos práticos, imagine que estamos traduzindo uma frase.
Com uma rede Transformer, a atenção é capaz de focar nas palavras mais importantes de acordo com o contexto, sem precisar processá-las na ordem em que aparecem. Isso permite que o modelo capture relações de longo alcance de maneira muito mais eficaz.
O Transformer é composto por blocos de camadas, onde o mecanismo de atenção é combinado com redes neurais densas para refinar e processar a entrada.
O modelo padrão contém duas partes principais: o codificador e o decodificador. O codificador recebe a sequência de entrada e gera uma representação interna dela, enquanto o decodificador usa essa representação para gerar a saída, como a tradução de uma frase ou a resposta para uma pergunta.
A seguir, apresentamos uma ilustração da estrutura básica de uma rede Transformer.

Se o tema despertou seu interesse, você pode se aprofundar mais nesse tema acessando este artigo.
Nele você terá a possibilidade de explorar como os Transformers revolucionam o processamento de linguagem natural e quais benefícios eles trazem para diversas aplicações.
Ao contrário das RNNs e LSTMs, que possuem limitações para lidar com longas dependências temporais, os Transformers podem capturar relações complexas em sequências longas de maneira mais eficiente, sem sofrer com problemas de memória ou perdas de informação ao longo da sequência.
Por isso, eles se tornaram o padrão ouro em muitas tarefas de NLP.
Autoencoders
Os Autoencoders são um tipo de rede neural utilizada principalmente para compressão de dados e aprendizado não supervisionado.
Sua principal característica é a capacidade de aprender representações comprimidas dos dados de entrada, capturando suas principais características em um espaço de menor dimensão.
Essa habilidade os torna úteis em tarefas como redução de dimensionalidade, remoção de ruído e até mesmo geração de dados.
A arquitetura básica de um Autoencoder é composta por duas partes: o codificador (encoder) e o decodificador (decoder). O codificador recebe a entrada e a comprime em uma representação de menor dimensão chamada bottleneck ou camada latente.
Essa camada latente contém a informação mais essencial dos dados de entrada. Já o decodificador utiliza essa representação comprimida para tentar reconstruir a entrada original.
A ideia central é que o modelo aprenda a remover redundâncias dos dados, preservando apenas a informação mais relevante.
Durante o treinamento, o Autoencoder é ajustado para minimizar a diferença entre a entrada original e a saída reconstruída.
Isso permite que ele aprenda representações eficientes, o que pode ser extremamente útil, por exemplo, na redução de dimensionalidade de grandes conjuntos de dados ou na remoção de ruídos de imagens.
Uma característica interessante dos Autoencoders é sua versatilidade. Eles podem ser aplicados em várias tarefas, como detecção de anomalias (onde os dados reconstruídos diferem significativamente dos dados normais) ou geração de novas amostras a partir da camada latente, como acontece em Variational Autoencoders (VAEs), uma variante popular.
U-Nets e Redes Difusoras
As U-Nets são um tipo de rede neural amplamente utilizada em tarefas que envolvem segmentação de imagens, como em imagens médicas e processamento de imagens de satélites.
O principal objetivo das U-Nets é realizar uma segmentação precisa, identificando objetos ou regiões específicas dentro de uma imagem.
Sua arquitetura se assemelha a um formato de "U", com uma parte de codificação e uma parte de decodificação, sendo particularmente eficaz quando precisamos tanto de detalhes globais quanto de informações locais.
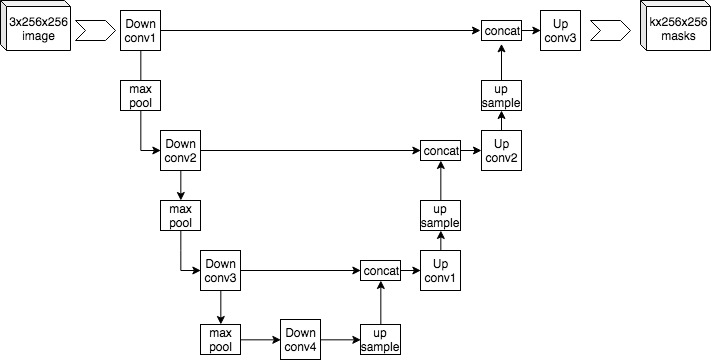
Fonte: Mehrdad Yazdani, CC BY-SA 4.0 https://creativecommons.org/licenses/by-sa/4.0, via Wikimedia Commons
A estrutura de uma U-Net é composta por duas partes principais: o caminho de contração (encoder) e o caminho de expansão (decoder).
No caminho de contração, a rede aprende a reduzir a dimensionalidade dos dados, extraindo características importantes através de camadas convolucionais e operações de max-pooling.
No caminho de expansão, a rede usa operações de upsampling para reconstruir a imagem segmentada, restaurando as características espaciais, enquanto combina informações das camadas anteriores por meio de conexões de skip (ou conexões de atalho).
Essas conexões entre o codificador e o decodificador ajudam a manter detalhes importantes, resultando em segmentações precisas.
As U-Nets são particularmente eficazes em tarefas onde é necessário saber exatamente "onde" estão determinados objetos dentro de uma imagem, como na detecção de tumores em imagens médicas ou na segmentação de estruturas geológicas em imagens de satélite.
Sua capacidade de combinar informações de diferentes escalas através das conexões de skip as torna altamente precisas em tarefas de segmentação.
Relação com Redes Difusoras
Recentemente, as redes difusoras surgiram como uma poderosa técnica para geração de imagens de alta qualidade e reconstrução de dados.
Em muitos aspectos, elas podem ser vistas como complementares às U-Nets, especialmente quando o objetivo é gerar ou modificar imagens complexas a partir de ruído.
As redes difusoras funcionam introduzindo ruído progressivamente em uma imagem e, em seguida, aprendendo a reverter esse processo de degradação para recuperar ou gerar uma imagem a partir de puro ruído.
Esse processo é conhecido como "difusão" e "desdifusão". As U-Nets muitas vezes são usadas como base na arquitetura das redes difusoras, pois sua estrutura de codificação e decodificação, juntamente com as conexões de skip, permite uma reconstrução eficiente da imagem enquanto preserva os detalhes importantes.
Na prática, as U-Nets, quando combinadas com redes difusoras, são capazes de produzir imagens de alta qualidade e detalhamento, aplicáveis a uma variedade de tarefas, como restauração de imagens antigas, criação de conteúdo visual ou até mesmo geração de arte digital a partir de ruído.
Physics-Informed Neural Networks (PINNs)
As Physics-Informed Neural Networks (PINNs) são uma classe especial de redes neurais que integram o conhecimento das equações que governam os fenômenos físicos diretamente no processo de aprendizado.
Ao contrário das redes neurais tradicionais, que dependem exclusivamente de dados para aprender padrões e fazer previsões, as PINNs utilizam as leis da física conhecidas, como equações diferenciais parciais (PDEs), para guiar o treinamento e melhorar a precisão do modelo, especialmente em problemas onde os dados são escassos ou ruidosos.
Um dos principais benefícios das PINNs é que elas permitem que o modelo aprenda não apenas a partir dos dados observados, mas também a partir das equações físicas que descrevem o comportamento do sistema.
Isso resulta em uma melhor generalização, pois a rede não precisa depender unicamente dos dados empíricos, mas pode ser orientada por restrições físicas que garantem que o modelo respeite a realidade do fenômeno.
Essa abordagem permite que as PINNs aprendam com menos dados, tornando-as ideais para problemas onde a coleta de dados é difícil ou cara.
Além disso, ao incorporar as equações que descrevem o sistema, as previsões da rede respeitam os princípios físicos, proporcionando maior confiança nos resultados e evitando inconsistências que poderiam ocorrer em redes baseadas apenas em dados.
Conclusão
Neste artigo, exploramos as principais arquiteturas de redes neurais, desde as mais simples, como as redes MLP, até as mais avançadas, como Transformers e PINNs.
Cada uma dessas arquiteturas tem seu lugar em diferentes tipos de problemas, e entender suas particularidades é essencial para aplicá-las de forma eficaz no mundo real.
Vimos como redes convolucionais, recorrentes, GANs e muitas outras arquiteturas permitem avanços incríveis em áreas que vão da visão computacional ao processamento de linguagem natural, incluindo a modelagem de fenômenos físicos. Com tanto potencial, o aprendizado profundo continua a abrir novas possibilidades.
Gostou do conteúdo? Fique ligado! Temos muito mais artigos e guias sobre redes neurais e aprendizado profundo preparados especialmente para você. Um abraço e até a próxima!
Créditos
- Conteúdo: Allan Segovia Spadini
- Produção técnica: Rodrigo Dias
- Produção didática: Cláudia Machado
- Designer gráfico: Alysson Manso
- Apoio: Rômulo Henrique
