Análise de dados: analisando minha distribuição com três alternativas de visualização


Escrevi sobre uma análise de dados inicial que fizemos de nossas notas na Alura, o que levou à decisão de utilizarmos uma normalização do NPS para nossos alunos e alunas. Já usamos o NPS tem muitos anos internamente portanto é possível analisarmos o histórico de nossos cursos através do uso dele.
Começando com os NPSs mais recentes do banco (usando pandas e uma conexão ao banco), mostramos os primeiros N elementos de um grupo de cursos que selecionei para analisarmos:
import pandas as pd
# ... abre a conexão ...
nps = pd.read_sql("select nps from __NPSRecent where /* periodo de tempo a ser analisado */;", conexao)
nps.head()
O NPS já é um tipo de medida agregadora e fica estranho calcular a média de NPSs portanto tentamos um plot simples, usando a função plot do próprio pandas. Somente pedimos pro histograma ser normalizado.
nps.hist(normed=True)
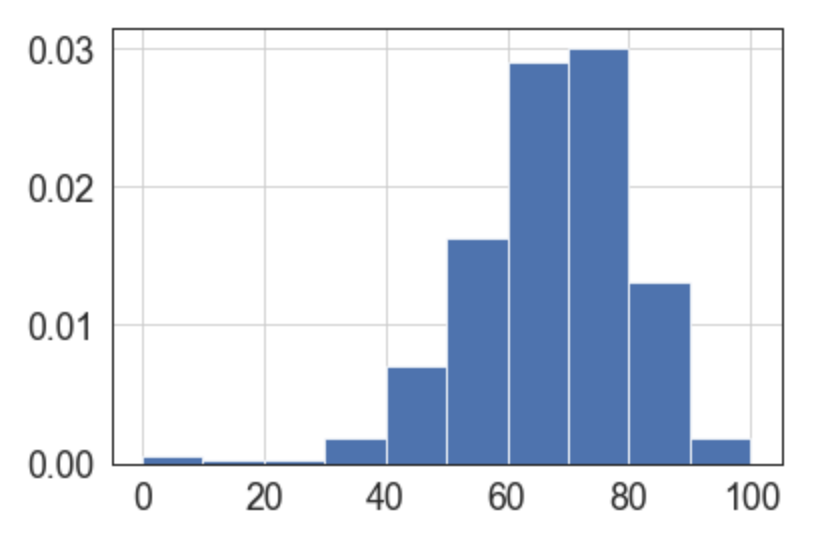
O gráfico é bonito e já mostra que o próprio NPS "melhorou" a nossa distribuição uma vez que nossa intenção é causar uma diferença mais forte entre os melhores cursos e os outros.
O pandas usa o matplotlib por trás dos panos e suas configurações são baixo nível. Outra ferramenta de gráficos conhecida é a seaborn, que utilizei no post anterior. Vamos importá-la e configurar para usar um tamanho de fonte e tipo de cores diferente:
import seaborn as sns
sns.set(color_codes=True)
sns.set_context("paper",font_scale=2)
sns.set_style("white")Agora baseado nos dados pedimos para postar nossa distribuição:
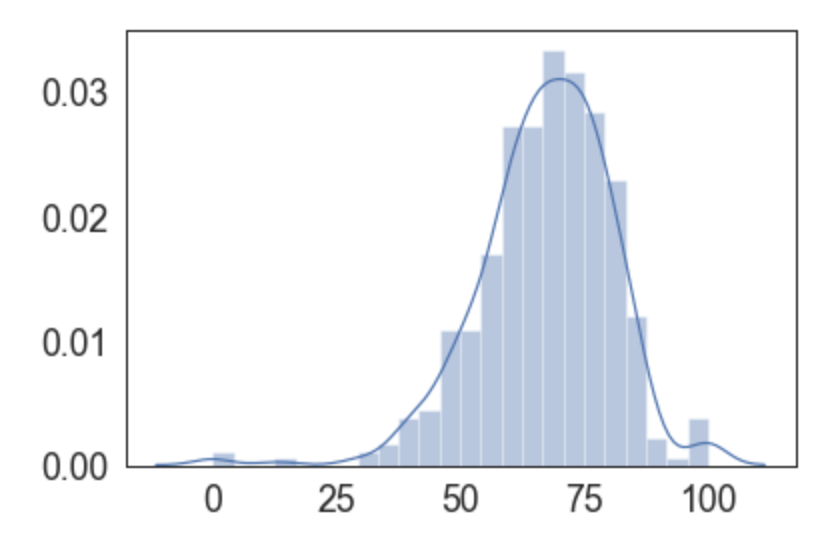
Note como seaborn define um gráfico como sendo de distribuição, isto é, já está pensando na intenção do gráfico, e não no tipo dele. Tanto que por padrão o gráfico de uma distribuição já plota o histograma (barras) e a aproximação de uma distribuição (o KDE).
É curioso notar a assimetria da distribuição, repara como o lado direito cai mais rapidamente. As caudas também tem pequenos "bumps". Será que nossa distribuição não se comporta como uma normal?
Mas estamos analisando um tipo de medida que se assemelha uma média, e a estatística clássica diz que tais médias (sob determinadas situações) distribuem como uma normal, o que será que está acontecendo com essas caudas?
Vamos pensar. É basicamente impossível tirar somente notas 10 ou 0 eternamente. Nada no mundo costuma ser perfeito, ainda mais nada no mundo costuma ser perfeito para os olhos de todo mundo que olha - ou estuda - aquele curso.
Em algum momento da história alguém vai dar uma nota que não é 10. Mesmo que seja 9.99, não será 10. Por isso é impossível a longo prazo manter uma nota 10, como discuti no post anterior. Ter somente nota 10 indica, portanto, uma de duas coisas:
o curso não teve alunos/as suficientes ainda, e não chegou alguém ainda que não foi tão fã do curso
houve uma filtragem prévia, expulsando quem não daria nota máxima
Portanto os cursos próximos ao 100 são na verdade cursos com poucos votos, que em um momento ou outro no futuro terão pelo menos uma nota 9. O mesmo vale para um curso que teve só duas avaliações, uma primeira nota 10 e depois nota 6: a fórmula para essas duas notas dá um NPS 0.
Um NPS 0 costuma indicar um produto ruim ou, como no nosso caso, simplemente que não teve alunos suficientes e foi azar de que a pessoa que daria nota 6 foi a segunda estudante do curso. (é possível analisar a distribuiçnao de notas possíveis e esperadas e entender o quão comum é o efeito das duas pontas, e é super comum, uma vez que o NPS esperado é alto).
Levando em conta esses pontos, é interessante considerar somente cursos com mais de, por exemplo, 50 notas, já fugindo dessas anomalias:
sql = """select nps from __NPSRecent where
total_de_votos >= 50
/* and periodo de tempo a ser analisado */;"""
nps = pd.read_sql(sql, conexao)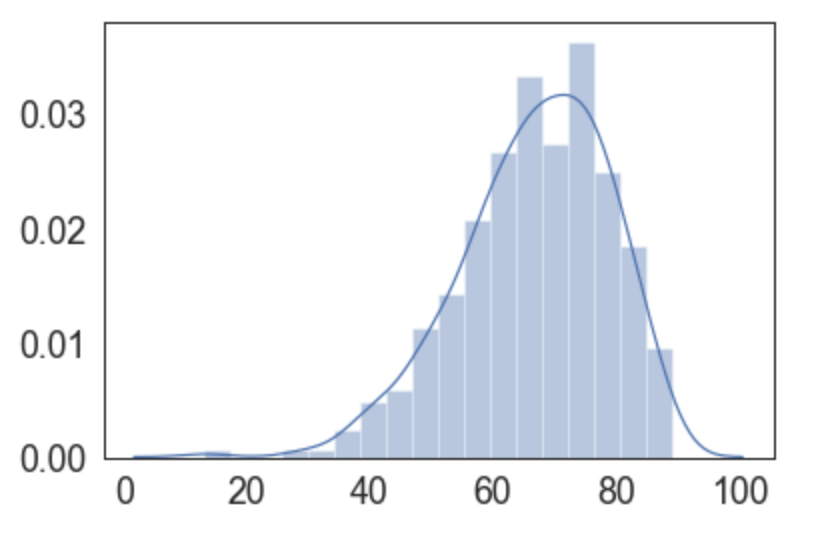
Agora o que precisamos é normalizar esses números de NPS (que vão de -100 a +100) e replotamos esses dados, já focados onde estão basicamente todas as notas normalizadas:
sns.distplot(sua_normalizacao(nps),
hist = True, norm_hist = True,
kde=False, hist_kws={"range": [7,9.5]})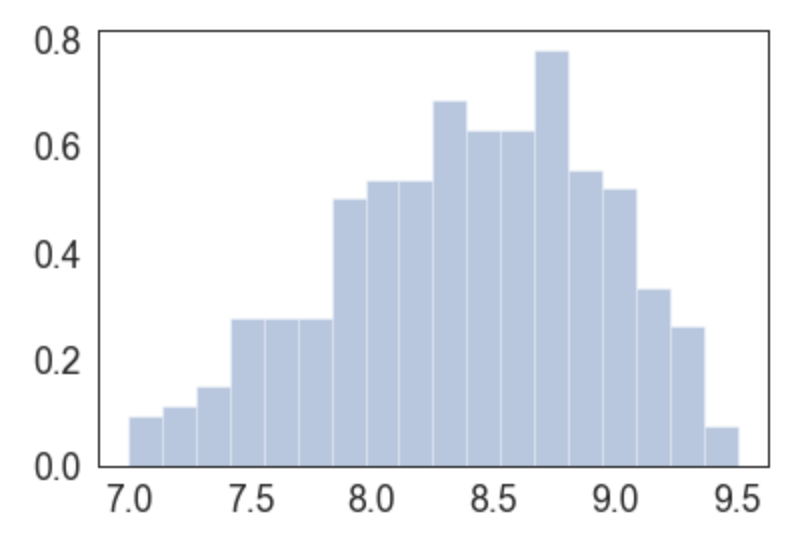
Note que com essa função de normalização que escolhi temos uma distribuição que coloca números mais próximos do que um aluno ou aluna espera. Fica mais visível que um curso de nps normalizado 9.5 foi melhor avaliado que um de 7.
Antes, essas notas estariam muito próximas. Toda manipulação matemática foi feita com o objetivo de distanciar os cursos uns dos outros, e abaixar nossas médias, por mais felizes que fiquemos com médias reais altas :)
O próximo passo? Usar outra biblioteca para plotar nosso histograma. Vamos testar agora a altair. Criamos um gráfico (chart) em cima de nossos dados nps e queremos desenhar barras (mark_bar).
import altair as alt
# alt.renderers.enable('notebook') # se usar o jupyter notebook
alt.Chart(nps).mark_bar().encode(
# ...
)O que colocaremos dentro do gráfico? No eixo x virá o campo nps que é uma variável quantitativa (Q), e vamos agrupar em 20 bins, como em um histograma. Já no eixo y usaremos a contagem de elementos em cada bin:
import altair as alt
# alt.renderers.enable('notebook') # se usar o jupyter notebook
alt.Chart(nps).mark_bar().encode(
alt.X('normalized:Q', bin=alt.BinParams(maxbins=20)),
alt.Y('count()'),
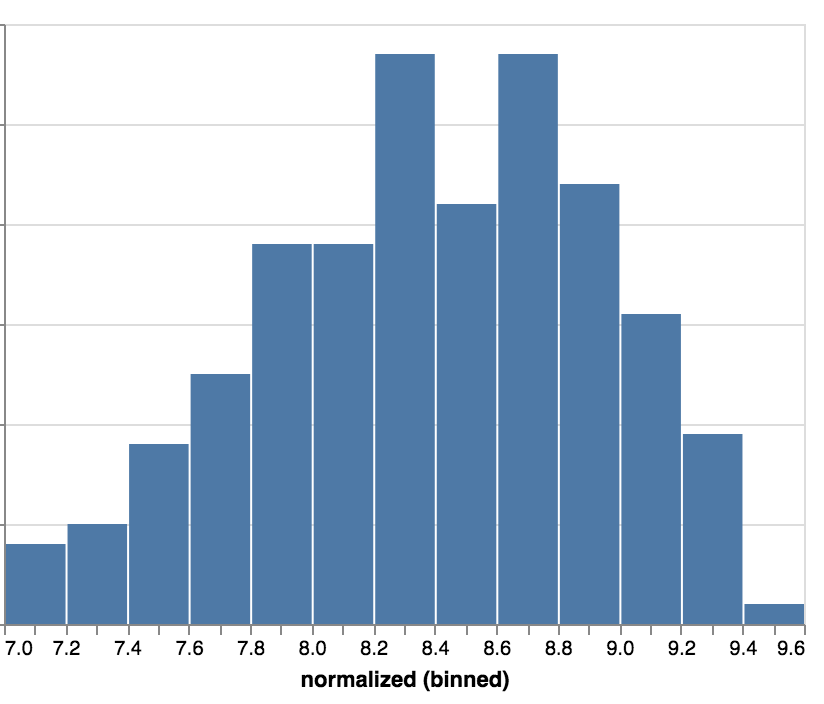
)Por fim, vamos dizer que estamos interessados no intervalo 7 a 9.6, cortando (clamp) o resto:
alt.Chart(nps).mark_bar().encode(
alt.X('normalized:Q',
bin=alt.BinParams(maxbins=20),
scale=alt.Scale(domain=[7, 9.6], clamp=True)),
alt.Y('count()'),
)
Repare que cada biblioteca ajudou de maneira diferente. Enquanto o matplotlib é a biblioteca baixo nível por trás desses gráficos, usei os gráficos direto do pandas para rapidamente plotar visualizações e esboços do que quero ver.
Por vezes uso o seaborn para visualizações intencionais. Claro que configurando o plot podemos gerar visualizações que já resolvem nosso objetivo. Mas às vezes a legibilidade do código do altair (declarativo) ajuda a manter o código a longo prazo.
Com essa abordagem e linha de pensamento chegamos a fórmula de normalização citada que utilizamos para distribuir "melhor" (melhor = notas mais espalhadas) as notas de nossos cursos. Na Alura temos diversos cursos que abordam a análise exploratória de dados.
